前言:
本系列文基於Coursera上Google開設之課程編寫而成,主要針對ML(機器學習)基本概念與Tensorflow做基本介紹。希望能對於初入機器學習的朋友能有幫助!
在第一周當中,我們會簡單介紹監督式學習以及機器學習的歷史進展,讓大家對於機器學習的發展有基礎的認識。後面會再介紹機器學習之最佳化(Optimization),了解一個好的模型是如何形成的。現在讓我們開始第一天的內容吧!
監督式學習(supervised learning)為機器學習的主要分支之一。機器學習可簡單區分為監督式學習以及非監督式學習。
兩者最主要的區別在於,在機器學習中,我們的數據會擁有標籤(label),也就是已知的答案。就像是拿著有答案的考卷讓學生回去念,看看他們能不能在新的考卷中得高分。而相對地,非監督式學習就是數據中沒有標籤,也就是沒有已知的答案。
我們來舉一個例子,下圖是工作年資(Job tenure)以及收入(Income)的散佈圖(scatter plot),我們希望在其中找出年資與收入的關係,並觀察是否有人晉升加薪得比較快。我們希望將資料分成快速以及一般組,但原始資料中是混雜的,並沒有給我們標籤,因此這個案例是屬於非監督式學習。此外,本題為一個分類(classification)問題。
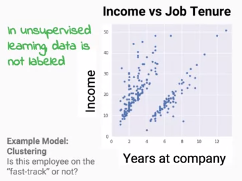
但在本文中我們會著重在監督式學習,請看下面例子: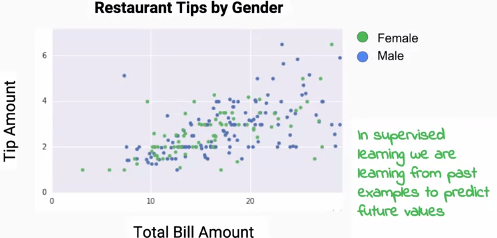
在這張表中,我們可以看到帳單的金額以及小費的數目。現在假設我們想知道坐在角落的那組客人會給多少小費,但我們手中只有該客人帳單的金額,我們就能利用監督式學習來進行預測。此模型中,小費的數目即是我們的標籤。而這個問題將是一個回歸(regression)問題。
現在假設我們想要預測客戶的性別,我們便可將客戶性別作為我們的標籤,我們將其他的數據做為特徵(feature)來進行預測。而這個問題則是一個二元分類(binary classification)問題。
在前面的範例問題中,我們可以發現監督學習需要有標籤的資料。倘若沒有標籤則無法進行預測,也就不稱之為監督式學習,我們可能就必須使用其他方法(如分群cluster)來觀察數據。在常見機器學習能回答的問題中,主要能分成兩種問題,回歸以及分類。假設我們想透過一組資料來預測一隻狗的品種,這就是一個分類問題,因為我們的標籤以及預測目標是離散的(discrete)。若是我們想透過資料來預測狗的重量,則此為一個回歸問題,因為體重是連續的(continuous)。這樣是不是很簡單呢?
倘若我們要預測一筆信用卡交易是不是盜刷,我們可以知道這是一個分類問題,而且是二元的。但實務上會有第三類,所謂的灰色地帶,也就是AI或是ML模型無法確定的(uncertain)。這時就必須要透過人工介入再進行判讀跟確認。在ML的真實世界運用中,導入人工通常是非常重要的一環。對於想要透過AI來完成全自動化的我們聽起來是不是很奇怪?但導入人工能夠進行二次確認並且避免重大疏失產生,或是透過其他方式來對模型難以辨認的分類進行正確的分類,這樣才能讓ML在實務場景的效益最大化。
說了很多,剛剛提到了信用卡盜刷模型預測,最近AI吧也有一個相關比賽,有興趣的可以參考看看:
AI實戰吧-信用卡盜刷偵測
若是覺得本文有幫助,歡迎點選Like、星星收藏或是追蹤系列文支持哦!


 iThome鐵人賽
iThome鐵人賽