通常蒐集的資料範圍不會只有文章標題和內文,還會有作者、發文時間、標籤,甚至瀏覽數、回文等等比較詳細的資訊。今天先來抓取比較簡單的幾個資訊吧。
昨天我們抓內文的時候,是直接使用 div.markdown__style 這個選擇器,在 Day 9 有提到我們可以先把元素定位在外層一點的地方,這樣後續比較好閱讀程式碼,執行起來也會比較快。
以 iT 邦幫忙來說,我會建議先把元素定位在 div.leftside,這樣不管是要抓原文或者下面的回文都可以從這邊開始。
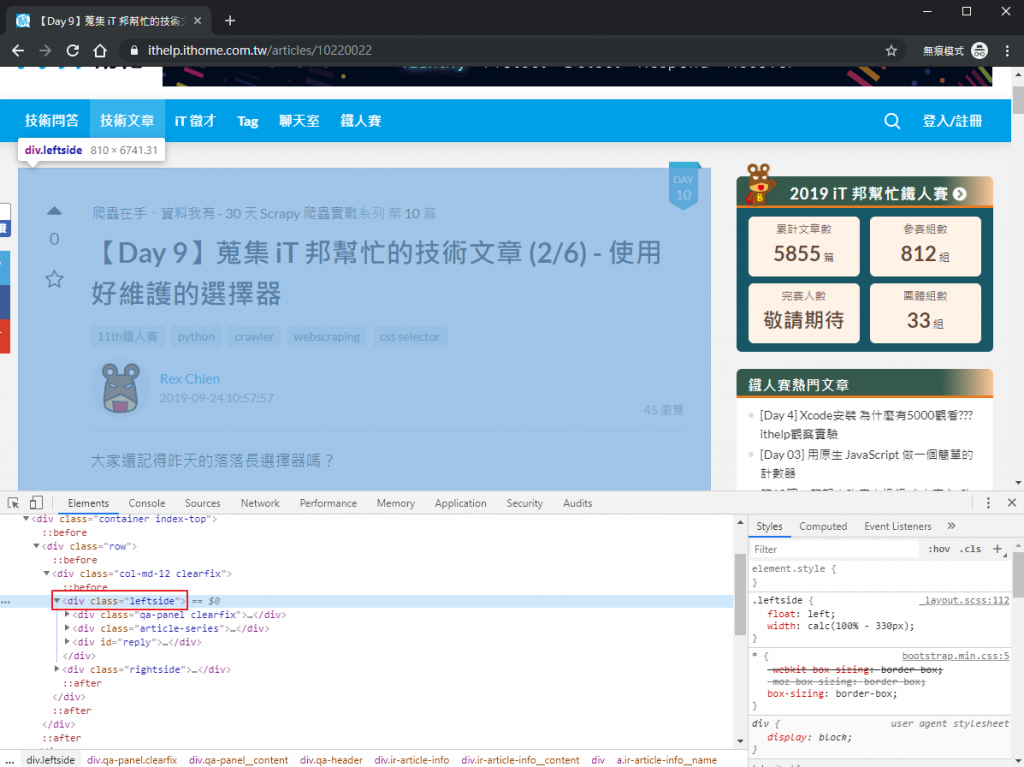
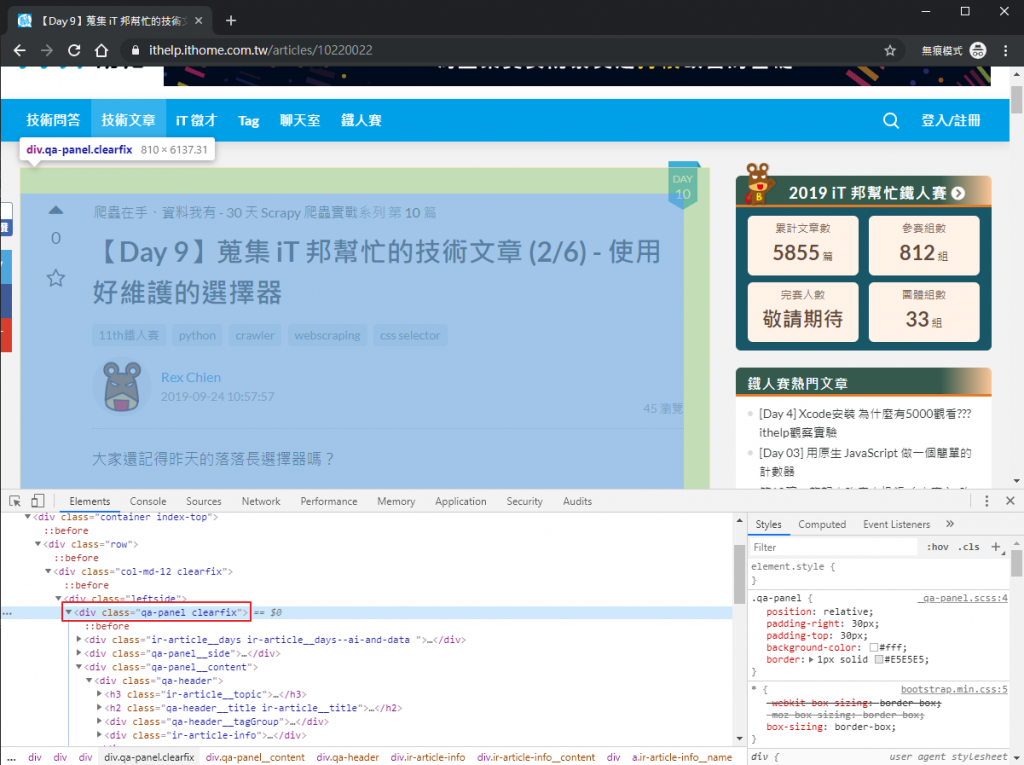
而要抓原文資訊時,就可以定位在 div.qa-panel,再根據要抓取的目標來往下找。
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles/10220022').text
soup = BeautifulSoup(html_doc, 'lxml')
leftside = soup.find('div', class_='leftside')
original_post = leftside.find('div', class_='qa-panel')
雖然直接用 a.ir-article-info__name 就可以抓到作者名稱了,但這邊建議先定位在 div.qa-header,因為這個區塊包含了大部分我們要的資訊。
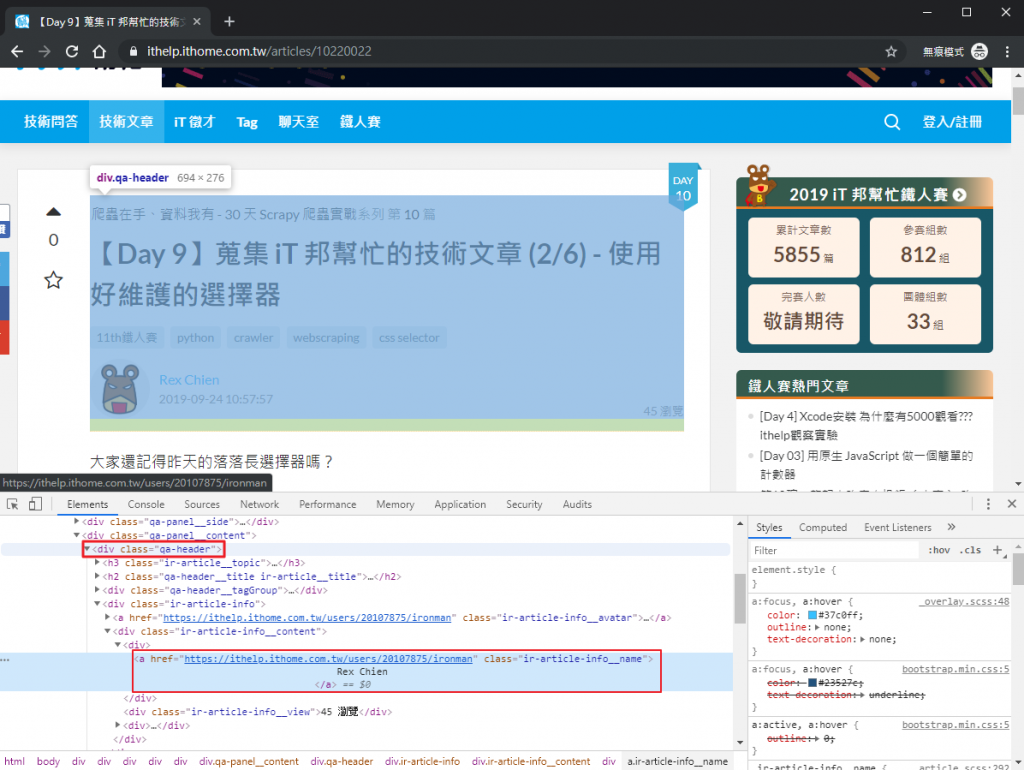
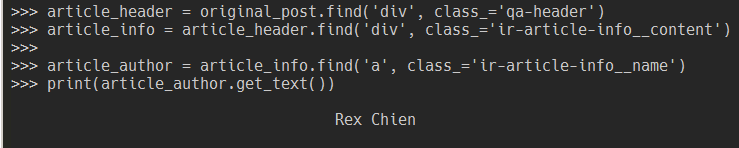
article_header = original_post.find('div', class_='qa-header')
article_info = article_header.find('div', class_='ir-article-info__content')
article_author = article_info.find('a', class_='ir-article-info__name')
print(article_author.get_text())
這邊會發現作者名稱前後有一堆空白,可以用 article_author.get_text(strip=True) 或 article_author.get_text().strip() 處理掉,通常取文字內容時也建議要這樣做。
剛剛有先偷偷存一個 article_info 就是為了抓發文時間用的,因為 a.ir-article-info__time 元素就在裡面。
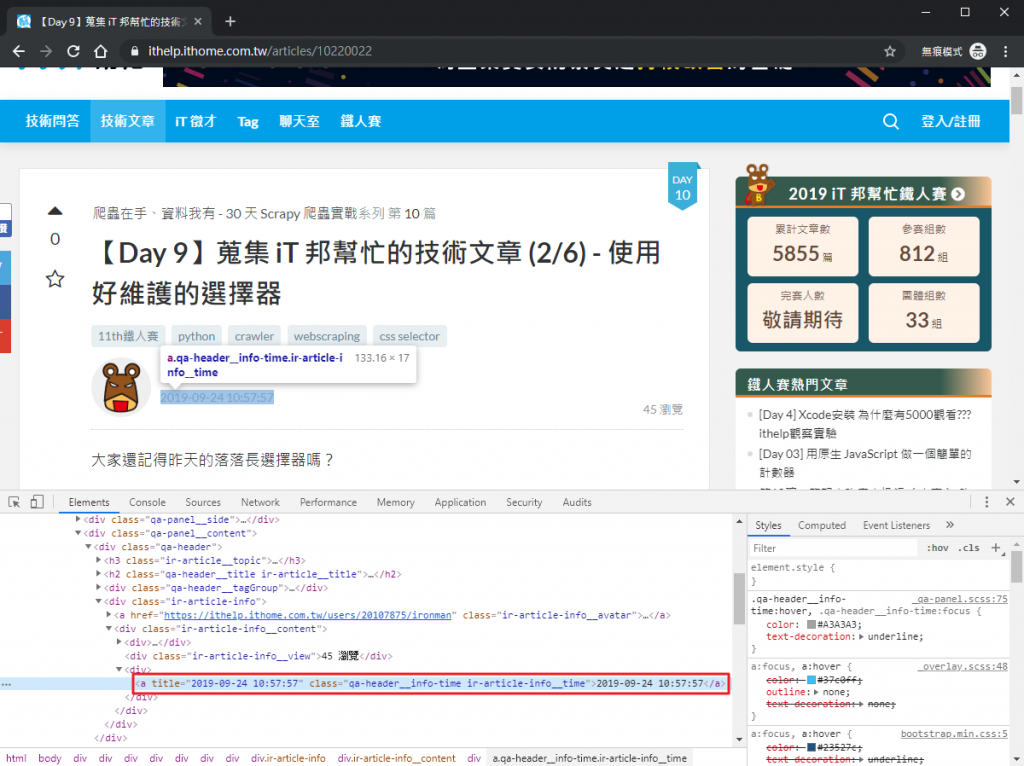
from datetime import datetime
published_time_str = article_info.find('a', class_='ir-article-info__time').get_text(strip=True)
published_time = datetime.strptime(published_time_str, '%Y-%m-%d %H:%M:%S')
print(published_time)
因為每個網站的時間顯示格式都不太一樣,我個人習慣先轉換成 Python 的 datetime 物件,之後再視情況處理。

元素位置在我們一開始存的 article_header 底下,要抓的是 div.qa-header__tagGroup 底下每一個 a.tag 的文字。
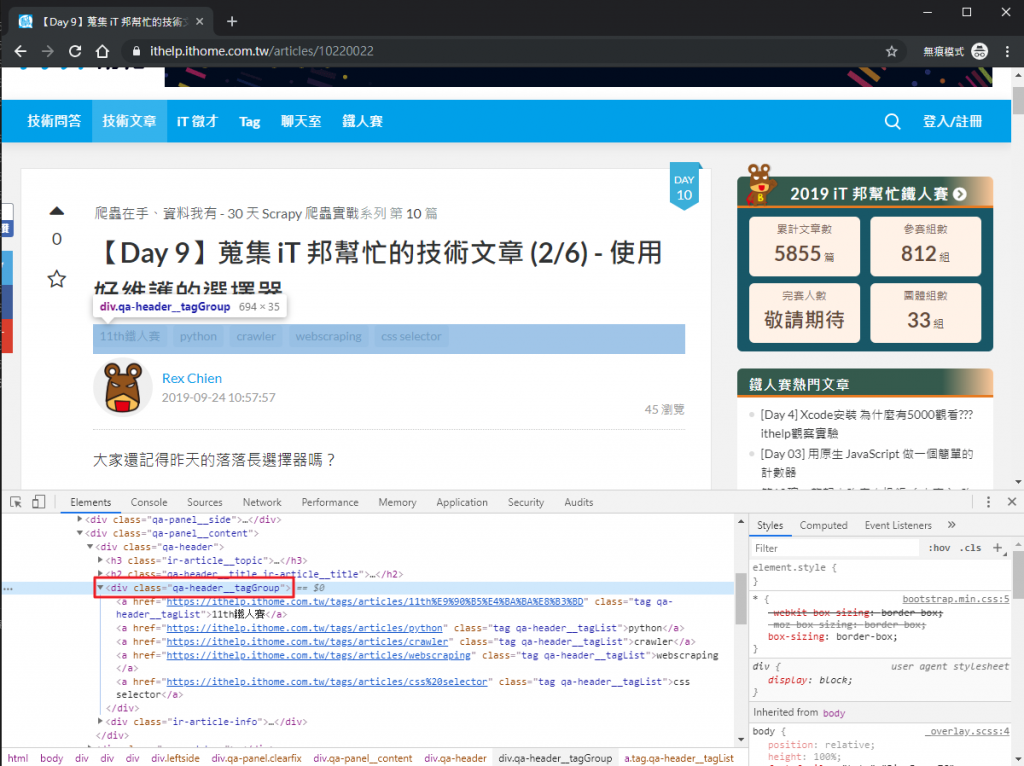
tag_group = article_header.find('div', class_='qa-header__tagGroup')
tags_element = tag_group.find_all('a', class_='tag')
tags = []
for tag_element in tags_element:
tags.append(tag_element.get_text(strip=True))
print(tags)
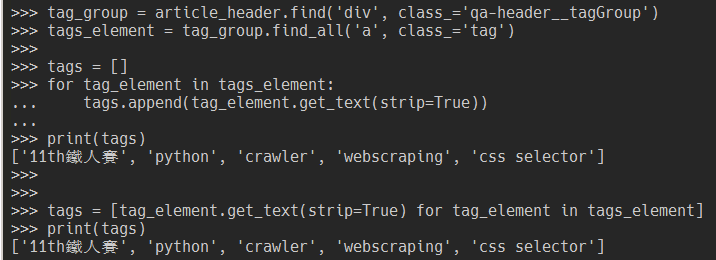
或者用 pythonic 的寫法。
tags = [tag_element.get_text(strip=True) for tag_element in tags_element]
print(tags)
元素位置在 article_info 底下,要抓的是 div.ir-article-info__view 標籤的文字內容。
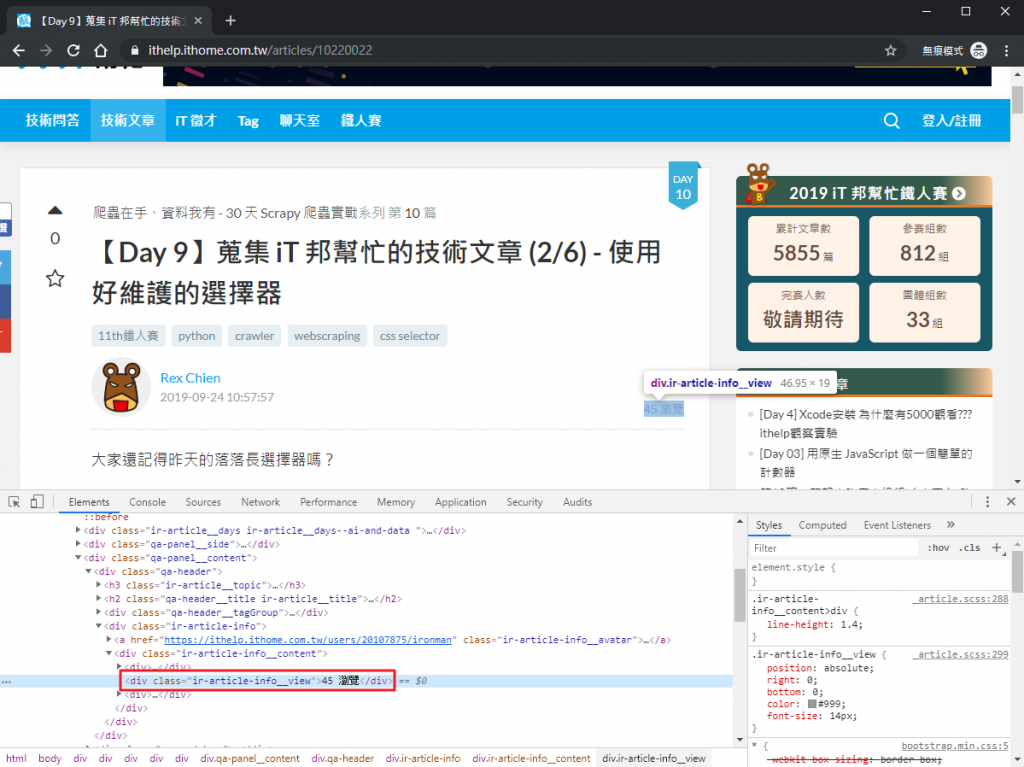
view_count = article_info.find('div', class_='ir-article-info__view').get_text(strip=True)
print(view_count)

注意到我們取到的文字是47 瀏覽,如果只要數字的部份的話有兩個方式處理:
瀏覽」字串移除(注意有個空白)view_count_str = article_info.find('div', class_='ir-article-info__view').get_text(strip=True)
# (1)
view_count = int(view_count_str.replace(' 瀏覽', ''))
print(view_count)
# (2)
import re
view_count = int(re.search('(\d+).*', view_count_str).group(1))
print(view_count)
整理今天完整的原始碼如下:
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
html_doc = requests.get('https://ithelp.ithome.com.tw/articles/10220022').text
soup = BeautifulSoup(html_doc, 'lxml')
leftside = soup.find('div', class_='leftside')
original_post = leftside.find('div', class_='qa-panel')
article_header = original_post.find('div', class_='qa-header')
article_info = article_header.find('div', class_='ir-article-info__content')
# 作者
article_author = article_info.find('a', class_='ir-article-info__name').get_text(strip=True)
# 發文時間
published_time_str = article_info.find('a', class_='ir-article-info__time').get_text(strip=True)
published_time = datetime.strptime(published_time_str, '%Y-%m-%d %H:%M:%S')
# 文章標籤
tag_group = article_header.find('div', class_='qa-header__tagGroup')
tags_element = tag_group.find_all('a', class_='tag')
tags = [tag_element.get_text(strip=True) for tag_element in tags_element]
# 瀏覽數
view_count_str = article_info.find('div', class_='ir-article-info__view').get_text(strip=True)
view_count = int(re.search('(\d+).*', view_count_str).group(1))

