在訓練Machine Learning Model時,我們的Model一定會出錯,
而錯誤又分成兩類,在優化錯誤時應該要想,我們的錯誤要往哪方面優化,才會對使用者受到的影響降到最低。
Confused Matrix是一個很好的方法來分析Model的錯誤情況。
上圖可以看到Model出錯的面相有兩個,一個是理應輸出True的輸入卻輸出了False的答案(False Negative)
而另一個則是理應輸出False的輸入卻輸出了True(False Positive),而不同的Model在對這兩者錯誤應該要怎麼優化
有不同的答案(當然,如果能同時降地兩者的錯誤率就好了,不過現實總是不會那麼簡單。)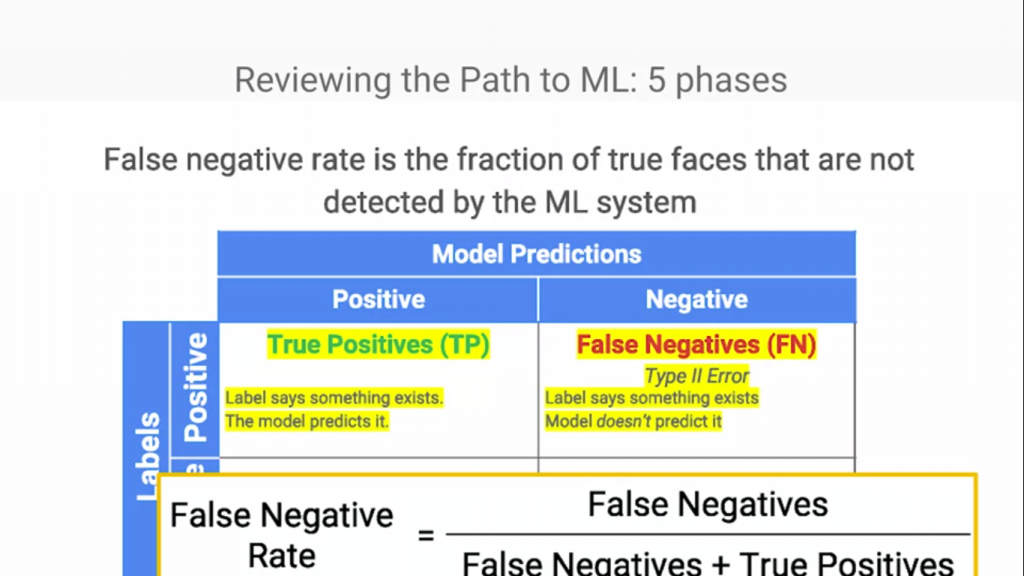
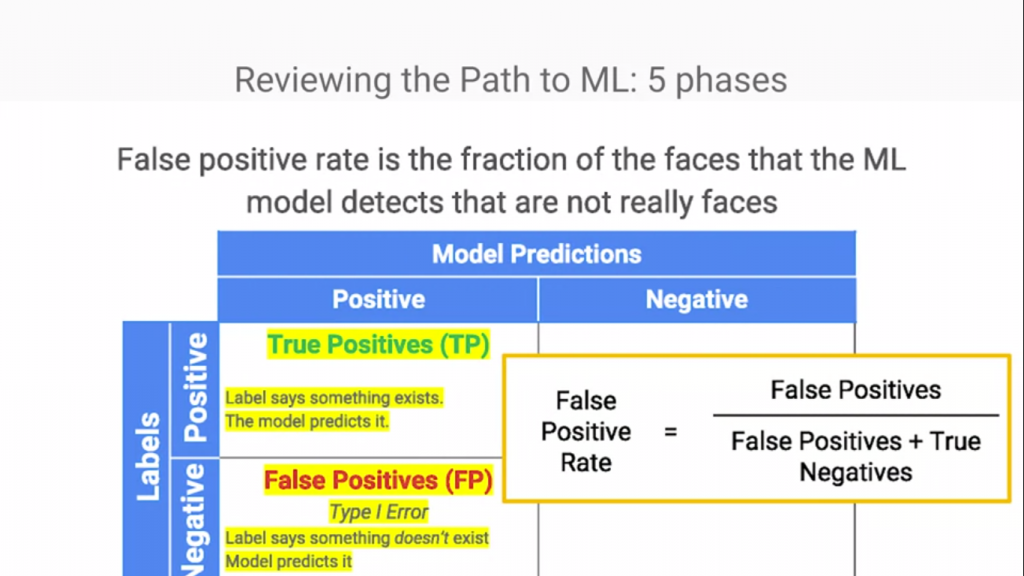
上面兩張圖分別在講兩個錯誤的錯誤率計算,那麼問題來囉?
要如何根據Model的功能,選擇降低哪一種錯誤率?
讓我們來看看吧,上圖是檢測照片是否有私人個資的Model,
可以看到右邊的圖有私人個資的圖被Model誤判成沒有個資的圖片,而左邊沒有個資的圖也被誤判成了有個資的圖片,
在這種情況下,很明顯的,如果Model出了右邊的圖的錯誤的話,極有可能讓這張有個資的圖外洩(因為他被標繼承沒有個資的圖了),那麼這種情況我們就得選擇要降低右邊這種錯誤(False Negative)的錯誤率。
根據不同的Model會有不同的優化傾向,而利用Confused Matrix來分析Model的錯誤是一個很好的方法。

