大家還記得昨天的落落長選擇器嗎?
html > body > div > div.row > div.col-md-12.clearfix > div.leftside > div.board.tabs-content > div.qa-list > div.qa-list__content > h3.qa-list__title > a.qa-list__title-link
這樣的選擇器會讓開發者(很有可能是正在看文章的你)在除錯的時候很難發現問題,而且一旦網站調整了中間某個地方的樣式,選擇器就會失效。所以我們今天就來練習怎麼樣使用比較友善的選擇器吧!
絕大多數的網站在設計 CSS 時都是有跡可循的,我們可以藉由觀察來了解每個選擇器對應的網站區塊。
div.leftside 對應到畫面中左邊的區塊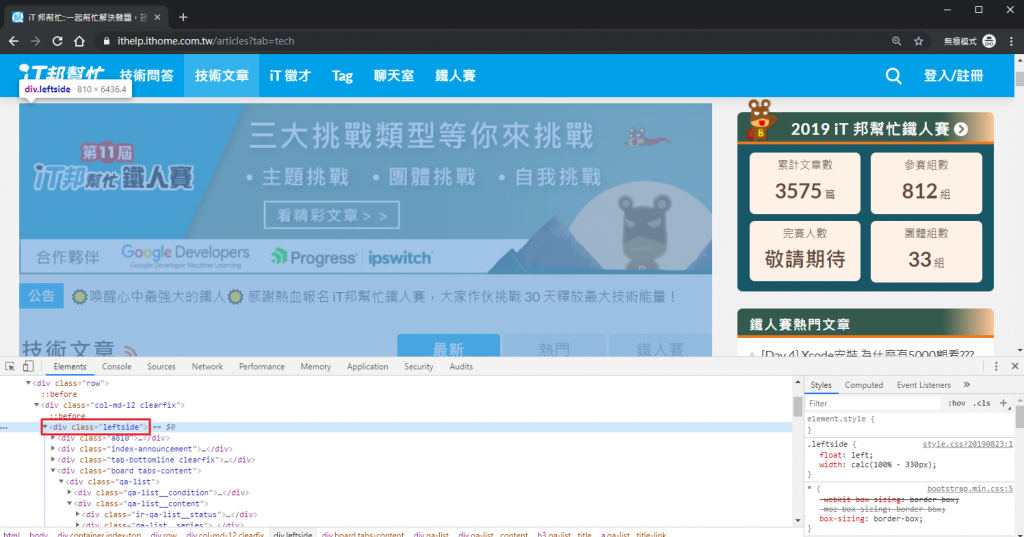
div.board.tabs-content 對應到文章列表的區塊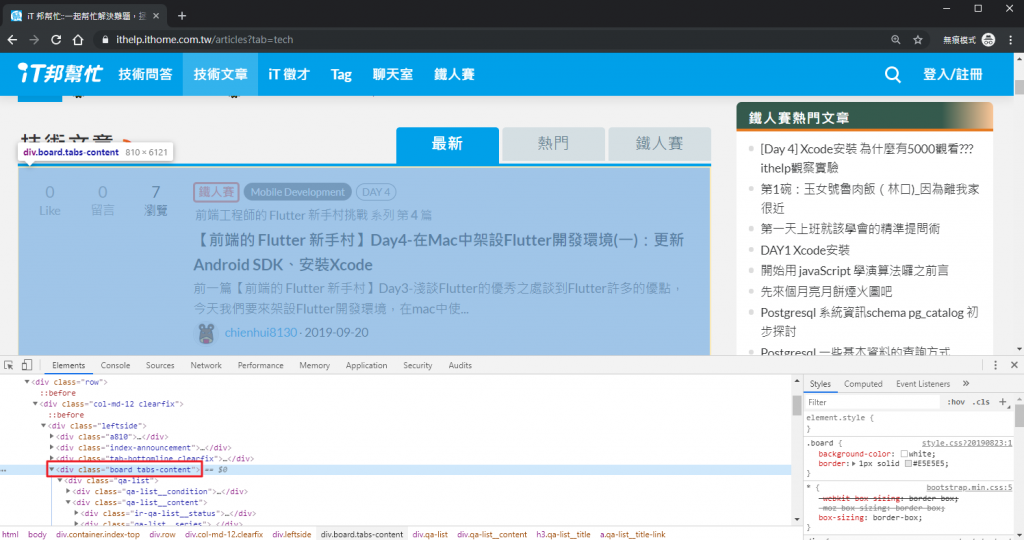
div.qa-list 對應到一列文章資訊的區塊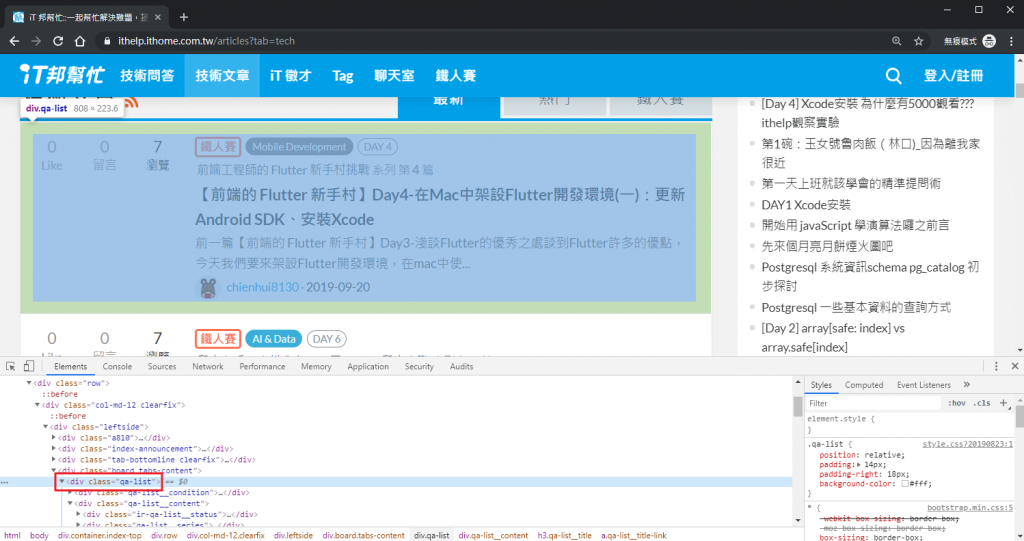
div.qa-list__content 對應到文章主要資訊的區塊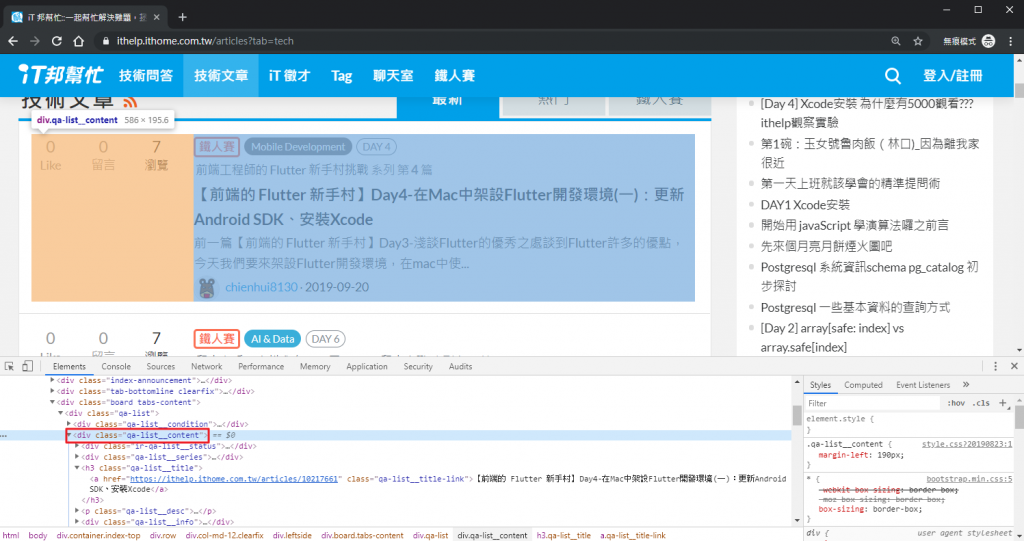
h3.qa-list__title 對應到文章標題的區塊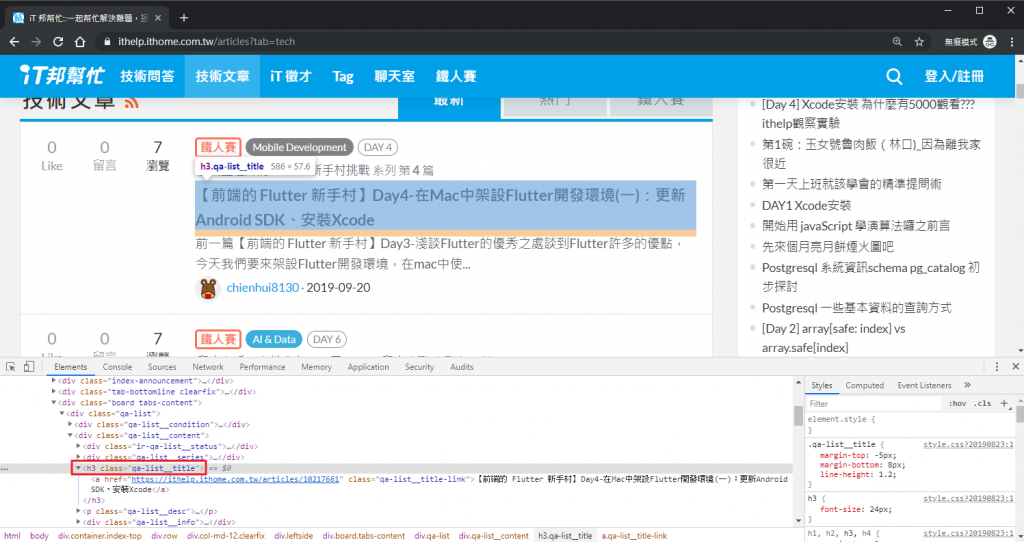
a.qa-list__title-link 對應到文章標題連結的區塊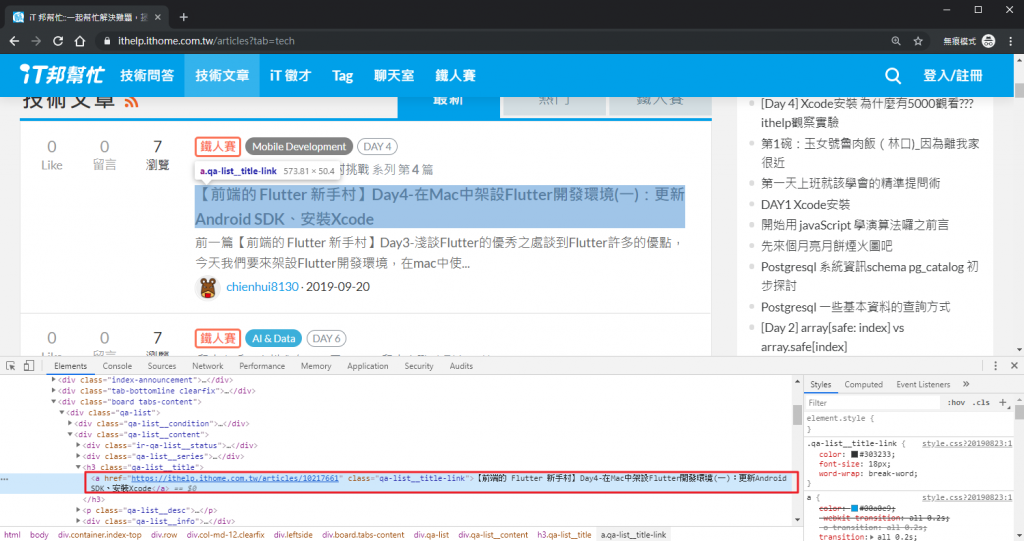
只要能找出爬取目標對應的選擇器,就可以直接以對應的選擇器來取得目標資料了。
了解網站結構後,可以試著調整原本那一長串選擇器。例如要找出全部文章標題,可以用這樣的選擇器:
div.qa-list > div.qa-list__content > h3.qa-list__title > a.qa-list__title-link
或者最短的,直接使用文章標題連結的選擇器:
a.qa-list__title-link
但如果使用到這麼簡短的選擇器,要確認一下網頁中有沒有其他「剛好」使用相同選擇器的區塊,最快能確認的方式當然是寫個程式來試試看囉!
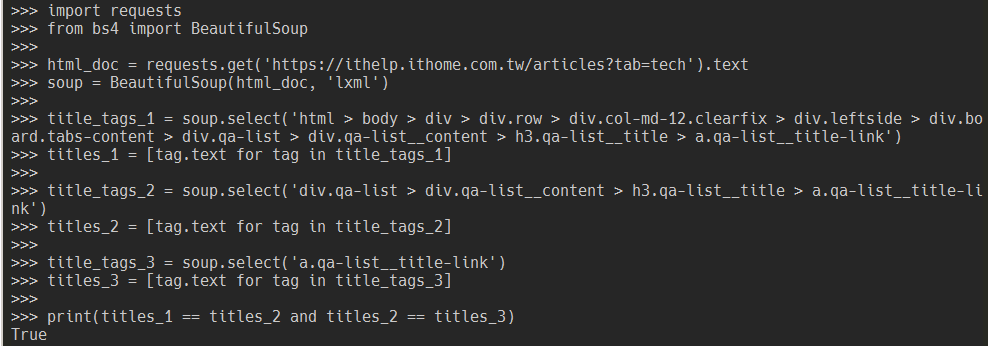
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles?tab=tech').text
soup = BeautifulSoup(html_doc, 'lxml')
title_tags_1 = soup.select('html > body > div > div.row > div.col-md-12.clearfix > div.leftside > div.board.tabs-content > div.qa-list > div.qa-list__content > h3.qa-list__title > a.qa-list__title-link')
titles_1 = [tag.text for tag in title_tags_1]
title_tags_2 = soup.select('div.qa-list > div.qa-list__content > h3.qa-list__title > a.qa-list__title-link')
titles_2 = [tag.text for tag in title_tags_2]
title_tags_3 = soup.select('a.qa-list__title-link')
titles_3 = [tag.text for tag in title_tags_3]
print(titles_1 == titles_2 and titles_2 == titles_3)
還記得在 Day 5 學到的另一種搜尋 HTML 結構的方法嗎?其實我個人是比較常用那種方式,覺得閱讀起來比 CSS 選擇器還要容易。把前面的程式改成另一種方式的話是這樣:
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles?tab=tech').text
soup = BeautifulSoup(html_doc, 'lxml')
# 先找到文章區塊
article_tags = soup.find_all('div', class_='qa-list')
for article_tag in article_tags:
# 再由每個區塊去找文章連結
title_tag = article_tag.find('a', class_='qa-list__title-link')
print(title_tag.text)
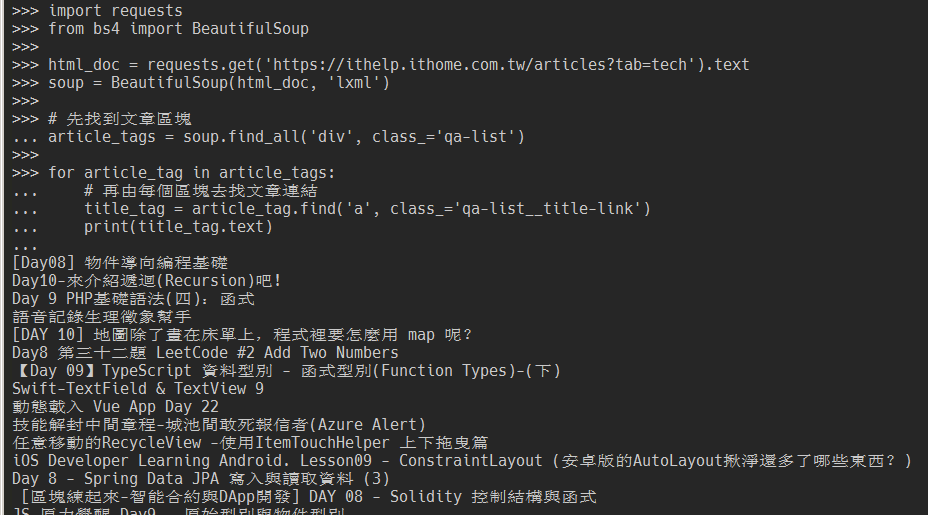
比較不一樣的地方是,這邊有先把文章區塊給抓出來,再跑一個迴圈從每個文章區塊往下找到文章標題連結。是因為過去常常需要這個區塊內的其他資訊(例如瀏覽數、發文時間),定位在外層的區塊可以方便從相同的位置往下找到其他資訊。
我們現在可以找出「第一頁」全部的文章標題了,但如果想要看到後面幾頁的文章怎麼辦?明天就會嘗試在程式裡換頁囉!
最後1支程式如下"直接定位到文章連結"不是更簡潔些嗎?
article_tags = soup.find_all('a', class_ = 'qa-list__title-link')
for article_tag in article_tags:
print(article_tag.text)
Sorry!沒注意到"因為過去常常需要這個區塊內的其他資訊"這句話。

