今天要來進新課程 Launching into Machine Learning ~
我們先來介紹一下這課程裡面有哪些章節,這次的課程一共有四章~
第一章節:
第二章節:
第三章節:
第四章節:
比較歷史的部分我會先跳過~
或者先只帶到與最近的ML模型重疊的知識部分
由於第一章介紹比較實驗,我們先從第二章開始吧~
第二章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
Introduction to Practical ML
Introduction
Supervised Learning
Supervised Learning
課程地圖
這一章節要來介紹實際的ML內容與ML的歷史,
我們主要會講到以下重點:
課程地圖
Supervised Learning 與 Unsupervised Learning 是兩種最常見的ML模型,也是兩種不同的ML演算法,
這裡我們先比較一下這兩種的差別。
這表格我自己聽完這堂課做的,有興趣看課程內容筆記再往下拉,有很多例子:
Supervised Learning(監督式學習) |
Unsupervised Learning(非監督式學習) |
|---|---|
| 有預設可能的答案(label),用「資料」做label的預測(學習目標) | 無預設可能的答案(label),通常是將「資料」做分組(分群),再來依據分佈的結果說明「發現(學習目標)」。 |
然後 Supervised Learning 可再細分兩種不同的model:
regression model(回歸模型) |
classification model(分類模型) |
|---|---|
| 預測的答案(label)為「連續」值 | 預測的答案(label)為「非連續」值 |
這裡有些中文比較細膩的地方,是我自己找資料的心得:
特別注意「分類」與「分群(分組)」的不同:
| 分類 | 分群(分組) |
|---|---|
| 你「會」知道那個「類」的名字,我們依照這個「類的準則」分類 | 你「不會」知道那個「群(組)」的名字,我們讓他們自己找相似的一組 |
| 例如:我有身高體重,我想預測是「男生女生」 | 例如:我有一堆人的資料,我想分看看這群人中有沒有哪一小群有相似的特性,可能都喜歡吃日式料理的一群、吃韓式料理的一群...... (注意這個「結果」是分完後才去解釋的,我們並不像男女分類一樣一開始就知道要「依照某個準則分類」) |
Supervised Learning(監督式學習) |
Unsupervised Learning(非監督式學習) |
以下課程就是有很多很多的例子......
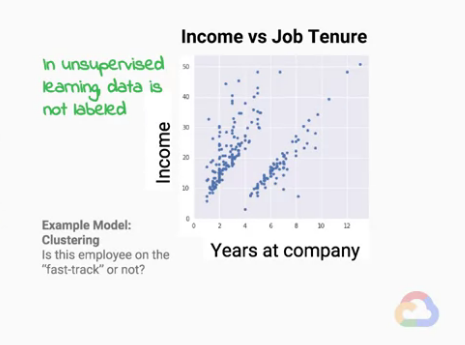
例圖:Unsupervised Learning 的例子
我們想透過這圖片了解的是 income(薪水) 和 tenure(年資) 之間的關係,
並對員工進行分組(分群),以了解是否有些人成長比較快速。
unsupervised問題有個很重要的特性在於「沒有一個基本的答案(結果)」。
以這個問題來說,對於所有的人而言,
我們不是一開始就知道他的薪水與年資是在比較快還是比較慢成長的,
我們是在分析結果後才發現所有人的分布呈現如上圖,「看到圖片時」才知道有兩大分佈。
特別留意順序:先看到圖片分佈,才知道有人屬於比較快的、有人屬於比較慢的(也是這時才定義結果)。
因此,unsupervised問題最主要是在解「發現」的問題,
我們想知道「所有的數據」能不能「被分出組別」來。
同樣的我們也來看一下 supervised問題,
supervised問題重要的特性在於「我們有預設的答案(label)」。
而 supervised Learning 能預測的問題答案有兩種模型:
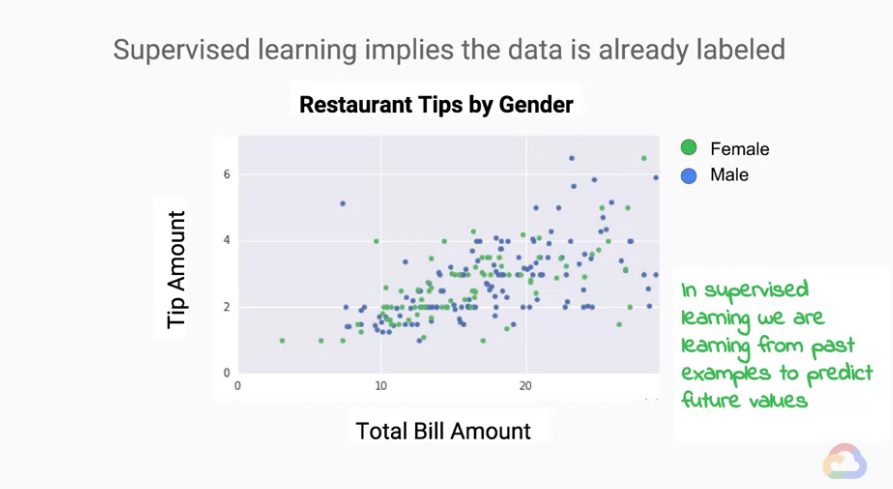
regression model : 預測的答案為「連續」值。classification model : 預測的答案為「不連續」值。例圖:supervised Learning 的例子
我們想透過這圖片了解的是 Bill(帳單) 和 Tips(小費) 之間的關係,
來看看我們能不能從一些跡象預測 Tips(小費) 是多少?
我們先將上方的資料表格化一下:
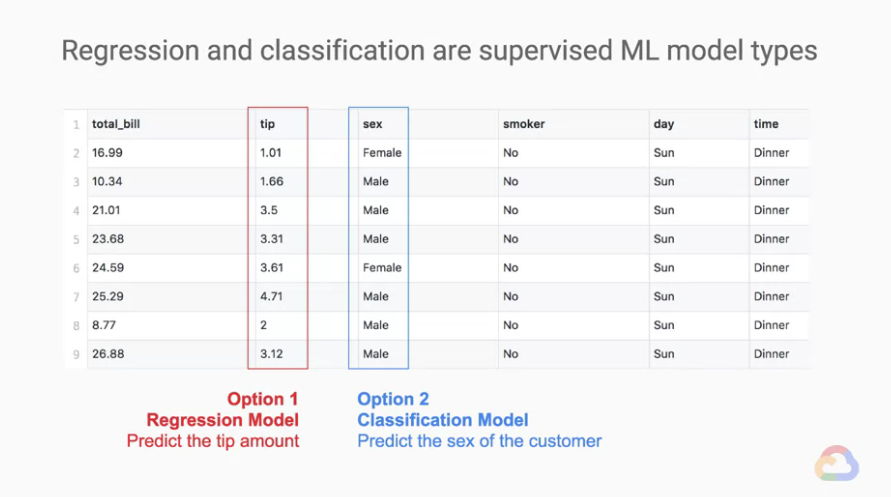
※名詞解釋:
example: 每一橫行各代表一個example。label: 任何一個直行,表示我們想預測的目標。features: 除了label外的其他直行,我們參考這些數據來預測label。
回到剛剛的問題,我們想要預測 Tips(小費) 是多少?
預測的目標(label)就是「Tips(小費)」的那個直行features
regression model。我們可以使用一行或多行的
features試著去推測出label。
在 supervised Learning 中,要使用多少features去預測label並沒有數量上的限制。
我們以同樣的問題來看另外一個例子,如果今天我們想預測是「顧客的性別」呢?
預測的目標(label)就是「顧客的性別(sex)」的那個直行features
classification model。同樣的,我們可以使用一行或多行的
features試著去推測出label。
一樣要使用多少features去預測label並沒有數量上的限制。
這邊我們再練習個幾題,確認大家到目前的觀念是清楚的:
狗的種類為非連續值,使用
classification model
狗的品種是我們的預測目標,為label
其他狗的相關特徵都可以作為我們預測結果前的參考資料,為features
狗的體重為連續值,使用
regression model
狗的體重是我們的預測目標,為label
其他狗的相關特徵都可以作為我們預測結果前的參考資料,為features
另外我們舉個特別的例子,例如現在有間銀行想要預測交易是否是詐騙,我們可以怎麼做?
很直覺的我們應該會想,不就只是分成兩類? 「詐騙交易」與「非詐騙交易」嗎?
確實如此,但在現實中會有些問題,例如我們如何「絕對的」從我們的分析肯定一定是詐騙交易?
他可能符合某些feature與example相似,但也有些不相似,這樣就會有誤判的可能。
所以我們還是會發現有些特別的case會因為我們訓練的限制而陷入模稜兩可的狀況。
我們的模型會需要蒐集更多的資料來判斷這種目前可能會模稜兩可的問題,
因此在前面課程中的所提到的 human in the loop 的概念這時顯得十分重要,
更多資料就能夠幫助我們分辨更多這些介於模稜兩可之間的分類問題。
coursera - Launching into Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉