除了原文外,回文常常也是重要的資料來源之一(特別是論壇類型的網站),所以今天來嘗試把回文也抓回來吧!
技術文章有回文的不多,找到 30天30碗平民魯肉飯完食! 這個看了肚子會很餓的系列,第一篇剛好有很多留言 :P
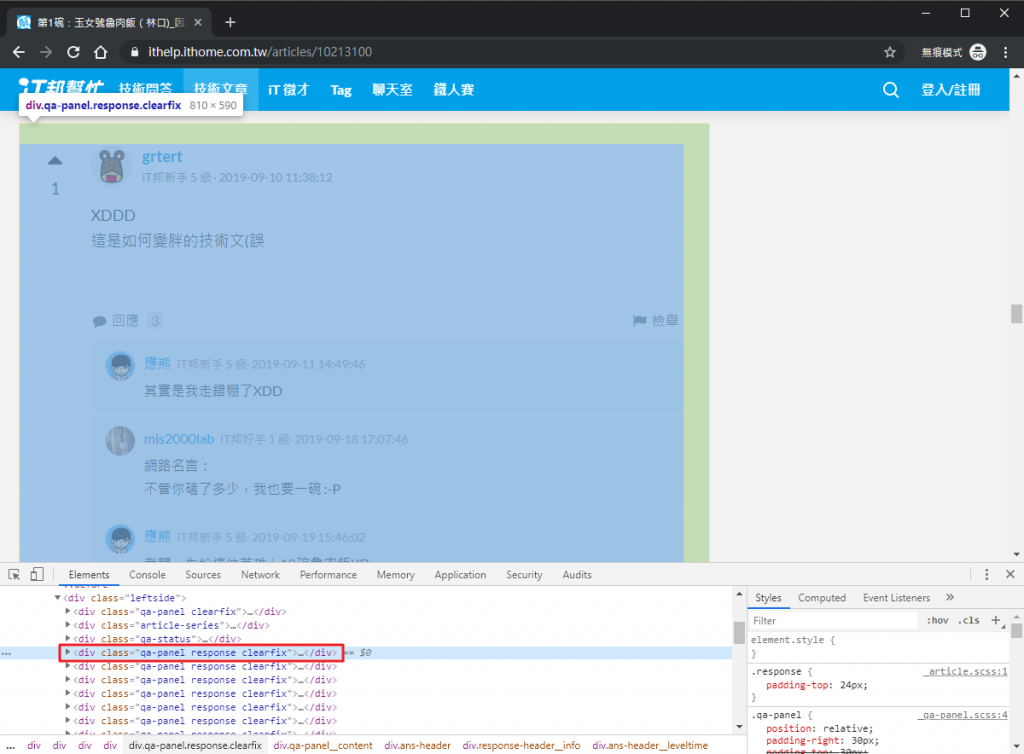
一樣我們要先在畫面上找到回文的區塊,觀察後可以發現 div.response 可以取得每個回文最外層的元素。
用
div.qa-panel.response也是可以,但如果只用一個 class 就可以了那何樂而不為呢
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles/10213100').text
soup = BeautifulSoup(html_doc, 'lxml')
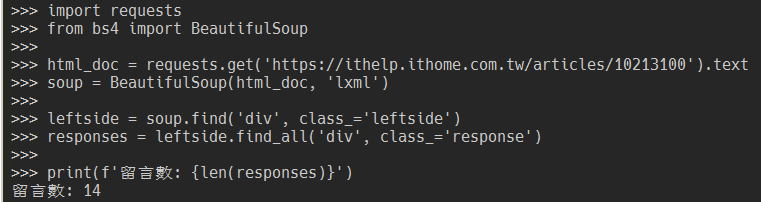
leftside = soup.find('div', class_='leftside')
responses = leftside.find_all('div', class_='response')
print(f'留言數: {len(responses)}')
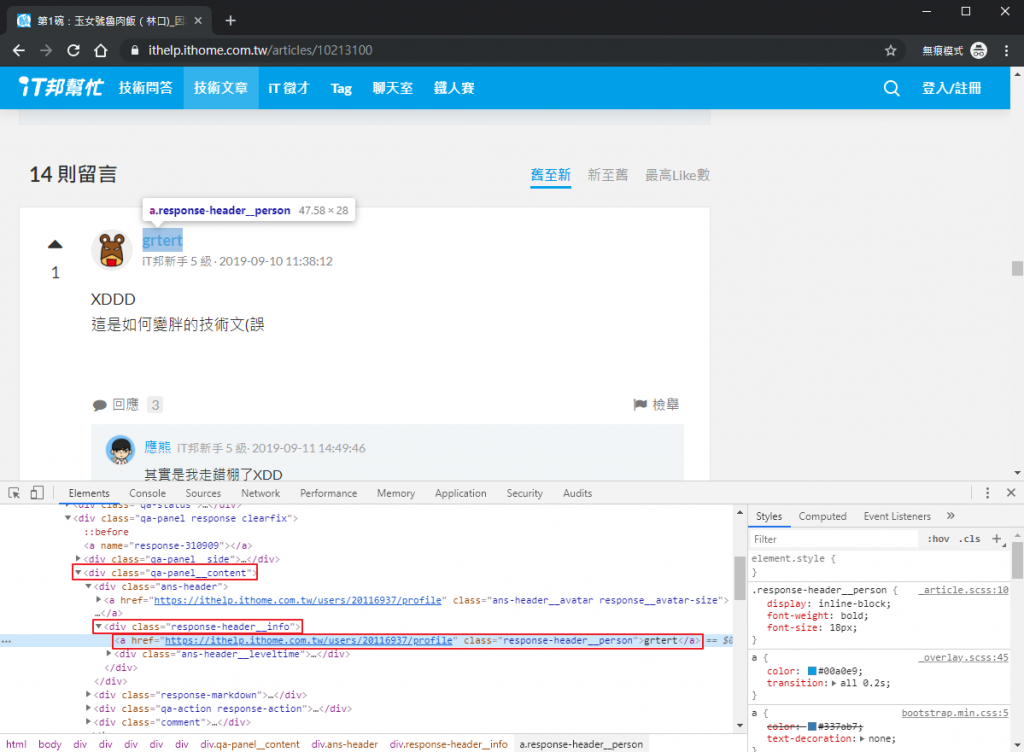
先找到 div.qa-panel__content 方便之後找回文內容,再找到 div.response-header__info 方便之後找回應時間,最後就可以找到 a.response-header__person 取得回文作者名稱了。
如果確定上層區塊中沒有其他相同選擇器的元素,其實都可以直接定位到目標元素,但我是覺得這樣分層來抓比較好維護就是了。
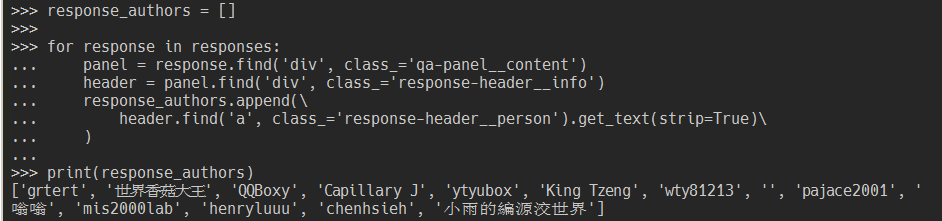
response_authors = []
for response in responses:
panel = response.find('div', class_='qa-panel__content')
header = panel.find('div', class_='response-header__info')
response_authors.append(\
header.find('a', class_='response-header__person').get_text(strip=True)\
)
print(response_authors)
在前面存的 header 元素底下的 a.ans-header__time。
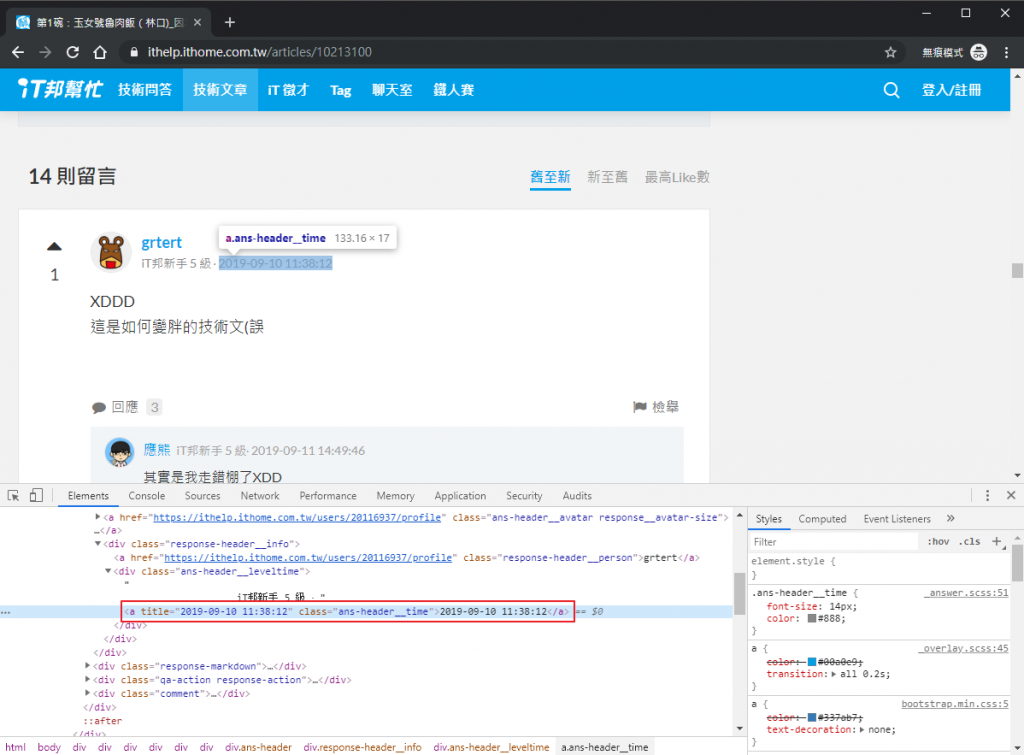
from datetime import datetime
response_times = []
for response in responses:
panel = response.find('div', class_='qa-panel__content')
header = panel.find('div', class_='response-header__info')
# ...略過前面抓作者的部分
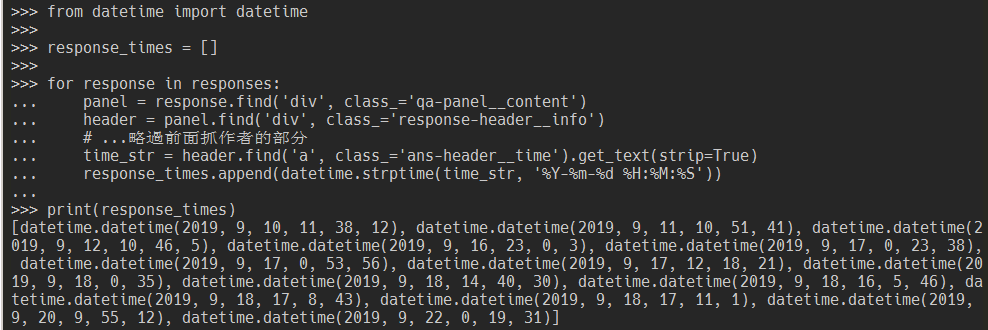
time_str = header.find('a', class_='ans-header__time').get_text(strip=True)
response_times.append(datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S'))
print(response_times)
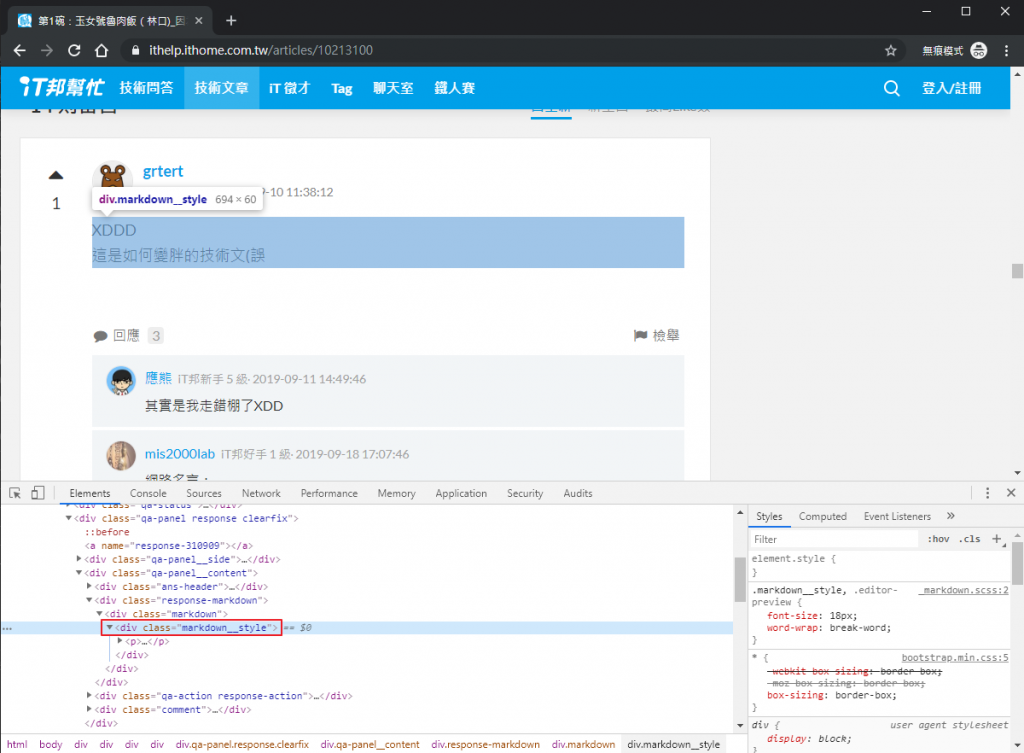
看到現在大家應該都很會找元素了吧,一定一眼就能看出來回文內容就是在 panel 元素的 div.markdown__style 中!
response_contents = []
for response in responses:
panel = response.find('div', class_='qa-panel__content')
# ...略過前面抓作者和發文時間的部分
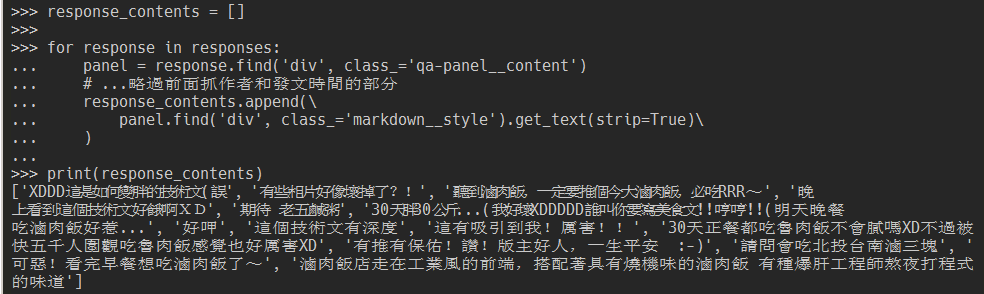
response_contents.append(\
panel.find('div', class_='markdown__style').get_text(strip=True)\
)
print(response_contents)
目前為止我們用了 response_authors、response_times 和 response_contents 三個 list 來存每則回應的作者、回應時間和內容。但通常不會用這個方式來存這些資料,而是會用一個 list,裡面放代表每則回應的 dict。修改後的完整程式如下:
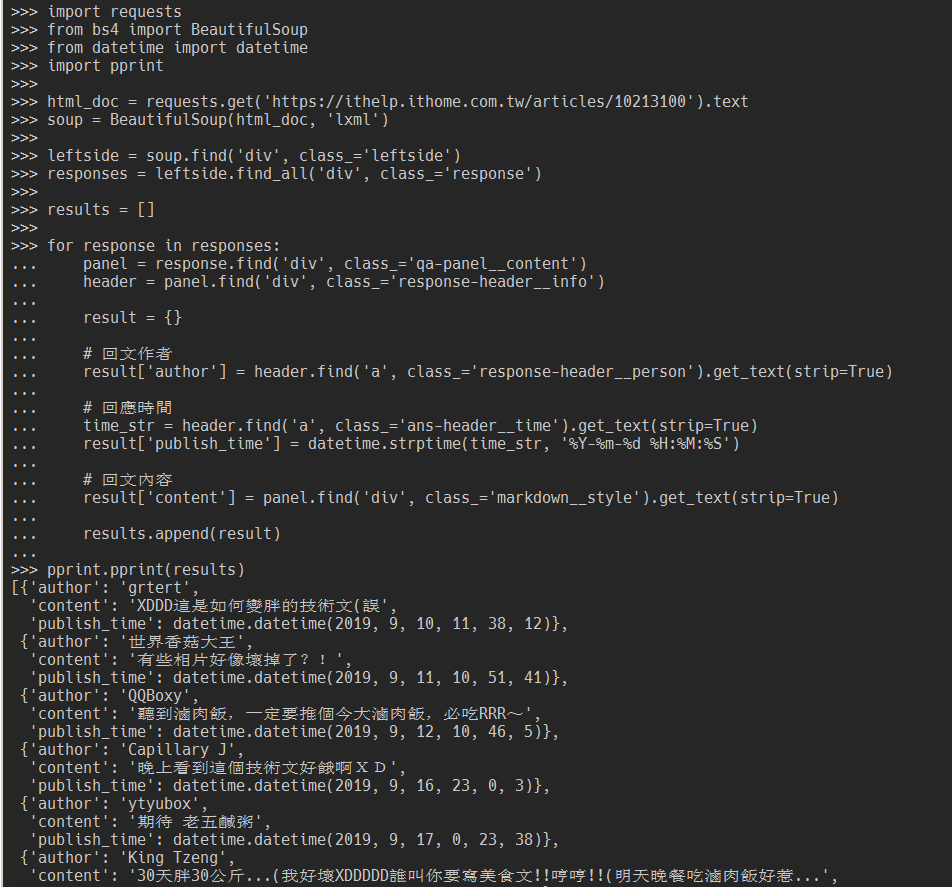
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import pprint
html_doc = requests.get('https://ithelp.ithome.com.tw/articles/10213100').text
soup = BeautifulSoup(html_doc, 'lxml')
leftside = soup.find('div', class_='leftside')
responses = leftside.find_all('div', class_='response')
results = []
for response in responses:
panel = response.find('div', class_='qa-panel__content')
header = panel.find('div', class_='response-header__info')
result = {}
# 回文作者
result['author'] = header.find('a', class_='response-header__person').get_text(strip=True)
# 回應時間
time_str = header.find('a', class_='ans-header__time').get_text(strip=True)
result['publish_time'] = datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
# 回文內容
result['content'] = panel.find('div', class_='markdown__style').get_text(strip=True)
results.append(result)
pprint.pprint(results)
到今天為止我們已經可以完整抓到 iT 邦幫忙每篇文章的內容了!但是目前這些變數都還只存在於 Python 執行環境中,把視窗關掉就會全部不見。抓回來的資料還是要能保存下來才有價值,接著幾天就來講講怎麼把這些資料持久化吧~

