前六天我們簡單介紹了Docker和k8s的架構,今天我們來稍微聊一下整個DevOps的開發流程,透過全貌從另外一個新的面向去了解k8s,這篇主要偏開發上的流程概念,中間的部分流程會用到k8s,我想就某種程度而言,這就已經代表了完整的DevOps的流程了吧,不過因為我們受限於時空地理的限制,不見得每一段都會仔細接觸過,但個人看完這相關的資料,覺得蠻重要的,所以來分享下。
這個部分是指基準代碼,一般我們在做開發的時候,當有代碼要做版本管控的時候,我們可能會用到像是Git、Mercurial、Subversion等等的工具,我們也會在本地端架設repository(簡稱repo),也就是代碼數據庫的副本。
我們來看張圖:
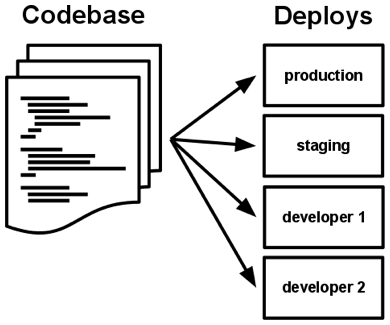
基準代碼和應用之間必須保持一對一的關係:
這個部分是指在開發環境的設置中,定義一個相依性的套件集合,這個套件集合是用來幫助開發用的,套件集合裡面定義了彼此之間的關係。
主要的特點是說,在應用程序運行的途中,只要是用到相依性的套件,那必然是有定義過的,系統工具也是同樣的邏輯,也就是明確地宣告並隔離依賴。
這樣的好處是說,當我們要Debug的時候,當本身應用程序發生問題的時候,我們可以透過這個明確宣告的依賴關係清單去查詢用到了哪些套件,舉個例子:
Debug流程
所以可以看到,如果沒有依賴清單或是依賴性是隱性的話排查問題會非常麻煩。
這個部分是說關於環境中設置的問題,不是指一般程序使用的設定檔,這種設置是環境變量上的,像是我們在linux下env指令得到的類似結果,他會推薦使用這種方式是因為這樣可以針對不同的使用情境切換不同的變數值,而不會受到設定檔的限制,設定檔的限制會有:
使用環境變數的設置就不會有這樣的風險,另外如果變數彼此間獨立性夠強,當應用程序不斷擴展,需要更多種類的部署時,這種配置管理方式就能保有各種部署上的特性。
後端服務是指程序運行所需要的通過網絡調用的各種服務,如數據庫(MySQL),消息/隊列系統(RabbitMQ),SMTP郵件發送服務(Postfix),以及緩存系統(Memcached)。
在這樣的原則下,應用(app)不會對不同地方提供的服務而有所區別,一般來說,任意的部署,都應該可以在不進行任何代碼改動的情況下,將本地MySQL數據庫換成第三方服務。
我們來看張圖:
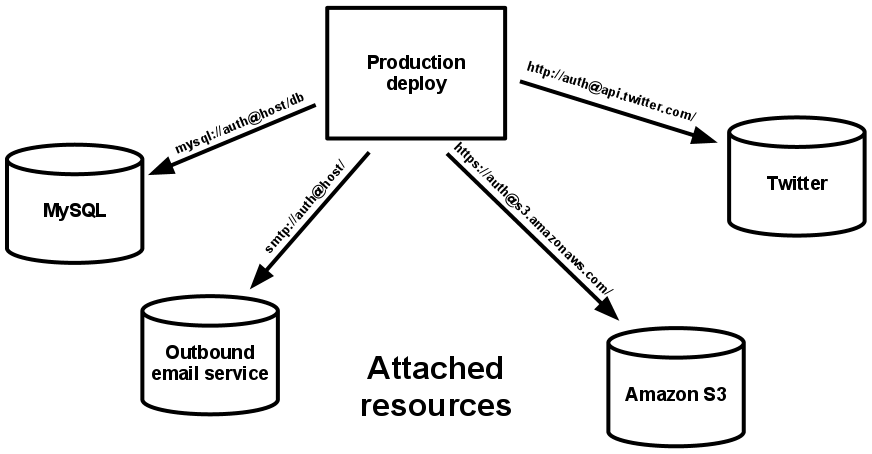
部署可以按需加載或卸載資源。
在這樣的設定下,當數據庫有問題的時候,只要切換做好就可以了,不需要去改代碼。
基準代碼轉化為一份部署(非開發環境)需要經過以下三個階段:
在運行環境中,應用程序通常是以一個或多個進程運行的。
這些進程必須是沒有狀態的且彼此之間並沒有共享資源。任何需要持久化的數據都要存儲在後端服務內,比如數據庫。
互聯網應用有時會運行於服務器的容器之中。
這些應用必須要能夠自我加載而不依賴於任何網絡服務器就可以創建一個網絡服務。互聯網的應用會通過端口綁定來提供服務,並監聽發送至該端口的請求。
任何計算機程序,一旦啟動,就會生成一個或多個進程。
在應用中,這些進程的運行主要藉鑑於unix守護進程模型,可以運用這個模型去設計應用架構。
有兩個面向:
參考下圖:
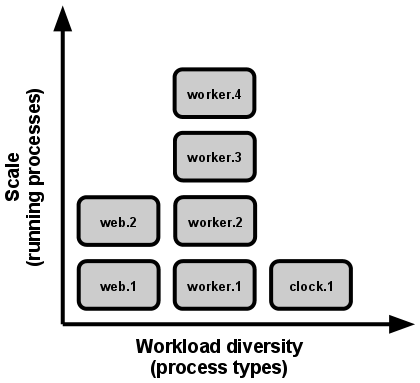
因為進程的無共享及水平分區的特性,上述進程模型會在系統擴展時有顯著的效用。
*應用的進程應該要是*易處理(disposable)的,意思是說它們可以瞬間開啟或停止,並追求最小的啟動時間。
理想狀態下,進程從敲下命令到真正啟動並等待請求的時間應該只需很短的時間。更少的啟動時間提供了更敏捷的發布以及擴展過程,此外還增加了健壯性,因為進程管理器可以在授權情形下容易的將進程搬到新的物理機器上。
應用若要做到持續部署就必須縮小本地與線上差異。
如下所述:
將上述總結變為一個表格如下:
| 傳統應用 | 12-factor應用 | |
|---|---|---|
| 每次部署間隔 | 數週 | 幾小時 |
| 開發人員 vs 運維人員 | 不同的人 | 相同的人 |
| 開發環境 vs 線上環境 | 不同 | 盡量接近 |
應用的開發人員應該反對在不同環境間使用不同的後端服務,即使適應器已經可以幾乎消除使用上的差異。這是因為,不同的後端服務意味著會突然出現的不兼容,從而導致測試、預發布都正常的代碼在線上出現問題。這些錯誤會給持續部署帶來阻力。從應用程序的生命週期來看,消除這種阻力需要花費很大的代價。
不同後端服務的適應器仍然是有用的,因為它們可以使移植後端服務變得簡單。但應用的所有部署,這其中包括開發、預發布以及線上環境,都應該使用同一個後端服務的相同版本。
日誌使得應用程序運行的動作變得透明。在基於服務器的環境中,日誌通常被寫在硬盤的一個文件裡,但這只是一種輸出格式。
應用本身不需考慮存儲自己的輸出流,且不該試圖去寫或者管理日誌文件。相反,每一個運行的進程都會直接的標準輸出(stdout)事件流。開發環境中,開發人員可以通過這些數據流,實時在終端看到應用的活動。
這些事件流可以輸出至文件,或者在終端實時觀察。最重要的,輸出流可以發送到Splunk這樣的日誌索引及分析系統,或Hadoop/Hive這樣的通用數據存儲系統。這些系統為查看應用的歷史活動提供了強大而靈活的功能,包括:
進程構成(process formation)是指用來處理應用的常規業務(比如處理web請求)的一組進程。與此不同,開發人員經常希望執行一些管理或維護應用的一次性任務,例如:
我們看完了以下12個重要的應用組成要素,發現到可以分為幾個面向:
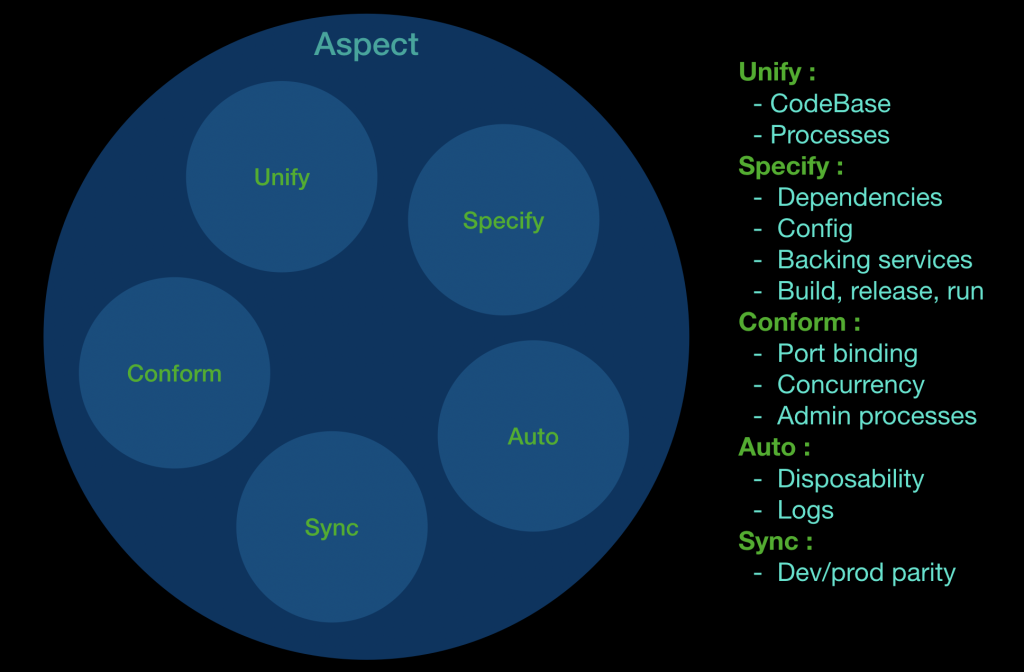
這個部分是指定義所謂應用中的最小單位,定義了最小的單位以後就能夠方面我們去拆分其中的結構
所以可以看到,這邊我就把CodeBase(基準代碼)、Processes(進程)視為一類,因為就某些方面來說,他們確實構成了整個應用(app),也影響了建置、部署等等階段的結構。
這個部分是指盡可能地將結構做拆分,能夠隔離的、切開來看的就盡量區分,盡量不要有重疊的部分,這主要是強化元件中的獨立性,這樣在分開開發或是除錯上都會有幫助,有幾個元件:Dependencies(依賴)、Config(配置)、Backing services(後端服務)、Build, release, run(建置, 發布, 運行)
這個部分是指元件組合上的協調度,如何有效的組合元件又不會出問題,而且是當這樣的組合是有必要性的時候,我們可以看到這些組合是為了增加應用上的拓展性,如:Port binding(端口綁定)、Concurrency(並發)、Admin processes(管理進程)
這個部分是指在單個元件上,它是否能做到自動啟動一些機制,以達到幫助維運的需求,像是自動紀錄、自動快速開啟與結束,如:Disposability(易處理)、Logs(日誌)
這個部分是指不同環境上的轉移、等價等等,這裡的Dev/prod parity(開發環境與線上環境等價)就是滿足這樣的需求設計的,或許將來會有新的性質會新增到這個項目當中
看完了這5個面向,讀者是不是對於這個12要素更了解些呢?其實一言以貫之,我們可以看到,這些要素的相關性及連結,是利用以下邏輯去思考的:
所謂的12要素(12-factor)大致上就是在描述這些東西,希望針對這一系列的介紹能優化大家對於在開發流程的觀念,就好比是有好的coding-style一樣,相信針對這部份的介紹也能讓大家理解到k8s的重要性,我們明天見!
本文同步刊載於https://github.com/x1y2z3456/ironman
感謝您撥冗閱讀此文章,不喜勿噴,有任何問題建議歡迎下方留言:)
說個笑話,希望我能寫滿30天啊(笑

