這個章節要介紹如何對離群值做處理,以下是我參加機器學習百日馬拉松所練習的題目,因為簡單易懂,所以提供給想從入門的朋友參考。
所謂離群值就是,如果只有少數幾筆資料跟其他數值差異很⼤的值,這種情況標準化無法處理的時候,如下圖所示,即使做完標準化後,差異還是很大。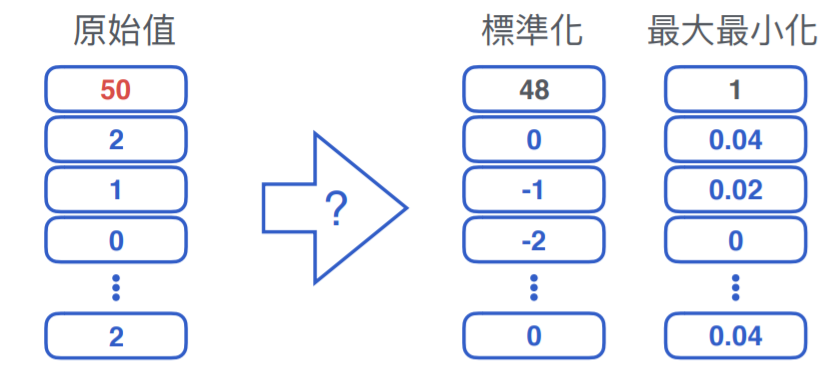
如果有上面這種情況發生時,有以下的處理方法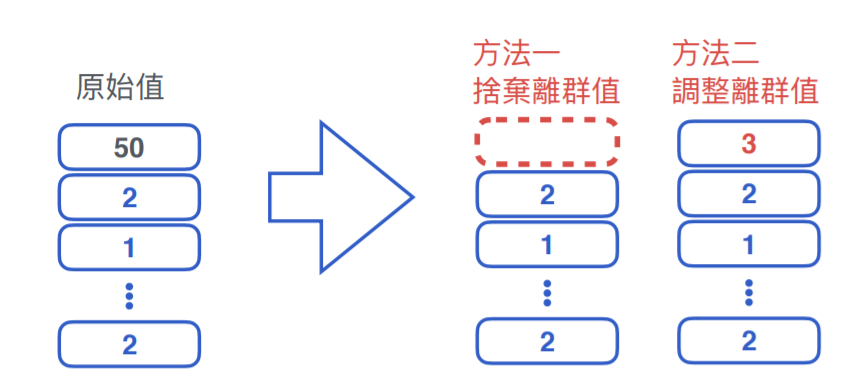
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
data_path = '../data/'
df_train = pd.read_csv(data_path + 'house_train.csv.gz')
train_Y = np.log1p(df_train['SalePrice'])
df = df_train.drop(['Id', 'SalePrice'] , axis=1)
df.head()

# 顯示 GrLivArea 與目標值的散佈圖
import seaborn as sns
import matplotlib.pyplot as plt
sns.regplot(x = df['GrLivArea'], y=train_Y)
plt.show()
# 做線性迴歸, 觀察分數
train_X = MMEncoder.fit_transform(df)
estimator = LinearRegression()
cross_val_score(estimator, train_X, train_Y, cv=5).mean()
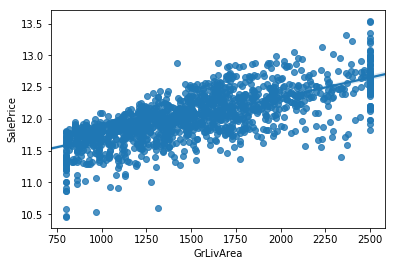
透過cross_val_score可以得到分數為0.8499092569205354
接下來將離群值去除之後再重複上面的步驟
# 將 GrLivArea 限制在 800 到 2500 以內, 捨棄離群值
keep_indexs = (df['GrLivArea']> 800) & (df['GrLivArea']< 2500)
df = df[keep_indexs]
train_Y = train_Y[keep_indexs]
sns.regplot(x = df['GrLivArea'], y=train_Y)
plt.show()
# 做線性迴歸, 觀察分數
train_X = MMEncoder.fit_transform(df)
estimator = LinearRegression()
cross_val_score(estimator, train_X, train_Y, cv=5).mean()
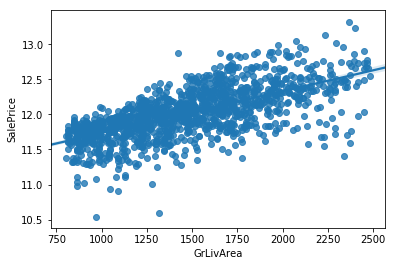
可以發現分數有明顯的上升,提高到0.8765027590764258

