假設您有一個適用於所有用戶的模型,無論他們是誰或來自哪裡。
理想情況下,所有符合我們模型生成的理想結果的用戶應該在所有用戶中獲得正確分類以獲得理想結果的平等機會。 [來自課程內容]
機會均等是什麼呢?具個例子
我們正在為一家銀行工作,我們正在構建機器學習模型,
以幫助確定是否批准貸款。在這種背景下,什麼是機會均等?理想情況下,所有有資格獲得貸款的用戶在所有用戶中都有相同的機會被正確分類以獲得該貸款批准。
換句話說,一個人有資格獲得貸款的機會應該是相同的,無論他們屬於哪個受保護的子群體。
所以,我們在這裡看到的是,如果你保持一個人的一切都相同,並將他們從一個子組的成員改為另一個子組,
那麼他們獲得貸款資格的機會應該保持不變。那麼,為什麼要將這種方法融入機器學習系統?[來自課程內容]
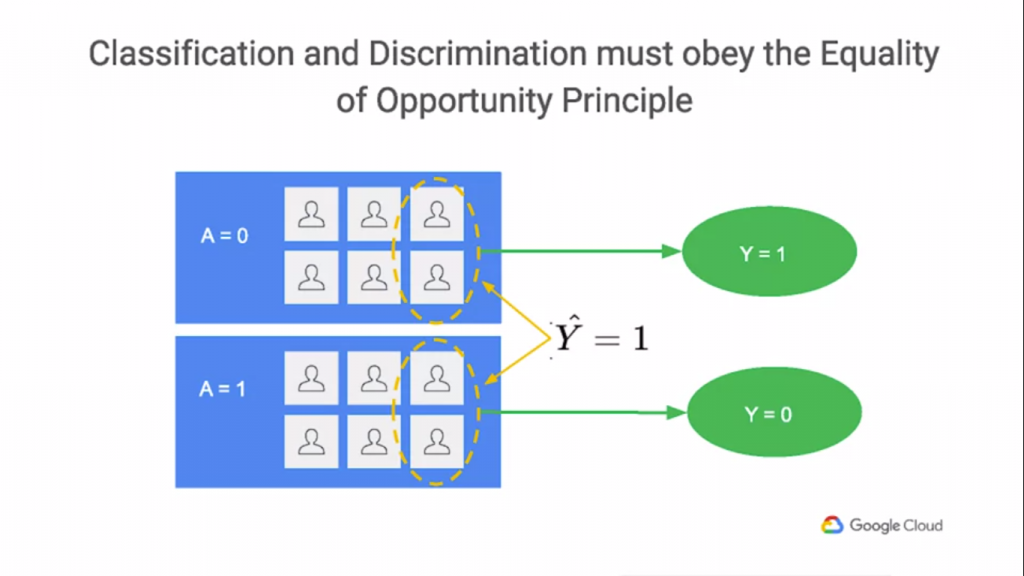
上圖表示了課程內容,不管是在群集Y1還是Y2,可以看到能獲得貸款的機率都是一樣的(六個其中有兩個可以獲得貸款),那麼這樣子的方法又為何要融入ML Model呢?如果是普通的ML,結果只會有"可以貸款"或"不能貸款"給該客戶,
兩個選項而已啊!為何還要融入機會均等這個方法?讓我們繼續看下去~
因為像這樣的方法可以讓你仔細檢查你的模型,以便發現可能的關注領域。一旦確定了改進的機會,
您現在可以進行必要的調整,以在準確性和非歧視性之間取得更好的權衡,從而使您的機器學習模型更具包容性。
現在讓我們使用玩具分類器來說明這種方法,這不是一個真實的模型,它只是解釋這些概念的合成例子。
該模型的目的是高精度地預測誰將償還貸款,然後銀行可以使用該模型來幫助決定是否向申請人提供貸款。
因此,在您看到的圖表中,黑點表示償還貸款的人,而光點則表示不支付貸款的人。第一行的數字代表信用評分,
簡化為0到100的範圍,其中較高的分數表示償還貸款的可能性較高。在理想的世界中,我們將使用清晰分離類別的統計數據,
如左側示例中所示。不幸的是,在群組重疊的右側看情況更為常見。
現在,像信用評分這樣的單一統計數據可以代表許多不同的變量。
您將在本專業化的後面看到,大多數機器學習模型都會返回概率,因此此處的信用評分可以代表該概率。
例如,信用評分等機器學習模型產生的概率,包括收入,支付債務的來源等很多因素。
因此,該數字實際上可能代表一個人償還貸款或違約的可能性。但它也可能沒有。
這就是設置閾值的想法可以進入的地方。基本上,你選擇一個特定的截止點,信用評分低於它的人被拒絕貸款,
而高於它的人被授予貸款。正如您在此圖中所看到的,選擇閾值需要進行一些權衡。
太低了,你可能會在違約時提供更多的貸款,而且很多人應該獲得貸款。那麼,最好的門檻是多少?[來自課程內容]
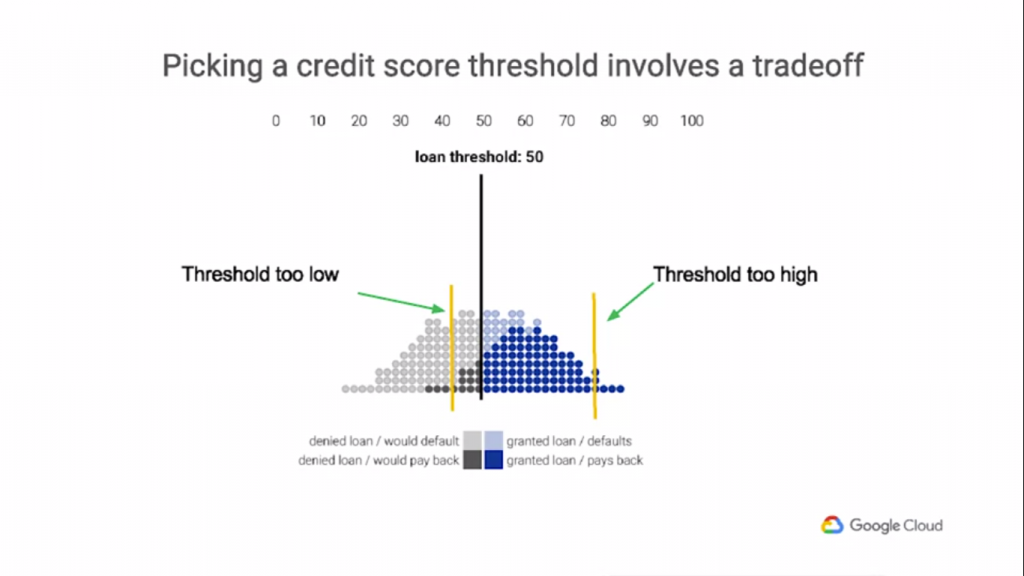
上圖的例子看懂了嗎?那兩條黃線就是我們得決定的值,一條取得太低,另外一條則是取的太高,
取得太低使的信用評分較低的人可以拿到貸款,但是會還錢的人都可以貸到款(藍點皆在黃線右邊),
相反的取得太高雖然不會還款的人都貸不到款,可是一部份會還款的人就帶不到款了(最大化正確決策的數量,見下圖[該圖是上圖取右邊黃色閥值的結果]),
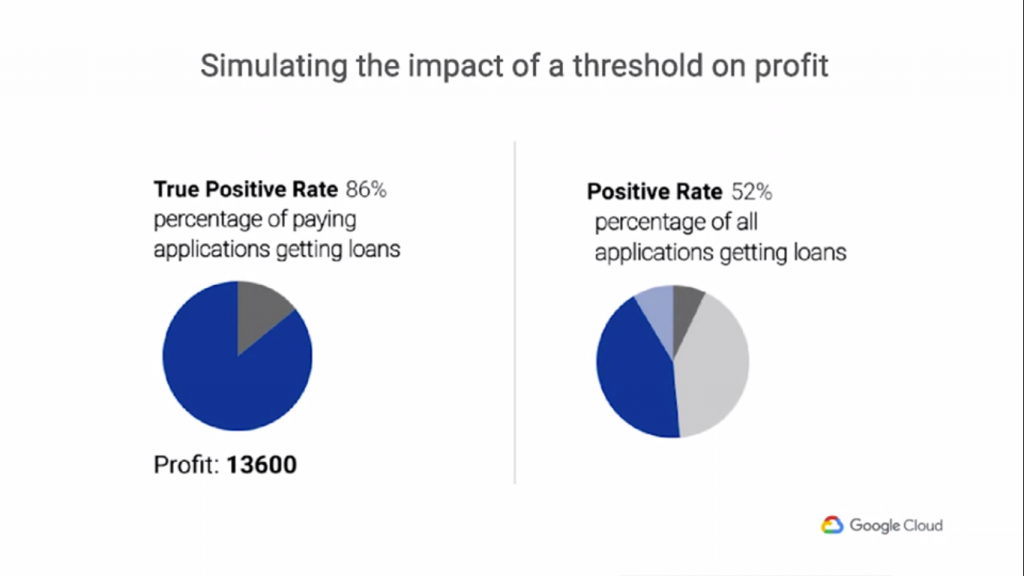
閥值的取捨非常重要!那麼如何決定閥值呢?在這個例子裡我們是銀行,當然以最大化利潤為前提來設定閥值!
所以,你可能不希望所有的決定都是一樣的。因此,財務狀況的另一個目標可能是最大化不是正確決策的數量,
而是整體利潤。您在此處看到的底部圖表表示基於我們對每筆貸款相關利潤估算的假設利潤。那麼,問題就變成了,
最有利可圖的閾值是什麼,它是否與最正確決策的閾值相匹配?當像信用評分這樣的統計數據最終在兩個組之間分配不同時,
這些問題變得特別棘手。這就是機會均等的基礎。機會均等的正式設置看起來像這樣。[來自課程內容]
你也有一個我們稱之為Y的二元結果,我們可以將Y的值等於1作為理想的結果。在這種情況下,接受貸款。在這個例子中考慮Y作為你的基本事實或標籤,但我們正在建立一個Y的模型。在我們的示例中,
預測變量始終是使用0到1之間的分數定義的閾值。預測器可以使用依賴於A的閾值,其中我們可以針對不同的組使用不同的閾值。因此,這裡的想法是A中有資格獲得積極結果的個體應該具有與不在A中的個體相同的機會進行正面分類。
更正式地說,這種願望與兩者中的相同真實陽性率相吻合,這就是機會均等背後的原則。[來自課程內容]
這就是機會均等在Machine Learning的應用,抱歉引用很多課程內容,因為我也想不出例子來解釋機會均等XD
就直接拿課程內容來舉例了,利用機會均等原則,來設定閥值,來將你的Model更符合現實情況(在上圖的例子就是最大化利潤)。
-下禮拜會進入一點實作啦~歡呼吧各位!(順帶一提第二章會帶到很多ML背景知識[不像這裡偏ML應用這樣]耶~)


 iThome鐵人賽
iThome鐵人賽