
機器學習是一門著重應用面的方法,與其將之視為演算法的問題,我們更應將之視為工程(Engineering) 的問題。因此,在應用機器學習上的腳步,並不止於在本地端訓練模型就好,還要考慮到上線進行應用,而在上線應用的情境之下,很多環節會有所差異,課程中就給出了一個例子,也就是在機器學習流程當中的批次處理(Batch)與串流處理(Stream)。
批次處理指的是一次性地處理大部分或所有的資料,在本地端的環境裡,我們通常是以此方式來進行資料的處理、訓練與預測等環節,而串流處理指的是將資料視為一連串的序列,以不斷滾動進行的方式將資料輸入我們的工作中,通常一次只會包含一筆或僅幾筆的資料量。在某些商業情境下,串流處理的方式是能真正發揮價值甚至是必要的,比如說在金融服務業中的詐欺偵測模型,需要不斷地使用最新的交易資料來更新模型,以確保模型能捕捉到最新型的詐欺模式,以最大化降低損失,又或者如網路輿情偵測分析的情境裡,由於網路社交媒體上的意見與風向變動非常快速,因此持續地輸入最新發生的相關訊息,讓分析模型適應地學習該趨勢,以便在第一時間給出最精確的預測結果,才能洞燭機先,早一步作出相應的行動。除了以上提及的兩種情境,很多產業也會有類似的需求,如製造業、遊戲業與廣告業等。
由於批次處理與串流處理會產生不同的結果,因此如果在本地進行訓練與應用環境中部署使用時採用兩種不同的方式,就會發生機器學習訓練與應用偏差的問題,對表現帶來負面影響。Google Cloud Platform提供的Cloud Dataflow(註1)透過能同時處理批次(過往)與串流(即時)的資料,確保我們在訓練與實際應用預測時是使用同樣的系統(見圖1),以消弭兩種情境下不一致的問題。
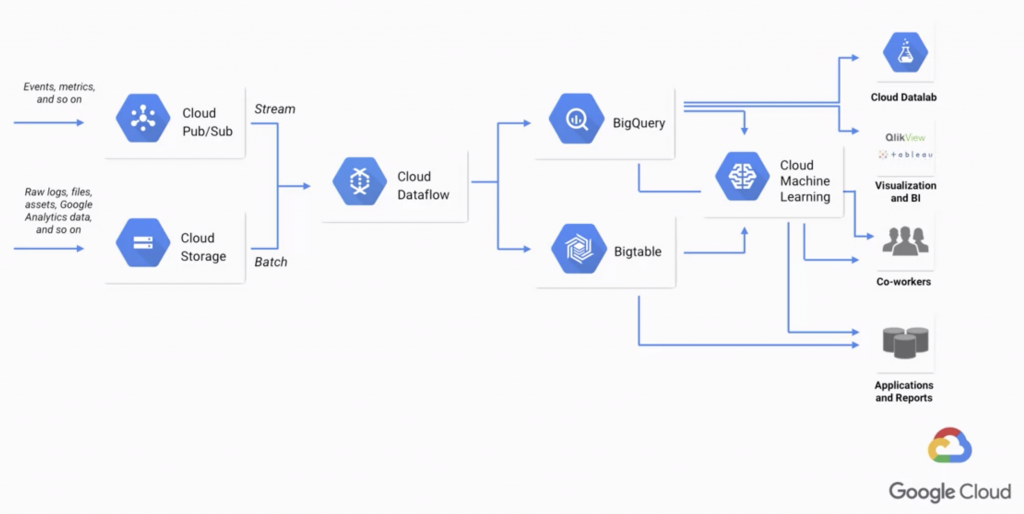
圖1
Source: Coursera - How Google does Machine Learning
註1: https://cloud.google.com/dataflow/

 iThome鐵人賽
iThome鐵人賽