
今天在Google ML課程中,看到老師使用 Tensorflow Playground 來說明 L1 /L2 正規化(Lasso/Ridge)。所以今天接續第6天的 Tensorflow Playground 筆記,來記錄一下L1 /L2 正規化。
我們了解過度擬合(overfitting)發生時,有可能是因為我們訓練的假設模型本身就過於複雜,所以我們是否能讓複雜的假設模型退回至比較簡單的假設模型呢?這個退回去的方法就是正規化(Regularization)。
我們先來看看,過度擬合的範例(來源網址)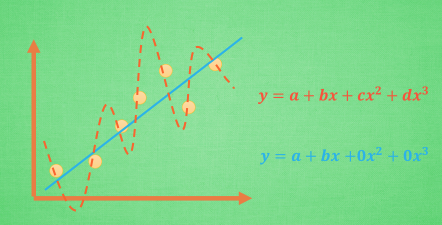
我們知道,過度擬合就是所謂的模型非常完美的擬合上了這些訓練的數據, 導致在測試的時候誤差過大。如果模型過擬合,那麼這個方程就可能是一個比較複雜的非線性方程,正是因為這裡的
和
和使得這條虛線能夠被彎來彎去,所以整個模型就會特別努力地去學習作用在
從上面莫煩的說明,我們可以想像的出,如果要讓模型不那麼彎曲,有二個方向我們可以努力。
第1個,就是減少特徵,把他的權重變成0,這叫L1正規化。
第2個,就是減少特徵權重差異,讓某些特徵的權重不要太突出,這叫L2正規化。
我們來看看 Tensorflow Playground 的範例,打開這個網址,可以看到初始的設定。
它選擇了所有的特徵,並在隱藏層的部份設定了兩個隱藏層,從而創建了許多連接。
如果我們先不打開正規化,執行訓練後,你可以看到隱藏層,訓練得到的神經元圖像。由它們之間連接的線可看的出來,每個權重與神經元都處於活躍狀態。
如果把正規化(Regularization)設定為L1,再執行訓練。可以看到很多權重都被設定為0,特徵輸入與隱藏層的神經元被大大的減少。
整個模型的複雜度簡化很多。 L1正規化確實有助於將我們的複雜模型縮減為更小的泛化模型。添加正規化後,我們看到無用的功能全部變為零,並且連接線變得稀疏並顯示為灰色。倖存下來的唯一特徵是x1平方和x2平方,這是有道理的,因為這2個特徵加在一起就構成了一個圓的方程。

L2正規化,當我們訓練它時,每個權重與神經元都還是處於活動狀態,但是非常虛弱。
所以
我們再看一個例子。
沒有正規化的情況
每個權重與神經元都處於非常活躍狀態。

剩下X1X2的特徵與權重。

每個權重與神經元都處於活動狀態,但是非常虛弱。
L1正規化使用其中一個特徵而將某些拋棄,而L2正規化將同時保留特徵並使權重值保持較小。因此,使用L1,您可以得到一個較小的模型,但預測性可能較低。有什麼辦法可以做到兩全其美嗎?Elastic net似乎可以辦到,我還在了解中,先暫記一下。
好,第8天,結束

參考
課程:Art and Science of Machine Learning / Lab: L1 Regularization
Lasso算法
Tikhonov regularization
L1 / L2 正規化 (Regularization)
Elastic net regularization
