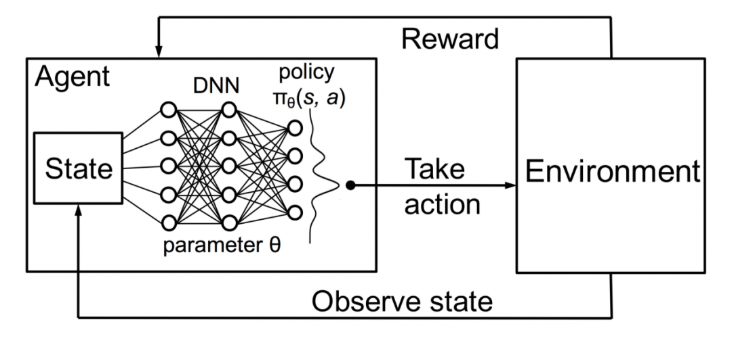
昨天已經簡單介紹了 RL、以及 DQN。今天我們來實作增強式學習中的 Deep Q Network 預測股票 (TSMC,俗稱 十萬青年十萬肝,GG輪班救台灣)。我們再看一次昨天的DQN架構
在DQN中,我們要記錄各個State,並放入DNN去學習一個 Q table (記錄歷史操作記錄)。在Output 一個 Action與 Environment 互動。
DQN - 更新公式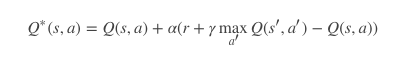
DQN - Loss Function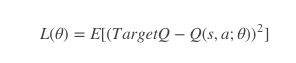
接下來,我們就來實作 DQN 應用於 TSMC 股票操作
首先我們先來 Load data ,這次我們所使用的是 pandas_datareader 來取得股票資料
import pandas_datareader as data_reader
stock_name = "TSM"
data_reader.DataReader(stock_name, data_source="yahoo").head()
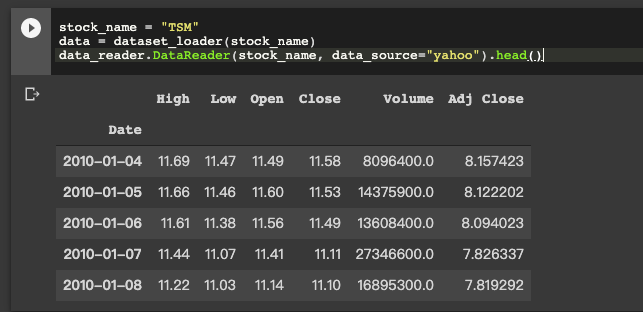
這次我們所使用的會是 Close 收盤價做為價格買賣使用。
在DQN裡面會有紀錄 庫存 以及 Q-table (memory) 來記錄過去的action。針對state (狀態) 的部分,我們會寫一個function 來 create。而 Window_size是指你要參考多少天歷史資料 (Ex: 前10天資料)。而狀態機率會以 sigmoid(今天價格 - 昨天價格)。
def state_creator(data, timestep, window_size):
starting_id = timestep - window_size + 1
if starting_id >= 0:
windowed_data = data[starting_id:timestep+1]
else:
windowed_data = - starting_id * [data[0]] + list(data[0:timestep+1])
state = []
for i in range(window_size - 1):
state.append(sigmoid(windowed_data[i+1] - windowed_data[i]))
return np.array([state])
Model 的部分,因為我們是操作股票,所以並非和一般玩遊戲可能使用CNN。
def model_dnn(self):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=16, activation='relu', input_dim=self.state_size))
model.add(tf.keras.layers.Dense(units=32, activation='relu'))
model.add(tf.keras.layers.Dense(units=64, activation='relu'))
model.add(tf.keras.layers.Dense(units=128, activation='relu'))
model.add(tf.keras.layers.Dense(units=self.action_num, activation='linear'))
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=1e-3))
return model
(* action_num = 可操作數量 , Ex: 買進、賣出、等候)
在 batch_train裡面,我先會先從 memory 裡面拿出先前操作的動作。並計算 reward ,更新及計算loss。
def batch_train(self, batch_size):
batch = []
# get pervious action
for i in range(len(self.memory) - batch_size + 1, len(self.memory)):
batch.append(self.memory[i])
for state, action, reward, next_state, done in batch:
reward = reward
if not done:
reward = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
target = self.model.predict(state)
target[0][action] = reward
self.model.fit(state, target, epochs=1, verbose=0)
接下來就可以train了,在 train 整個 period ,會把每個action的處理方法寫出來。像是action ==1的時候,會買股票,這時候我們就會將庫存放入queue裡面。action==2的時候,會賣出,這時候就會計算reward,並把庫存清出
if action == 1: #Buying
trader.inventory.append(data[t])
print("DQN Trader bought: ", stocks_price_format(data[t]))
elif action == 2 and len(trader.inventory) > 0: #Selling
buy_price = trader.inventory.pop(0)
reward = max(data[t] - buy_price, 0)
total_profit += data[t] - buy_price
完整的 tf 2.0 有放在 Colab 上,大家可以參考看看。
今天看完了 增強式學習,明天是鐵人賽最後一天,來好好想想明天要用什麼來結束這次的鐵人賽。
感謝大家漫長收看~
請問state使用sigmoid了話,對於高低價股票,是不是表達不是很好呢?有沒有其它表達state的方式呢?
還有就題主所知,RL目前對於量化交易是可用的技術嗎?還是還停留在實驗階段?