這時候已經把GCP結合Machine learning的特點和優勢概括地介紹一遍了。
所以說接下來暖身的Module1_Quiz應該不難。
如果還是有疑惑或不清楚的地方,下面已經整理好一些課程想表達的重點。
測驗前再複習一下,應該對於準備測驗和答題會有幫助。
一般會建議使用大樣本的訓練數據集,
因為數據集的數量越大,也代表母體中的抽樣愈大,
這樣訓練出來的模型(Model)兼容性(Coverage)和偏誤(Bias)也會必較小,
通用度也會比較好。至於標記(Label)的部分,
實驗型的小樣本採取人工標記尚有可行性。
但是一旦有擴大scale up 訓練集的需求時,
採用業界和學界成熟的開源資料庫(例如ImageNet)會是兼顧標籤正確性與節省時效的做法。
from How google does Machine Learning Week1 筆記2
推薦系統常用於個人化服務的演算法
Recommendation system
推薦系統
例如
線上購物網站的物品推薦、
Amazon線上書城的相關書籍、
Youtube的相關影片推薦(例如:可能你喜歡OOO的影片推送)、
Netflix的同類型或相關影集推薦(例如:同一部導演的作品,續集、三部曲...等等)。
from How google does Machine Learning Week1 筆記5
在ML Model實際上線服務的實務經驗中,
對於增加ML產品專案的成功率,
Google從中學到一格寶貴的教訓,
認為其中的關鍵在於?
在Why google Cloud?這部教學影片有提到,
留意講者的解說,還有這張課程投影片。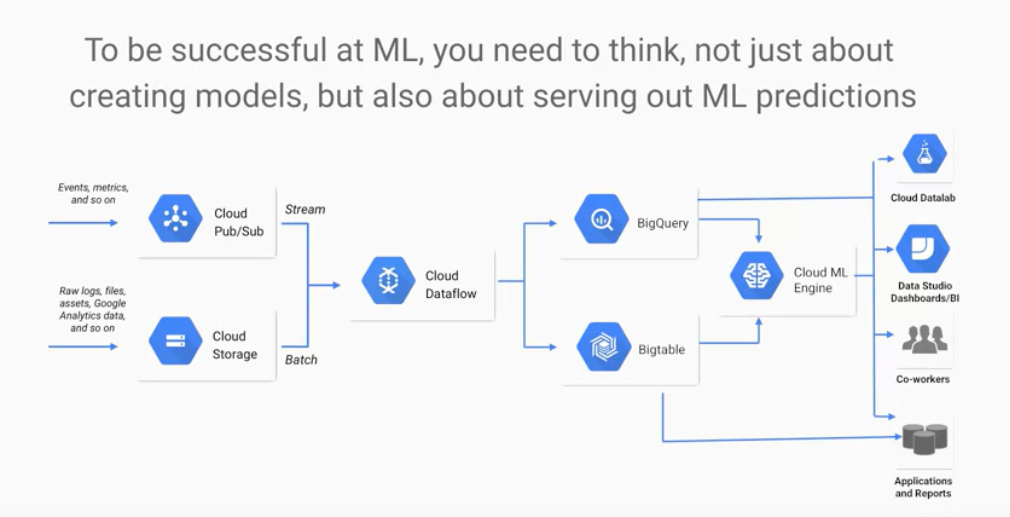


 iThome鐵人賽
iThome鐵人賽