下載下來的資料集好像副檔名怪怪的,所以我改成了.csv檔,(附上檔案)
https://drive.google.com/file/d/1GNfU_ciyFYp0YiotYHaXEKdfO9ML_qML/view?usp=sharing
library(tidyverse)
#我希望每個用R的人一定要載這個packages
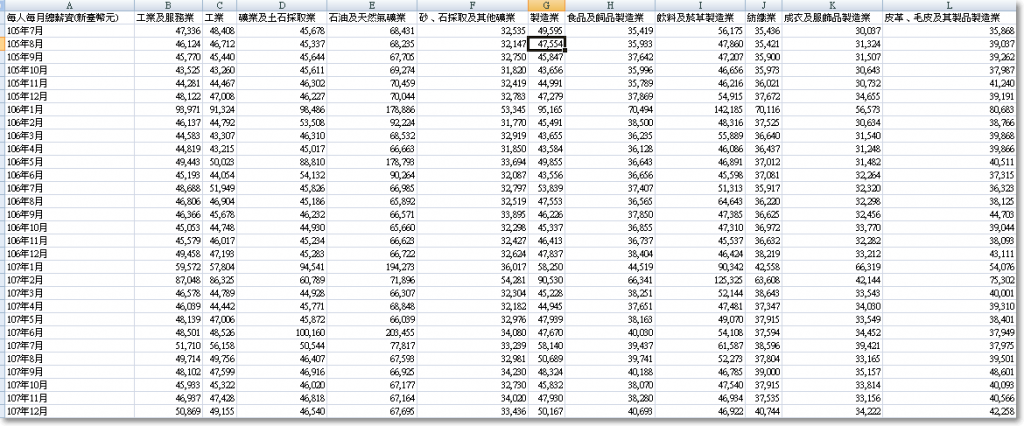
x = read.table("clipboard",header = T , sep = '\t')
for(i in 2:nrow(x))
x[,i] = gsub(",","",x[,i]) %>% as.numeric()
#因為讀進來的資料是12,345 有","無法被判別為數值型態(認為你是文字便無進行計算)
#所以用取代(gsub)的方式取代成為""空,然後再轉成數值型態
#使用%>% 的方式可以更適合閱讀(先後步驟明確,然後不容易因為框號多打或少打造成不必要的bug
options(scipen = 100)#畫圖的時候軸的數字會被紀錄成科學符號,這行可以展開科學符號
x
x1 = apply(x[,2:nrow(x)],2,mean)
#
x2 = x1[order(x1)]
#排序
plot(x2)
#作圖
可以看出第一名與最後一名近年來的平均收入差了足足一倍之多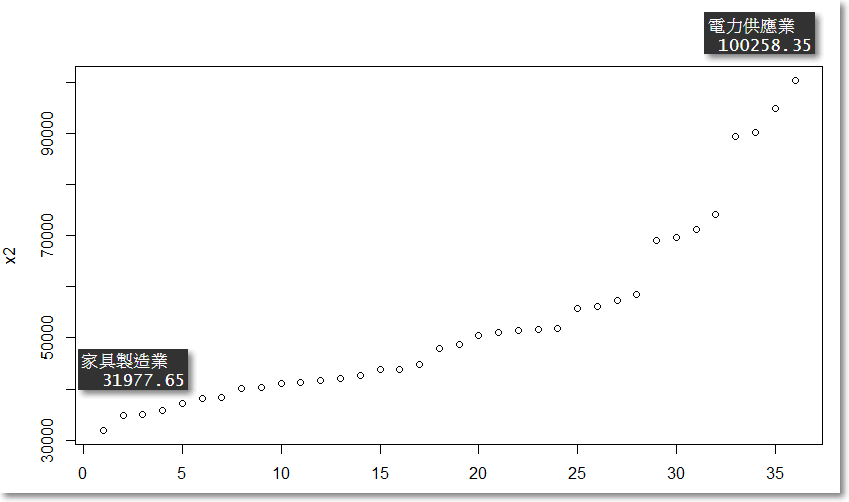
然後我滿推薦這款picpick的製圖軟件的,有點像小畫家,方便隨時螢幕截圖然後上一點簡單的特效。
對不起。


 iThome鐵人賽
iThome鐵人賽