在前面一直提到我們得到的 PTT 文章都是文字呈現,那怎麼讓電腦也看得懂呢?因為最終的計算是個兩類別的分類問題,所以這邊我們把所有的文章轉成數值,也就是每一篇文章就是一個向量。
要將文字轉成向量的方式很多,在 Data Mining 或 Text Retrieval 的領域最常見的方式就是 TF-IDF (term frequency–inverse document frequency) 的方式。但由於我們使用的文章數每篇文章的字詞數不定,且並非有完整的結構寫法,且加上文章數量過多,所以不適合使用 TF-IDF 方式來做文字轉數值的方式。
另外一個常見的方式為 vector space model 也稱為 one-hot encoding,這個方法是使用 N 位狀態暫存器來對 N 個狀態進行編碼,也就是每個字詞會有一個自己的向量值來表現,但 .. 只表現出存在不存在的意思,我們直接用一張圖來說明:
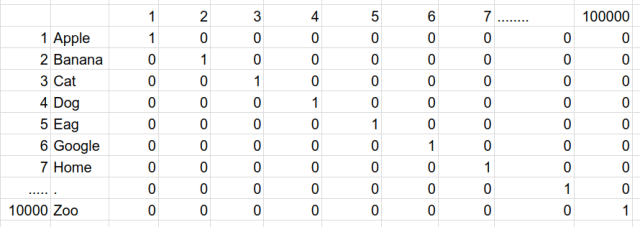
one-hot encoding (來源: https://androidkt.com/pre-trained-word-embedding-tensorflow-using-estimator-api/)
每個字詞用一個向量值表示,且每個字詞有自己的向量位置,出現此字詞該向量位置就為 1 其餘為 0。文章內全部總共有 10,000 個字詞 (N維),例如 Apple 這個詞的向量值就為 [1,0,0 … N],而 Banana 的向量為 [0,1,0 … N],依此類推。這方式雖然每個字詞都可以轉換為一個向量值去計算,但看得出來這是一個稀疏矩陣,之後要運算時會非常耗費資源。
為了改善以上兩個提到的編碼方式,現在越來越多人使用 word embedding 的方式來進行編碼 (詳細的做法就留到下一篇再說)。
之後我們會把文章利用 word embeeding 的方式編碼成固定維度的向量值,也為了之後方便計算,處理好的向量值會再轉為 arff 格式。講到 arff 格式,如果你曾經自己操作過分類問題,應該猜得出之後我們會用 Weka 來跑分類計算了吧 ?
ARFF格式
ARFF代表Attribute-Relation File Format(屬性-關係檔案格式)。
該檔案是ASCII文字檔案,描述共享一組屬性結構的例項列表,由獨立且無序的例項組成,是Weka表示資料集的標準方法,ARFF不涉及例項之間的關係。
最常見的 arff 格式的資料可以到 UCI 的網站下載,裡面有各式各樣類型的資料,在 machine learning 領域一定都會到這裡下載資料玩玩。
https://archive.ics.uci.edu/ml/datasets/SCADI
下一篇文章我們再來詳細說明將文字經過 word embedding 編碼後再轉成 arff 格式的方式。
免責聲明:本文章提到的股市指數與說明皆為他人撰寫文章內容,包括:選股條件,買入條件,賣出條件和風險控制參數,只適用於文章內的解釋與說明,此提示及建議內容僅供參考之用,並不構成投資研究、認購、招攬或邀約任何人士投資任何投資產品或交易策略,亦不應視為投資建議。


 iThome鐵人賽
iThome鐵人賽