今天我們來討論一下Overfit以及Underfit的議題 (也是面試很喜歡討論的議題)。針對Overfit跟Underfit我們可以透過下圖很直接了斷的看資料與所學習到的模型的關係。Overfit的話,就是模型學到太好,太fit training data。在看training data的結果時,您可能會誤判認為他train的很好。其原因為generation不好。當testing data預測的時候,會使的預測結果非常差。面對Underfit的問題時,主要就是Model針對training data就學不起來,導致不管在training set或者testing set都得到不佳的效果。而最好的結果就是圖中間的Good Fit,針對Training set或者Testing set都有很好的結果。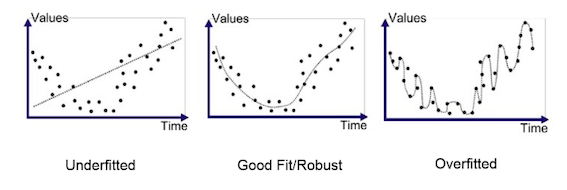
source
針對所面臨的問題,大家可以透過Tesnsorflow playground 來模擬training的情境。(Ex: Overfit:故意疊非常多層layer,反之Unerfit可能就使用一層等等)。
其實這兩個問題剛好是正反兩面,因此面對這類問題時,所想的解決方案其實可以歸納為2類。
資料 or 特徵(Feature):
當面臨Overfit的時候,我們可以嘗試想辦法增加資料(Ex:Data Augmentation),或者做一些特徵工程(Feature engineering)。將一些不必要的特徵去除或者嘗試一些降維度方法(Ex:PCA, t-SNE...等等)。反之亦然,面對Underfit的時候,可以嘗試分析是否因為太多Outlier,在和Domain expert討論後,看是否刪除或者做其他的處置。針對特徵的部分,可以嘗試去增加一些新的feature,開個meeting,大家brainstorming一些新的feature。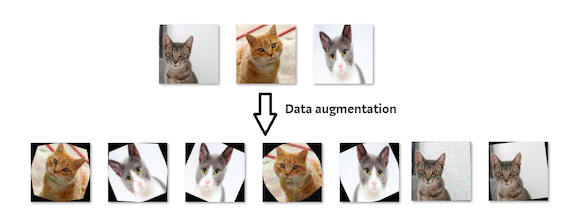
Source
模型:
簡單來說,Underfit的話,可以改使用較為複雜的模型,或者把模型複雜度提高 (Ex: 層數增加)。針對Overfit的話,可以使用較為簡易的模型或者把模型複雜度降低 (Ex: 層數降低)。此外,有一些參數是我們可以調整來降低Overfit,或者當Underfit的時候,可以降低這些參數。
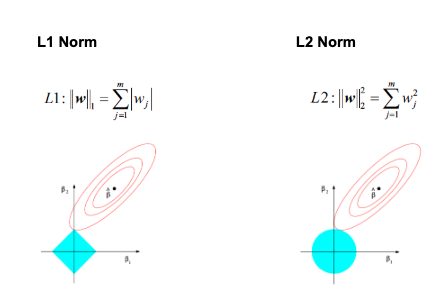
Regularization (L1 / L2):
為了降低模型複雜度,Regularization會在loss function上加入懲罰項(Penalty),來限制模型中的權重,降低權重或者變為0。
Dropout:
簡單來說,經過dropout的layer,會隨機"隨機”消除neuron,來學習。其精神就是希望透過此方法,來降低模型複雜度,當沒有被消除的neuron,則會需要花較多力量來learing。因此,Dropout也可能會造成網路的稀疏性。而現在有部分的人提出利用Batch normalization取代Dropout,使用BN會比使用Dropout好。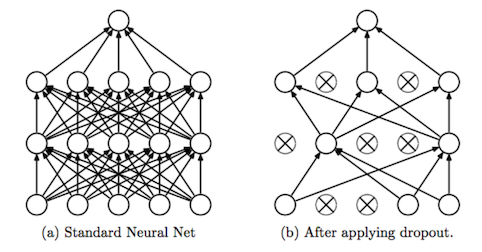
source
Batch Normalization:
BN主要是在進行mini-batch training的時候,依各個batch來進行normalization (x - batch mean / stdv(batch))。其優點像是收斂速度較快、不需tune參數、降低overfiting以及減少gradient exploding or vanishing gradient。而目前看起來TF2.0 BN有部分有雷,到時候有踩雷再和大家聊聊。
source
今天說明完了overfit跟underfit,這也是面試很常會被提出討論的問題。若我有任何遺漏或者有些更好的方法大家可以提出來討論。感謝大家漫長閱讀~明天預計會來討論Tensorflow的視覺化 - Tensorboard。


