昨天我們只有抓到第一頁的文章標題,今天就來試著讓程式學會「換頁」吧!

當我們在網頁中按下第二頁或下一頁後,可以發現網址變成 https://ithelp.ithome.com.tw/articles?tab=tech&page=2,多了一個 GET 參數 page=2,代表網站會用這個參數來控制當下要顯示的頁數。我們可以手動把網址的參數改成 page=5、page=20 試試看是不是真的可以用這個參數來控制。
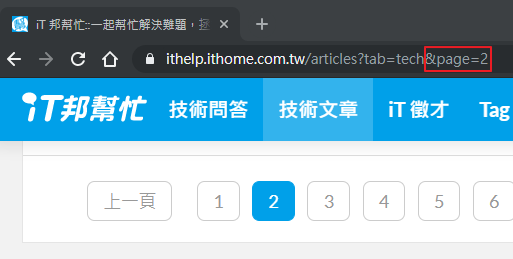
再看一下下一頁的按鈕,發現其實是超連結。
所以有兩種換頁的方式:
page 參數,發每一頁的請求出去話不多說,來寫程式!
import requests
from bs4 import BeautifulSoup
# 抓取 1~10 頁
for page in range(1, 11):
titles = []
html_doc = requests.get(f'https://ithelp.ithome.com.tw/articles?tab=tech&page={page}').text
soup = BeautifulSoup(html_doc, 'lxml')
# 先找到文章區塊
article_tags = soup.find_all('div', class_='qa-list')
for article_tag in article_tags:
# 再由每個區塊去找文章連結
title_tag = article_tag.find('a', class_='qa-list__title-link')
titles.append(title_tag.text)
print(f'Page: {page}')
print(f'Titles: {titles}')
print('==================================')
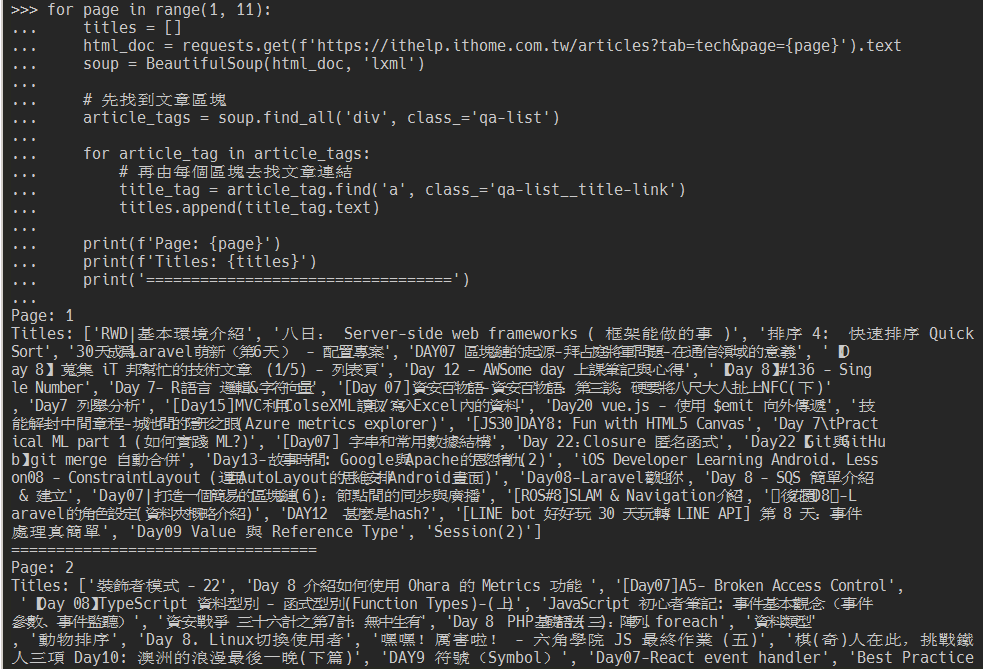
先用內建方法 range() 來指定要抓的頁數範圍,range(1, 11) 代表抓 1~10 頁;再用 f-strings 組合出每一頁的網址,f'https://ithelp.ithome.com.tw/articles?tab=tech&page={page}'。
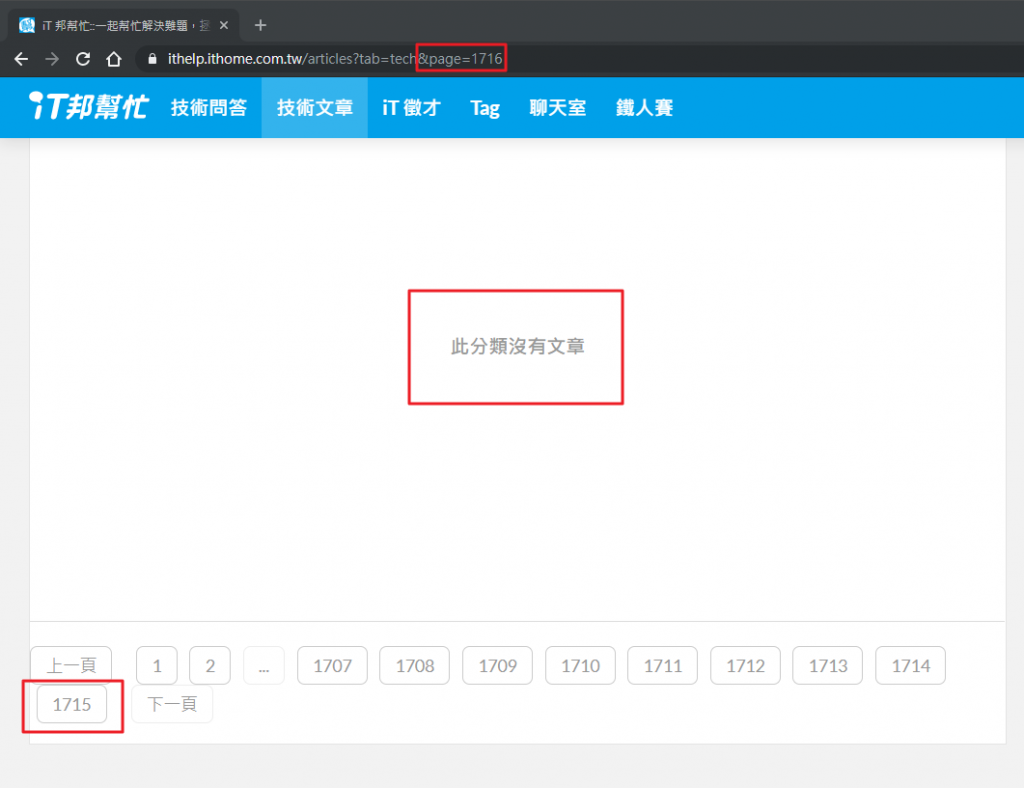
需要注意的是,如果抓到超過最後一頁的時候(到底抓這麼多幹嘛XD),列表中會顯示「此分類沒有文章」,此時就應該要停止抓取了。例如目前最後一頁是 1715,在網址中把頁數改成 1716。
此時應該要適時的結束換頁,不然程式會無止盡的跑下去。
html_doc = requests.get('https://ithelp.ithome.com.tw/articles?tab=tech&page=1716').text
soup = BeautifulSoup(html_doc, 'lxml')
# 先找到文章區塊
article_tags = soup.find_all('div', class_='qa-list')
# 沒有文章
if len(article_tags) == 0:
# 跳出換頁迴圈或離開程式
print('沒有文章了!')
# ........
檢查「下一頁」的元素,決定我們要使用哪種選擇器來抓到下一頁的連結。
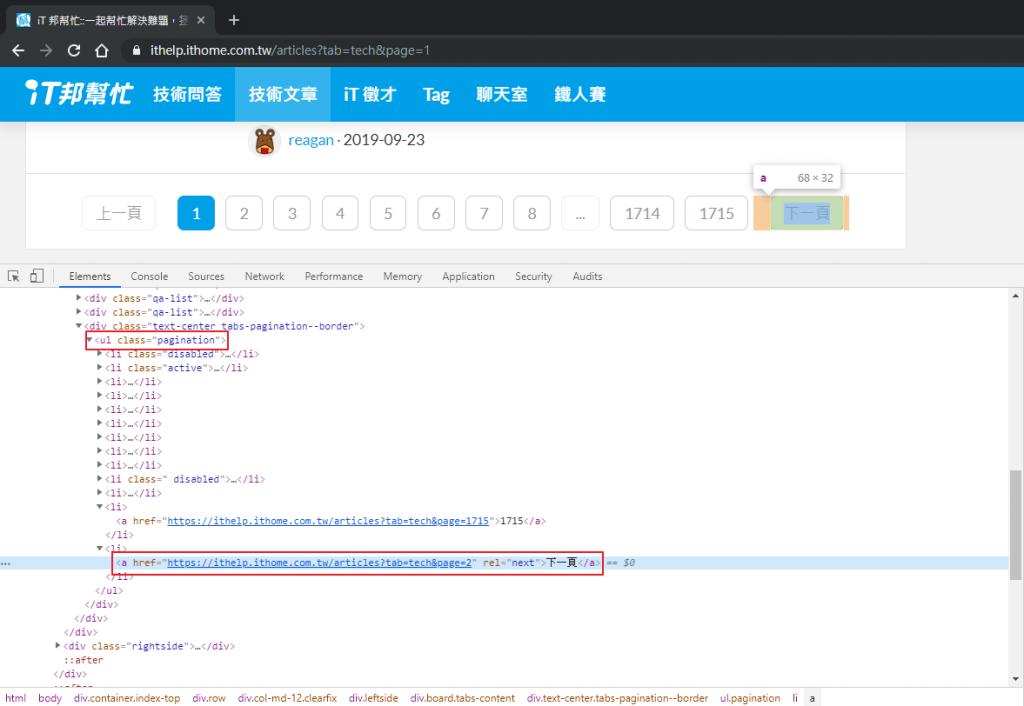
下一頁換成 >>)。a:contains('下一頁')
ul 開始,抓最後一個 li 底下的 a。如果網站換了按鈕順序會失效(例如最後一頁拿掉下一頁按鈕)。ul.pagination > li:last-child > a
a 的 rel 屬性來抓。如果網站換了這個標籤的屬性會失效。a[rel=next]

過去經驗,前兩點比較常有失效的狀況,我們就先以 a[rel=next] 來作為換頁的選擇器吧!
import requests
from bs4 import BeautifulSoup
# 抓取 1~5 頁
current_page = 1
end_page = 5
# 起始頁面網址
target_url = 'https://ithelp.ithome.com.tw/articles?tab=tech'
while(True):
titles = []
html_doc = requests.get(target_url).text
soup = BeautifulSoup(html_doc, 'lxml')
# 先找到文章區塊
article_tags = soup.find_all('div', class_='qa-list')
for article_tag in article_tags:
# 再由每個區塊去找文章連結
title_tag = article_tag.find('a', class_='qa-list__title-link')
titles.append(title_tag.text)
print(f'Url: {target_url}')
print(f'Titles: {titles}')
print('==================================')
# 取得下一頁網址
target_url = soup.select_one('a[rel=next]')['href']
current_page = current_page + 1
if current_page > end_page:
break
這種方式一樣也需要注意最後一頁的問題,一樣到最後一頁的畫面檢查下一頁的元素,發現上層的 li 標籤多了一組 class="disabled" 屬性,而且 a 標籤不見了。所以在程式中可以多這樣的判斷:
while(True):
# ...略過
# 取得下一頁標籤
next_page_tag = soup.select_one('a[rel=next]')
# 如果抓不到會得到 None,跳出迴圈
if not next_page_tag:
break
target_url = next_page_tag['href']
# ...略過
今天為止我們已經可以取得每一頁的標題了,但各位鐵人大大們的精華都在文章內啊!明天接著來抓看看文章內容吧~


 iThome鐵人賽
iThome鐵人賽