前面提到了怎麼標記文章的好壞,以及我們打算使用的分類演算法,接下來要先講一下把文字轉成數值 (Arff, attribute-relation file format) 的部分。
Arff 是 Weka 所支持的檔案格式之一,只要想使用 weka 執行裡面的演算法就必須先使用此資料格式讀入。Arff 主要分為三個 property。
附上一段說明文章內的註解
Lines that begin with a % are comments. The @RELATION, @ATTRIBUTE and @DATA declarations are case insensitive.
懶得看英文沒關係,我們直接用個標準的範例如下圖所示:
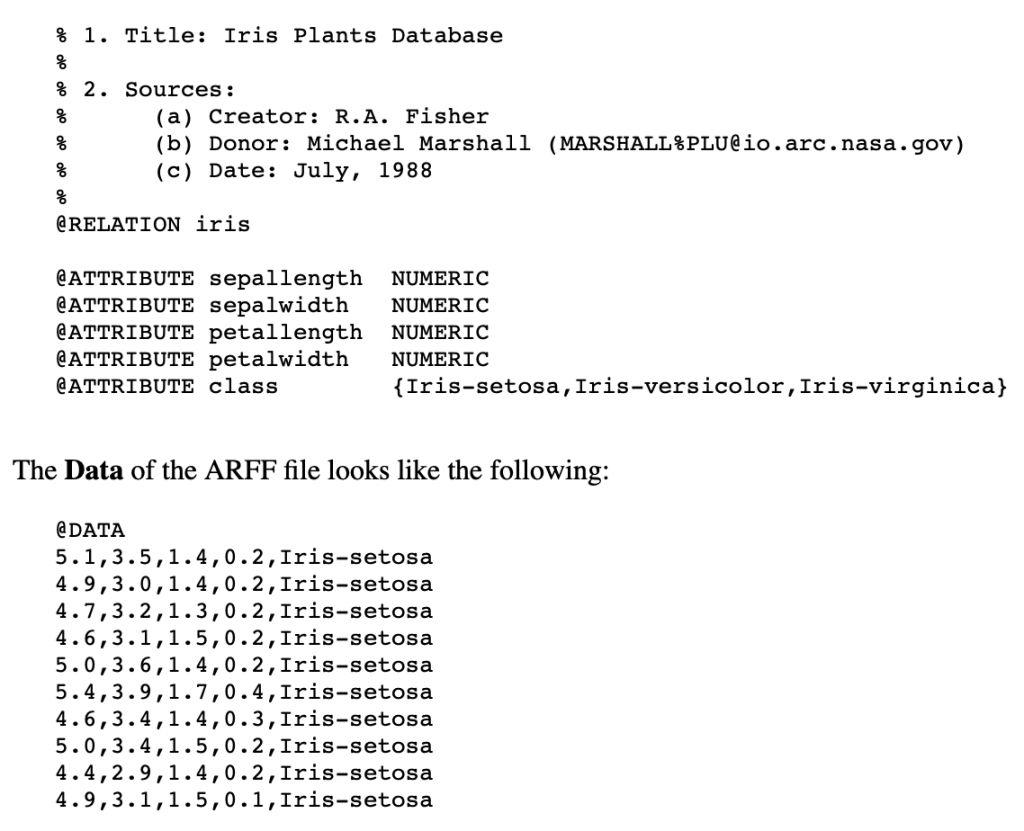
annotation
最上方式是註記,可以寫下這個資料及代表著什麼東西,讓你寫下比較詳細的紀錄,方便自己以及別人理解。
relation
這個要在檔案的最開頭,但在註解下方(不算註解)。
雖然叫 relation,不過這個其實只是用來表示這個 data set 的名稱用的。所以我一直無法理解為何要叫做 relation。
a list of the attributes
是定義資料屬性的地方 (也就是 feature 屬性)。每一行 @attribute 都定義了一個如同表格的 column,由 屬性名稱 加上 屬性型態 來組成。屬性名稱可以自己命名,看你幫該 feature 取什麼名字。屬性型態通常為字串或是數值,若是字串就用 String,數值就用 Numeric。
比較特別的是在 attribute 後需要補上類別名稱種類,以這個例子來說
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
表示有三個類別,依序是“Iris-setosa”、“Iris-versicolor”和“Iris-virginica”。
Data
在 property 的最後一個位置,儲存資料向量值。每個資料維度則用 “,” 來做分隔,依序對應到檔案上面的 @attribute 屬性標籤,而最後掛上該資料的類別名稱,像是:
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-versicolor
4.7,3.2,1.3,0.2,Iris-virginica
有關 arff 詳細的定義可以參考這裡:
https://www.cs.waikato.ac.nz/~ml/weka/arff.html
好的,現在東風已經具備,接下來就要看結果如何了。
我們先用一個小的測試集試試看,將標記後的資料 ( 227 筆的 instances) 用 Day 19 提到的方式取平均轉成數值。資料集可以從這下載:
https://github.com/deternan/PTT_Stock/blob/master/source/tagging_fasttxt_cc.arff
此資料集中 positive 與 negative 各有 112 與115 筆資料。分別利用三個分類演算法得到的正確率 (Correctly Classified Instances) 結果如下:
結果看起來好像都只有比 5 成高一些,代表著什麼意思?就是比丟銅板還好一點而已?
誒,這樣不對啊,如果結果跟丟銅板差不多,那我前面 20 天搞的東西是搞心酸的嗎?母湯 母湯 ?
你問我有沒有機會可以改善?
當然有囉!!
明天再跟你說 ?
免責聲明:本文章提到的股市指數與說明皆為他人撰寫文章內容,包括:選股條件,買入條件,賣出條件和風險控制參數,只適用於文章內的解釋與說明,此提示及建議內容僅供參考之用,並不構成投資研究、認購、招攬或邀約任何人士投資任何投資產品或交易策略,亦不應視為投資建議。


 iThome鐵人賽
iThome鐵人賽