介紹
在開始介紹XGBoost之前,我們先來了解一下什麼事Boosting?
所謂的Boosting 就是一種將許多弱學習器(weak learner)集合起來變成一個比較強大的學習器(strong learner),大致上的核心思想就是「三個臭皮匠勝過一個諸葛亮」。
XGBoost ( Extreme Gradient Boosting ),是一種Gradient Boosted Tree(GBDT),每一次保留原來的模型不變,並且加入一個新的函數至模型中,修正上一棵樹的錯誤,以提升整體的模型。主要用於解於監督是學習,可以用於分類也可以用於迴歸問題
Tree Boosting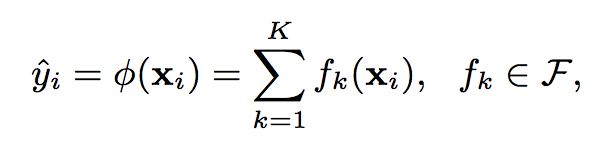
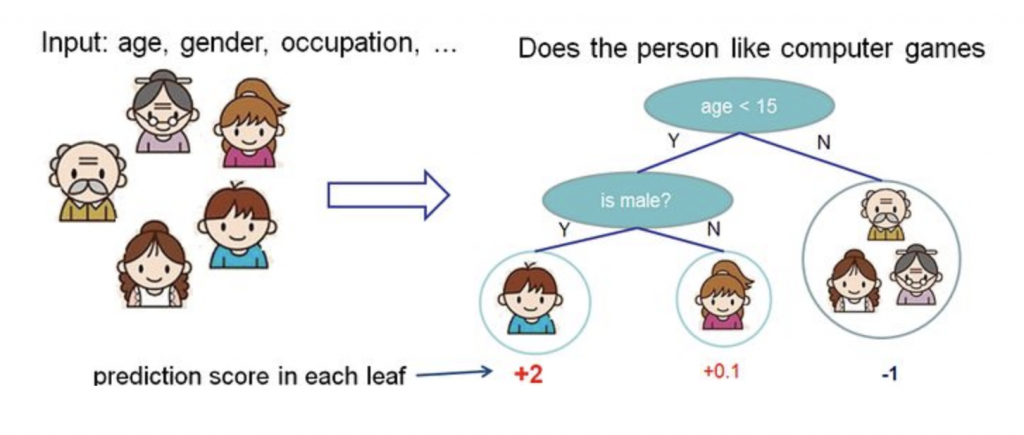
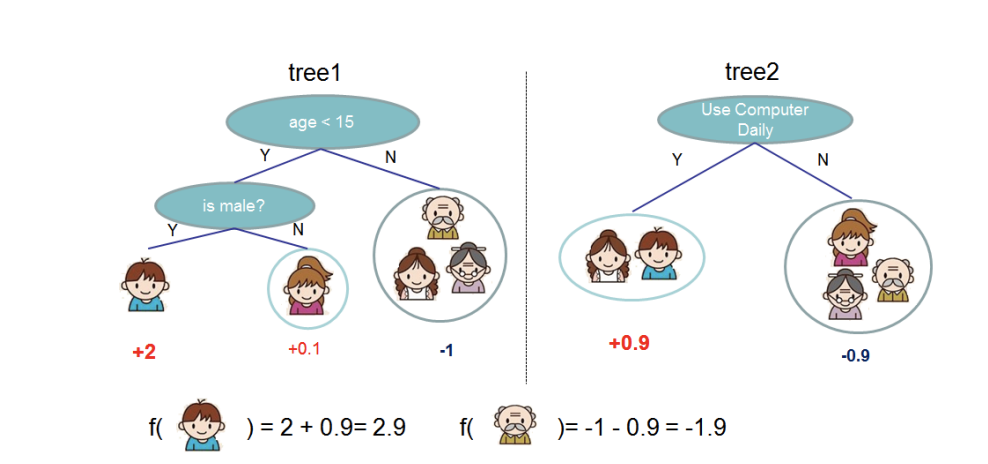
上面提到XGBoost是一組分類和回歸樹(classification and regression trees — CART),每一顆回歸樹的葉子都會對應到一組分數,這個分數作為之後分類的依據。上面的式子可以對應下面的圖片,所謂y^就是模型所計算出來的分數。
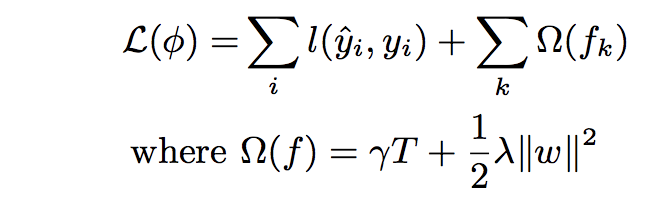
有學過機器學習的人應該可以知道,由上面的式子可以看到,L指的是loss function,式子後面加入一個懲罰項Ω,它可以避免我們的模型overfitting,幫助找到較好的模型。
優化模型最常使用的模型就是透過梯度來解決,但我們無法在一次訓練所有的樹,因此會透過增量訓練 (additive training) 的方式,每一步都是在前一步的基礎上增加一棵樹來做修正。
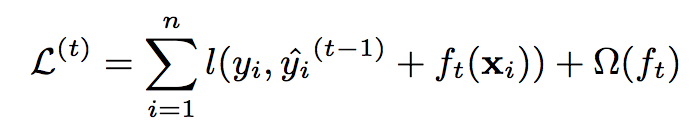
我們把loss function展開來看就會變成:
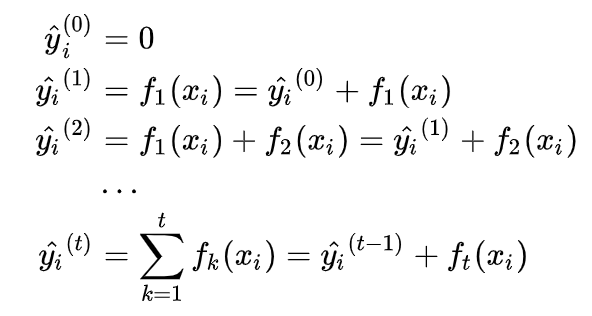
再將loss function以MSE表示:
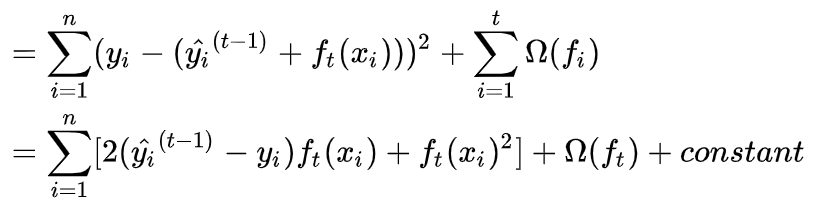
再利用泰勒展開式做展開 :
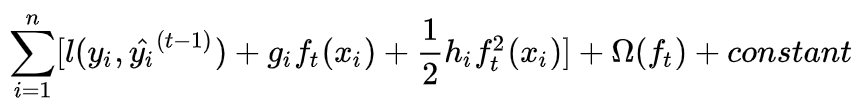
其中gi及hi定義如下:
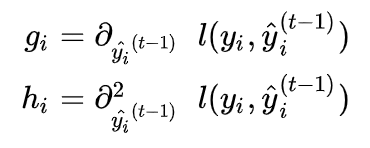
把常數項拿掉即可得到下面式子:
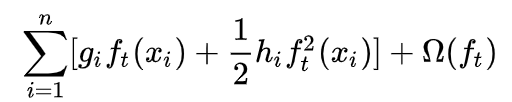
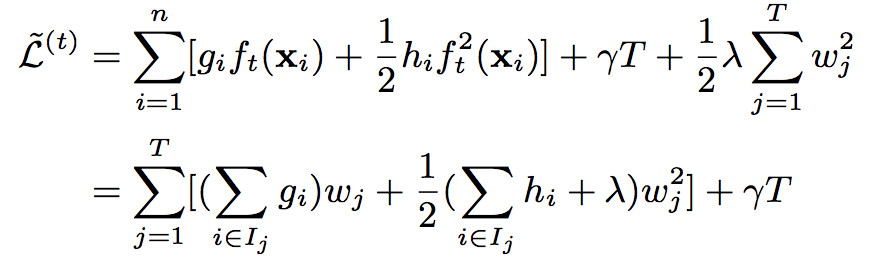
將上式重新整理後可得:
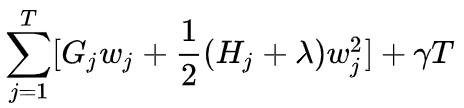
其中Gi及Hi分別為:
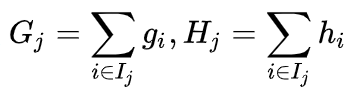
所以我們可以從上面的一元二次方程式得到:
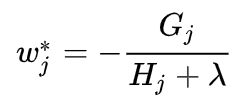
所以loss function為:
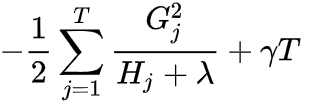
上面所得到的式子可以用來判斷一棵樹的好壞

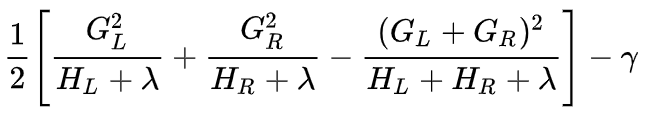
System Design:
在建構一棵樹時最耗時間的就是尋找特徵的劃分過程中,必須先將每一個特徵先做排序。為了減少排序的時間,所以採用block來存取數據。
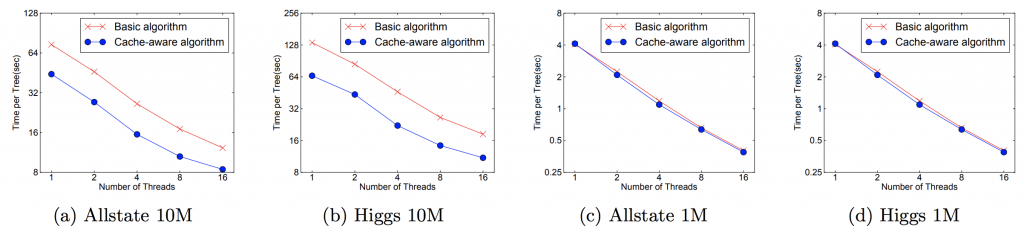
Cache-aware Access:
對於有大量數據或者說分佈式系統來說,我們不可能將所有的數據都放進內存裡面。因此我們都需要將其放在外存上或者分佈式存儲。但是這有一個問題,這樣做每次都要從外存上讀取數據到內存,這將會是十分耗時的操作。因此我們使用預讀取(prefetching)將下一塊將要讀取的數據預先放進內存裡面。其實就是多開一個線程,該線程與訓練的線程獨立並負責數據讀取。此外,還要考慮block的大小問題。如果我們設置最大的block來存儲所有樣本在k特徵上的值和梯度的話,cache未必能一次性處理如此多的梯度做統計。如果我們設置過少block size,這樣不能充分利用的多線程的優勢,也就是訓練線程已經訓練完數據,但是prefetching thread還沒把數據放入內存或者cache中。作者發現block size設置為2¹⁶個examples最好。
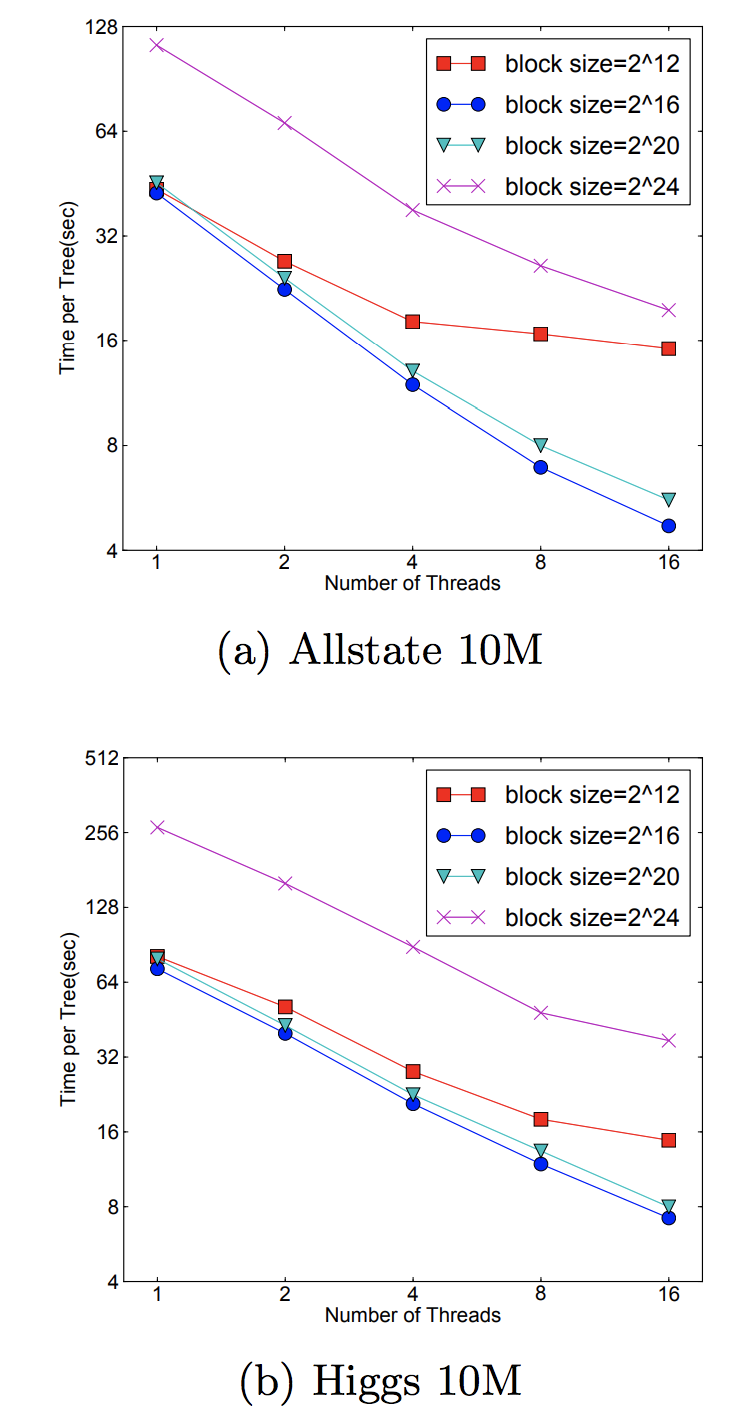
Blocks for Out-of-core Computation:
對於超大型的數據,不可能都放入放入內存,因此大部分都放入外存上。假如將數據存於外存上將帶來讀寫速度受限的問題。paper有提到兩種方法,一種是對數據進行壓縮存於外存中,到內存中需要訓練時再解壓,這樣來增加系統的吞吐率,儘管消耗了一些時間來做編碼和解碼但還是值得的。另一種就是多外存存儲,其實本質上就是分佈式存儲。
參考文獻


 iThome鐵人賽
iThome鐵人賽