
今天沒有前言,想到在補
這章節將帶入一些新的東西(廢話X
能夠帶來解決新問題的方式,看下圖:
上述圖中有甚麼?舊金山的日本玩具,kissimmee的活龍蝦
附近的素食甜甜圈和pasadena的蜂巢(不懂?
當我們在Google搜尋這些東西的時候,你可能認為這些搜索看起來沒什麼特別
事實上,問題可大了,這種搜索方式我們稱之為hard queries,local queries我指的是這個搜索的方式
意思是人們並不是在Google搜尋網站,而是在地圖上找商家,Google在前幾年看到這個問題,而且這些類型的搜索方式正逐漸普及,我們或許可以針對每個搜索目標編寫規則,好讓人們找到他們,不過相對的,這會讓你的機器變得"笨拙"
所以我們來看看機器學習ML會如何解決問題,看下圖: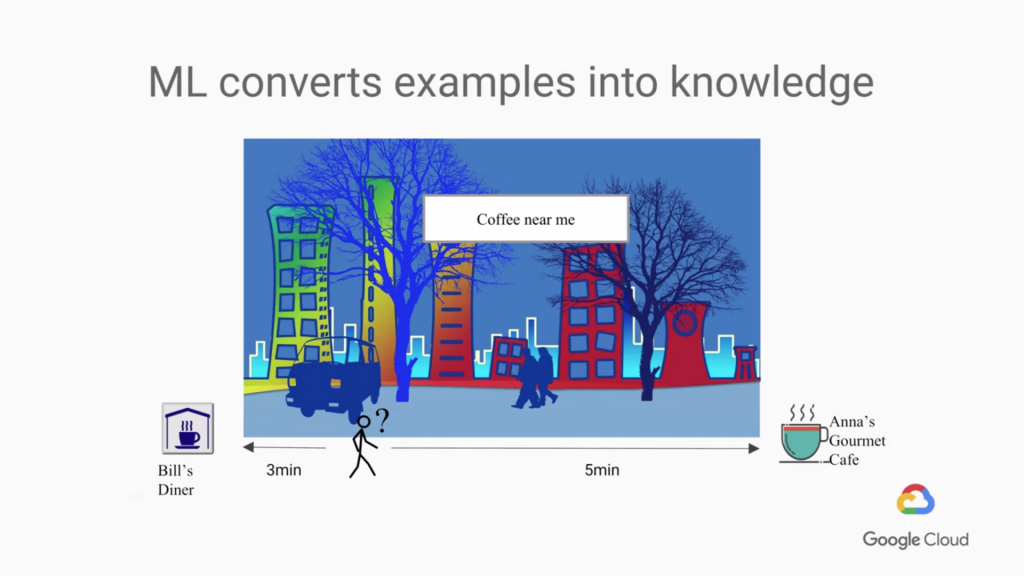
好了,現在有個人搜尋了附近的咖啡店
這裡出現兩個選擇,Bill's dinner 或者是 Anna's Gourmet Cafe
試想ML會如何思考,讓最後的結果是最終的預測結果
前面提到ML的兩個階段,先是訓練在來是預測
要訓練就要先有資料,有資料才能針對問題提出預測 那麼ML怎麼蒐集資料?
然後,所以,舉例來說,當你提出"附近的咖啡"時,哪些知識已經成為未來的預測了?.
我的意思是 甚至是你的key word中,也是數據的一部分。
那未來的預測是甚麼?很簡單,未來的預測就是兩家咖啡店的其中一家。
所以問題又回到了根本,ML到底怎麼蒐集數據。。
嘿!聽著!!我這裡要告訴你一件重要的事情,記住。
ML背後的想法就是"蒐集一大堆例子,使這些例子變為知識並做未來的預測",
所以回來,其實當你搜索附近的咖啡時,我們這樣想,
Bill's dinner有提供咖啡,而且只需3分鐘路程,
但是還有另一家咖啡店,只需2分鐘路程,
但是比起三明治,我們覺得您可能更喜歡咖啡店,
可是咖啡店必須過橋,我們可能送您餐廳,
可是如果餐廳低時至少要10分鐘以上才能上咖啡或者沒有外帶咖啡這個選項,
或者散步15分鐘是需要的。多遠算遠?餐廳評價等級多高?服務時間的快慢?這些有多重要??
當然,ML絕對不會將所有例子寫成一個一個規則,我指的就是if if if if if if if if
所以,我們希望,與其我們自己在這裡猜測
能讓用戶自己告訴我們,讓我們能夠用大量數據做權衡評估預測
B U T !!!
我們仍然需要數據所以一開始還是採用啟發式的方式等到數據資料充足後,我們就會拋棄啟發式的方式轉為大量數據權衡評估
我們需要的是更多的示例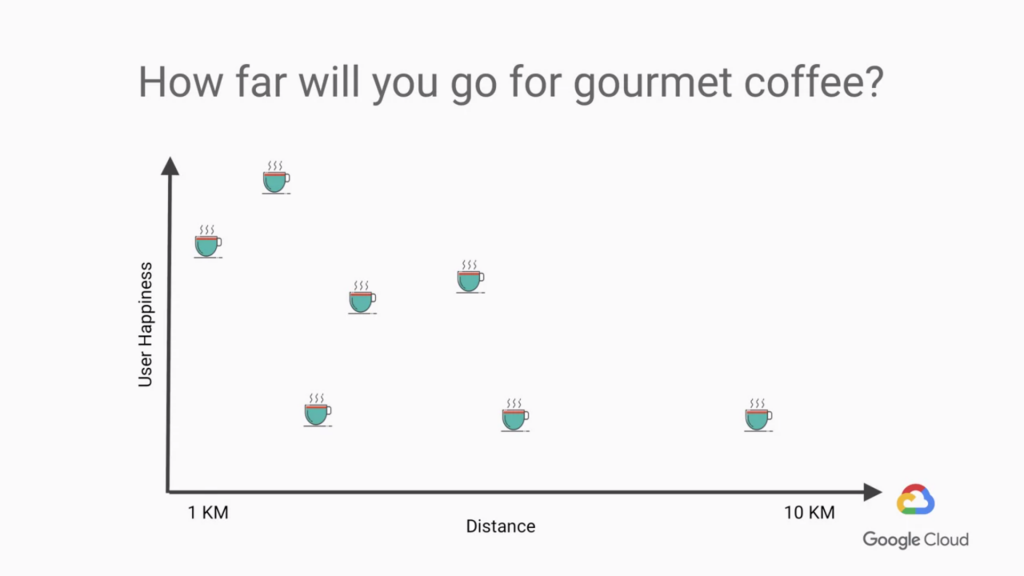
所以我講很多遍了哈哈E
我們還是需要數據,但這次差別在我們或許只先考慮距離對上咖啡品質 或是咖啡品質對上服務時間來討論客戶喜歡還是不喜歡兩種結果
從下圖很直觀的就可以看出
一開始客戶還願意去一公里的咖啡店喝咖啡
但是距離漸漸超過3公里時 客戶甚至連咖啡都不喝了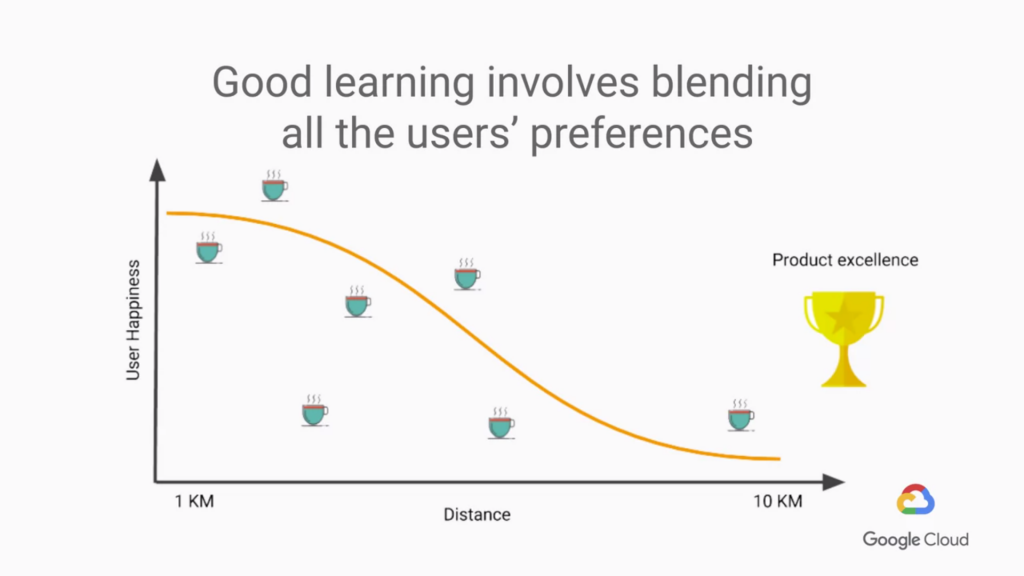
聽起來沒錯吧 你距離越遠就越沒有人想要去
ML學習 越多的數據 提出的答案會更接近最後的結果
越多的示例,越能在其中找到適當的平衡,精準預測
當然同時考量到 變數越多時 顧及模型全域範圍
並且適當收集數據 最重要的事
如何在良好的學習和信任示例之間找到適合的平衡!
這個章節教的是,當面對真正的問題時如何應用ML在其中
ML轉換成實務上的運用,大概是這樣的一個思考方向
第一個框架 關於如何應用在ML上
1.你正在預測什麼
2.你可能需要什麼樣的數據 再來
第二個框架 關於軟體和ML問題的協調
3.你可能需要哪些API來幫助整理你的數據
4.你的服務對像是誰 他們今天如何
第三個框架 關於收集數據
5.然後把這些問題放到數據問題的框架中 收集資料分析數據 預測並做相對應的結果
影片中還提到 不同的輸入可能需要不同類型的操作
下面有兩張圖片 可以試著思考看看 哪些問題可以用ML來嘗試解決 不管是在各行各業中。

接續上一節的思考方向
假設今天你要生產一個電話的顯示面板 首先決定你的預測的東西是什麼 預測東西是你應該製造多少個是英吋和6英吋的面板 接著 你需要什麼數據 這就牽扯到這個東西賣得好不好的問題了 你可能需要他的商品販賣數據 他賣出的多寡 他的價錢 包括客戶退貨的數據 同樣的 不只有我們一家公司在生產面板 我們可能會有競爭對手 那我們就需要更多數據 等等
第二個部分 我們要先搞清楚我們的服務對象是誰 而且這是他們需求預測的事情 所以我們假設我們的服務對象可能是 產品經理物流經理 他們可能研究電話銷售的趨勢 整體的經濟 貿易的出版物 等等
第三部分是為數據 我們為了進行預測 我們需要收集什麼數據 並且盡可能地用到所有的數據 我可能需要收集 我們可能需要收集經濟的數據 競爭對手的數據 同行的數據 公司本身的書局 我們可能需要很多數據 我們分析這些數據 並從數據中得知哪些是需求取向 我們把這些數據當作 模型的輸入 我們要做什麼反應 今天你知道了市場的需求 當然是搶先其他人 搶先 市場 所以 當預測結果出來的時候 我們自動向供應商發出訂單 我們就可以早一步取得先機 所以 這個整個過程很可能是自動化的 對吧
不知道前面有沒有說過 我們使用機器學習一個簡單的方法是 我們可以用別人預先訓練好的模型 這樣就不用多花時間在訓練模型上面 這邊有1個例子 Aucent 這家公司是日本最大的汽車拍賣 服務 在早期 如果要拍賣車子 你必須拍很多張照片 然後經銷商 還要比對你的汽車型號跟雜七雜八的 東西 非常繁瑣又複雜
對經銷商來說 每天要處理好幾千張的照片 非常耗時的事情 但是現在 利用機器學習 系統 只要將圖片上傳 系統字型會分類圖片的類別 自動檢測汽車的型號 順便幫你估計出車子的售價範圍 經銷商只需要 確認系統是否正確分類 大大提升了 行政的效率
這是 使用機器學習後 效率 他們自動比對車子的照片 當你嘗試拍攝一台汽車的正確角度時 他就會自動幫你比對 最符合的答案 而且第一名的 準確率竟然高達96 % 相對於以往返數複雜的程序 相對於往返數複雜的程序 上傳一張照片來得簡單多了吧
上一節提到的 Aucent 使用左邊的 開放式自定義模型訓練 但是我們不一定要這麼做 可以 直接 使用別人預先訓練好的模型 比如說 今天要製作一個語音辨識的 模型 我們可以直接使用speech API 不需要再自己錄製音頻對其進行訓練並預測 這是一個 快速又簡單的入手方法
再來是 Ocado 他是一個網路最大的線上雜貨店 以往客戶寄email到這裡 都是有人工一封一封慢慢讀取 後來使用了NLP 自然語言處理 他自動讀取信封裡面的文字 甚至可以得知實體的情感 透過這樣的一個方式 幫助他們標籤 信封的優先級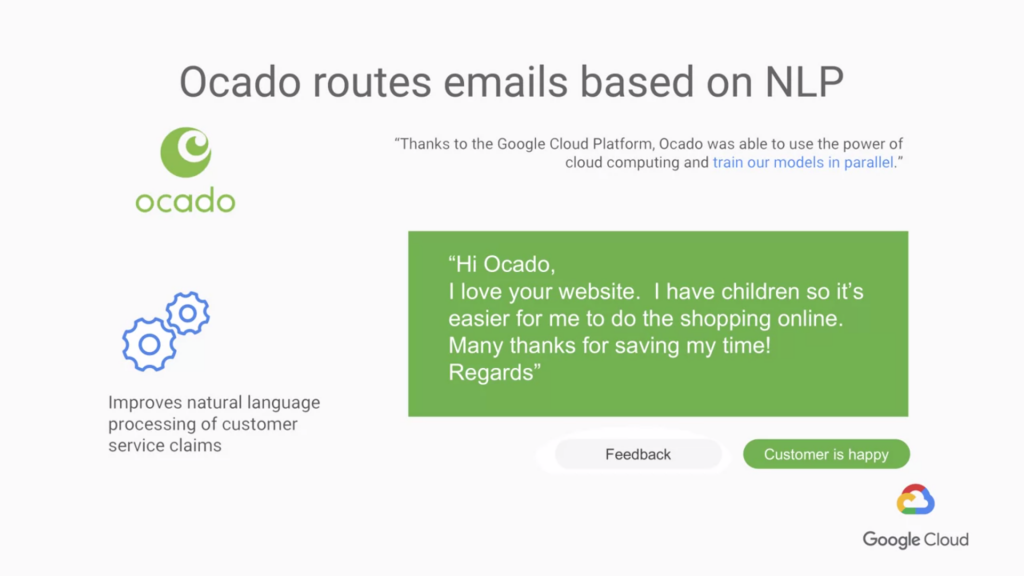
是越來越多的客戶他們不想寫信 他們比較想實際交談 所以這次我們需要使用語音API嗎 不不不不不 他們使用的方法是一個更高端更前衛的技術 他們使用Google的對話代理工具 名叫 dialogflow 透過對話介面的方式 其實就像 平常看到的自動回覆機器人一樣 他甚至能跟你直接對談 從中汲取出所要的資訊 達到一樣的效果 而且更有效率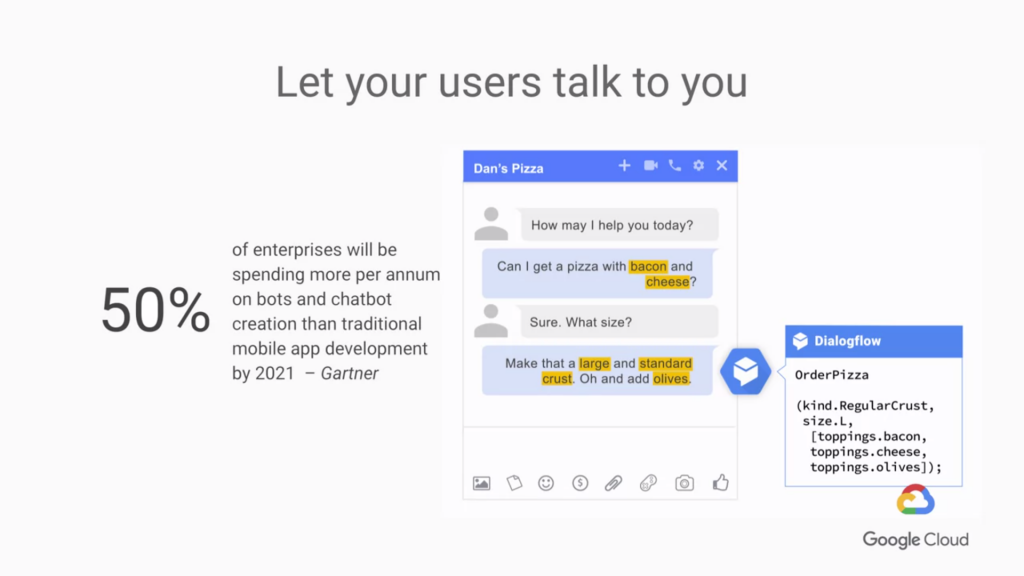

這個章節主要在說明機器學習正在往更好水平發展
aucnet從頭開始建構了 ML模型
Ocado 使用自然語言API 等他並不是從頭開始 他是使用別人做好的模型 去創造新的東西
Giphy 使用vision API和OCR也是直接從高層次開始
最後的Uniqlo使用更高層次的Dialogflog開發
這裡要說的是 我們並不需要從頭開發一個API 可以直接使用前人事先訓練好的 這是沒有問題的
這裡我想分享一下 我的小小心得 感覺這幾年隨著各種技術的成熟相對以往你可以不用這麼複雜就能完成某些事情
我指的是一個門檻的降低 看看從以前的組合語言 C語言 到現在的 Java python高階語言
這個開發者的門檻正在降低 特別是scratch 通過拖拉幾個積木 就能完成一個小小的程式 那時候剛接觸到的我 真的是蠻有興趣的成就感 透過這個門檻的降低 自然會有越來越多的人 接觸到這個領域 不管是開發工具的 簡化也好 還是開發者 的免費教學也好 是這個領域 開始有越來越多的人 參與 在這種情況下 其實想想 入門的門檻再怎麼低 他的本質還是不變 就是如果 你真的要了解 真的要往這個領域發展 哪些定理 那些基本概念 你還是要去了解 這樣才能在廣大人海中脫穎而出 不是嗎 所以在之後的文章中 我們還是會著重在 機器學習理論當中 後面應該會有機會可以實作 同時也會一直複習前面的東西 做好心理準備出發吧
今天第四天,我想做點小小的變化,是關於Google ML送的一個月課程到下禮拜一,但我還沒有做完所有測驗,還沒拿到證書,所以這三天我可能就會先專注在Google ML的課程部分,順便把影片下載下來以便重複觀看,待這幾天做完所有測驗拿到證書之後,我再把這幾天的文章接續完成,這樣說好像不是小小的變化是大大的變化了,但這幾天我還是會持續至少每日一更鐵人賽文章,文章的形式或許會像這樣說說心得,等我這幾天拿到證書後我會再認真把每一天的文章做大翻修,如果計畫順利的話預計下禮拜的這個時間前面的文章會完成更新,一切回到軌道上,那天應該是DAY 11吧,如果還有點吃緊會再慢慢補回來,只是給自己一點壓力盡力就好,所以總結文章還是會持續更新,只是這幾天更新速度會暫時放慢,但後面還是會補回來,並不影響DAY 30時看到前面有非專題文章,大致上是這樣,我不是休息,反而是要讓自己更加投入在課程學習當中,特別是假日時間要好好把握,希望是說,我投入大量時間在這地方,可能短時間內不一定能看到甚麼成就,但必定會影響我所選擇的這條路,這段旅程必須是值得的吧,先這樣,謝謝大家
編輯時間:(2019-09-19 23:59:26)
-(2019-09-20 23:16:26)更新
今日里程數-1216字 感謝閱讀~
-(2019-09-26 22:55:06)
今日里程數-2083字 感謝閱讀~
-(2019-10-02 05-54-50)
打了整個半夜我到底在幹嘛...
今日里程數-6403字 感謝閱讀~
