今天來講一下分類器評估的方式。
一般常見的評估法 (evaluation) 有蠻多資料可以參考,在這裡就是快速的說而已,並不會琢磨太多。主要要講解的會是我們採用什麼的評估方式來評估 PTT 文章分類的部分;之後計算結果的方式皆會採取這邊提到的評估法來進行。
分類演算法常見評估方式
在文字分類的題目部分有多種評估分類系統性能的標準。常用的評估標準:準確率(Precision)、召回率(Recall) 、F1-評測值(F1-measure)、微平均(Micro-average)和巨集平均(Macro-average)。另外也包含了ROC曲線 (Receiver operating characteristic curve) 、AUC (Area Under Curve)和多元相關(多元混淆矩陣和相對應驗證指標) [註 1]。
分類大概可以分成二元分類(binary case)和多元分類(multiclass case),我們在前面有提到,用來分辨 PTT 文章的好壞我們把它視為是一個二元分類的問題。所以評估的部分也就是用二元分類來表示。所有的分類問題都可以先產生出一個稱為混淆矩陣(Confusion matrix)的東西,然後從這個矩陣在去算出一些成效指標 [註 2]。
在二元分類基本上就是分「有」和「沒有」、「正確」跟「錯誤」、「真」跟「假」、「正」和「負」(以下我們皆用「正」和「負」來代表)。下表是二元分類的混淆矩陣,True condition 就是你資料的答案,Predicted outcome 就是模型預測出來的結果。
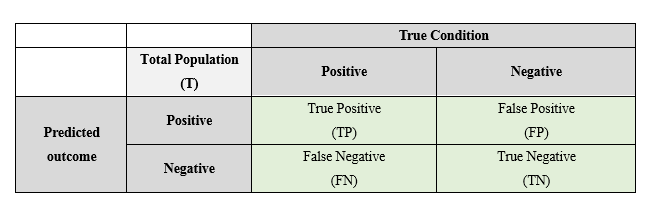
混淆矩陣(Confusion matrix)
Positive就是「正確」;Negative就是「錯誤」。
True Positive (TP)「真陽性」:真實情況是「正」,預測為「正」的個數。
True Negative(TN)「真陰性」:真實情況是「負」,預測為「負」的個數。
False Positive (FP)「偽陽性」:真實情況是「負」,預測為「正」的個數。
False Negative(FN)「偽陰性」:真實情況是「正」,預測為「負」的個數。
通常講到這邏輯的都時候都會用醫師診斷某病人是否生病?這邊就不多說了,想了解更多可以參考這一篇:
https://medium.com/@chih.sheng.huang821/機器學習-統計方法-模型評估-驗證指標-b03825ff0814
如果大家還記得前一天提到的 Weka 分類計算評估方式。我們可以從下圖看到其實 Weka 已將把前面提到的評估法都算出來了,而且還是針對每一個類別都有各自的數值。
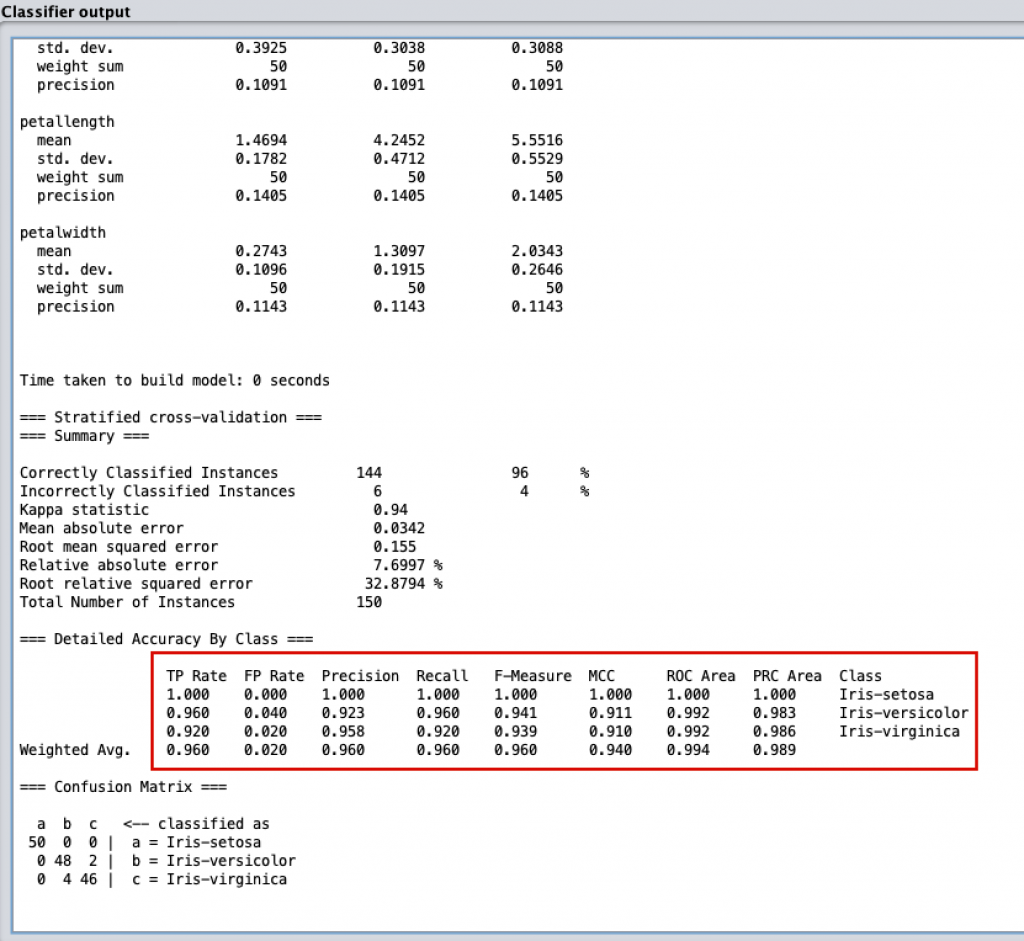
不過我們在這邊的計算不會用的這麼複雜,我們只要知道 “Correcrly Classified Instances” 這個數值 (也就是整體的 Accuracy) 即可。
所以之後在比較三個不同的分類演算法時,就會直接比較各自的 accuracy 數值當作最終的結果。
註1: https://www.sciencedirect.com/science/article/pii/S2210832718301546
註2: Sebastiani,F. Machine learning in automated text categorization [J]. ACM Comput. Surv. 34(1): 1–47.
免責聲明:本文章提到的股市指數與說明皆為他人撰寫文章內容,包括:選股條件,買入條件,賣出條件和風險控制參數,只適用於文章內的解釋與說明,此提示及建議內容僅供參考之用,並不構成投資研究、認購、招攬或邀約任何人士投資任何投資產品或交易策略,亦不應視為投資建議。


 iThome鐵人賽
iThome鐵人賽