
Supervised Learning 監督式學習,是機器學習的一個分支,在前面ML應用的文章就有稍微簡單的介紹過一次了,
但是這次我們要深入的研究,監督式學習。
監督式的ML model和無監督的ML model,在前面的文章有說過,監督式學習和非監督式學習,
最大的差別就在傳入的資料有沒有Label(標籤),而標籤就是一個告訴ML model自己預測的對不對的
"正確答案!"
我們想要學習預測的正確答案。在無監督學習中,數據並沒有標籤!
那麼ML model在沒有標籤"正確答案"的情況下又要如何學習呢[非監督式學習]?
在非監督式學習裡ML model 的預測會傾向"分類!",請看下圖!
上面那組資料就是非常適合非監督式學習來Predict的一個Dataset,可以看到上面那組資料
分成了兩大群,這時候就算資料沒有Label,ML model 也可以把它分成兩組因為這份資料中兩組資料的界線非常明顯,
但是 Model並不會知道它在做甚麼(因為沒有Label),它只是透過了大量的數據來發現一點特徵把它分類而已,
但是並不會知道它在分的是什麼(要知道的話就要給他Label)。
而我們今天的重點是監督式學習Supervised Learning,我們來看看下面這份資料!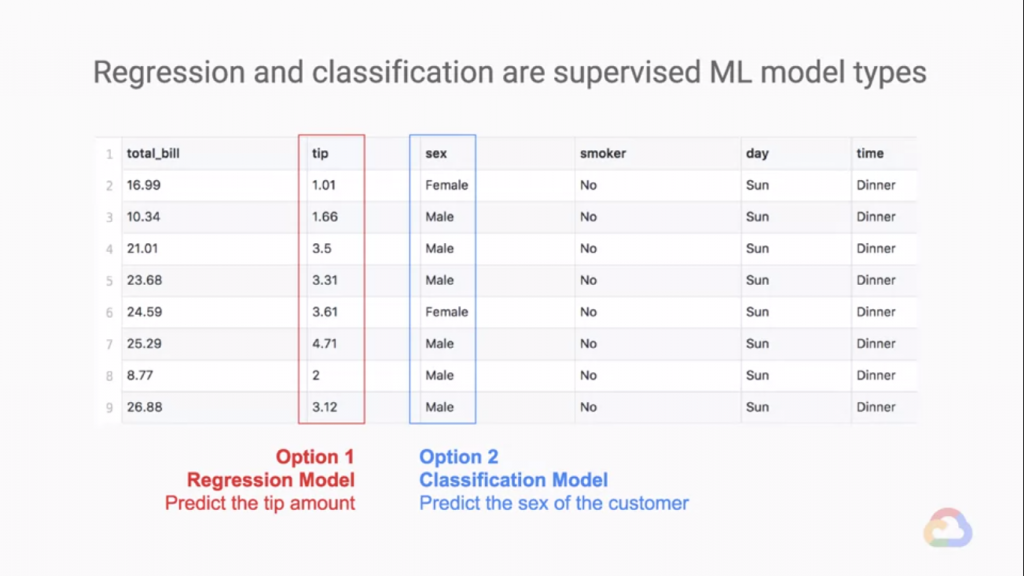
這是一間餐廳的資料,如果我們要預測一位Waiter可以收到多少小費,用非監督式學習的話是會出問題的!
我暪可以看到我們要預測的結果是"小費",而小費可以是任意數值,這代表如果要用非監督式學習來學的話
你的ML system會學的一蹋糊塗,因為小費的值有很多種根本無法分類(類別太多了!),這時候我們就可以給他
Label 這個樣子我們的ML model 就可以在資料中找到線索,並且預測出小費金額!監督式學習可以預測的東西
往往比非監督式學習還多!
