今天我們來討論Deep learning經典的模型之一 - Convolutional Neural Network (CNN)的架構。目前CNN被大量使用的影像辨識的應用上 (Ex: 車牌辨識、人臉辨識等等)。以前用DNN做影像辨識的時候,會把pixel壓成一個一維度的特徵,但現在CNN的架構可以使用Convolutional layer來看圖片,對於在做影像辨識,除了參數量,或者效果都更勝於以前單純的DNN架構,也是一個Deep learnig模型的突破。而CNN經典的架構有像是: Le-Net, VGG, GoogleNet, ResNet, DenseNet 等等。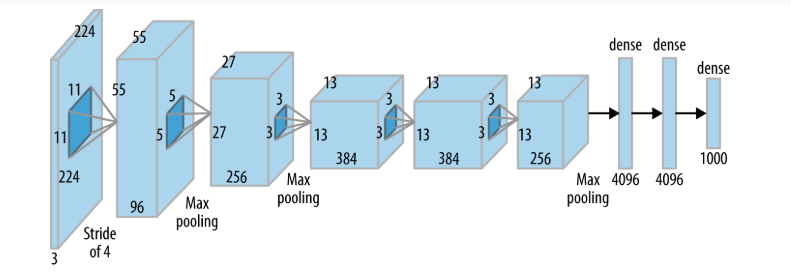
source
CNN的架構主要可分為幾個 Convolution 、 Pooling 、Flatten、 Fully Connected Feedfoward Network (FC)。
首先我們會input一個image,接下來會使用 Filter來偵測圖片裡的特徵 (Ex: 偵測圖裡面有沒有圓圈或者正方形),而Filter中的數值也是CNN中learnable的參數。接下來他會像下圖一樣一格一格的掃過所有圖片。而其中,若您像減少餐數量或者說覺得一張圖不需要一格一格掃,就可以設定stride的大小。若stride=2,則Filter會每兩個pixel才掃一次。而搜完後所得出來的結果我們會稱之為Feature Map。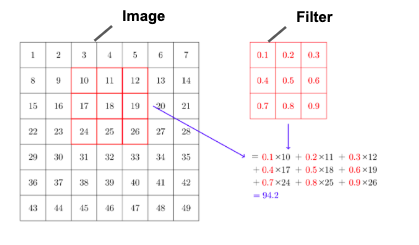
source
在tf api裡面常看到的這段就是Convolution
layers = tf.keras.layers.Con2D(4,kernel=5,strides=1,padding='same')
out = layers(x)
padding的話就是在資料周圍去補0,作用主要是去補足不夠的資料。也有人認為做padding可以提高圖像邊緣的資料量,而padding的方法有'same'跟'valid',兩種的做法不太一樣,因此在使用的時候要小心,確認是您所想像的方法。
換句話說就是subsampling,針對Feature Map做Subsampling。透過設定好的Pooling大小,針對Feature Map中的分割區域做Max值或者Mean值的操作。Pooling的動作可以萃取出較有價值的資訊量且可減少餐數量。但反之,透過Pooling也可說是會損失原有的資訊量。目前多數使用的都是MaxPooling。若想要從Maxpooling還原或者說想要放大的話可以使用tf.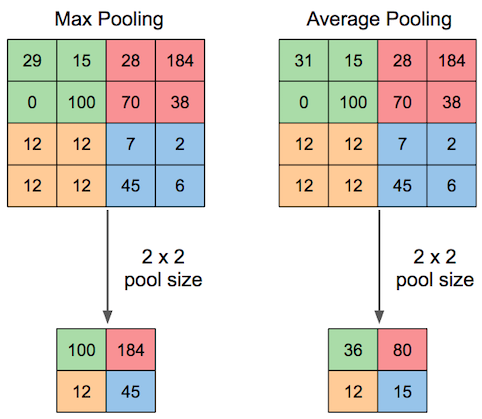
source
在CNN tf的api常看到的就是下面這類型的code
pooling = tf.keras.layers.MaxPool2D(2,strides=2)
out = pooling(x)
3.Flatten & FC:
簡單來說就是把資料壓平並傳輸到一個DNN的Fully Connected的網路架構裡。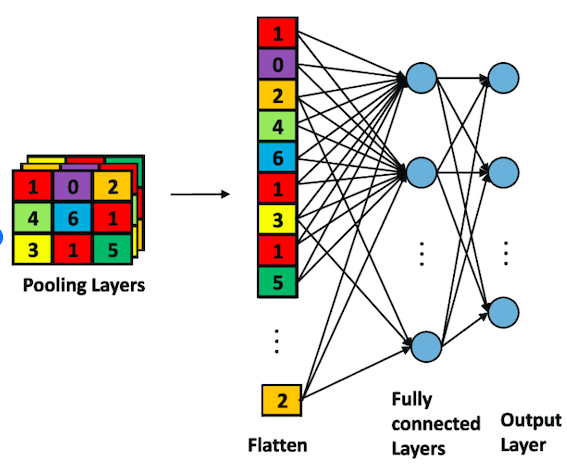
Source
這邊的話其實就跟前面最常看到的DNN一樣
tf.keras.layers.Dense(256,activation=tf.nn.relu)
總括來說CNN的架構可被簡易成下圖步驟,當一個image input的時候,會進入Convolution以及Pooling階段,而這兩個階段可能為一直重複,最後才壓平並input到一個Fully Connected的network裡面。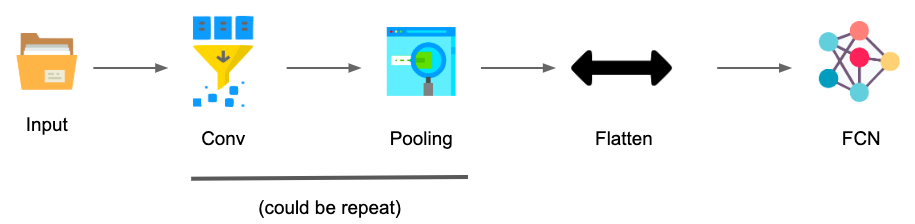
今天看完了經典之一的CNN架構,CNN已經被許多企業應用於影像辨識等場景,尤其是臉部辨識的應用。而科技業也開始應用CNN在預測或者說是在檢驗產線上的不良率。而CNN效果已經高於人工的檢驗水準。因此,CNN可說是一個非常成熟的模型。明天我們來時做一個CNN經典的架構。


