一.事前動作
1.打開目標網頁(範例使用的是ptt電影版目錄)按下F12開啟開發人員工具
2.點進Network並重新整理網頁
3.index.html並找到headers裡的user-agent並複製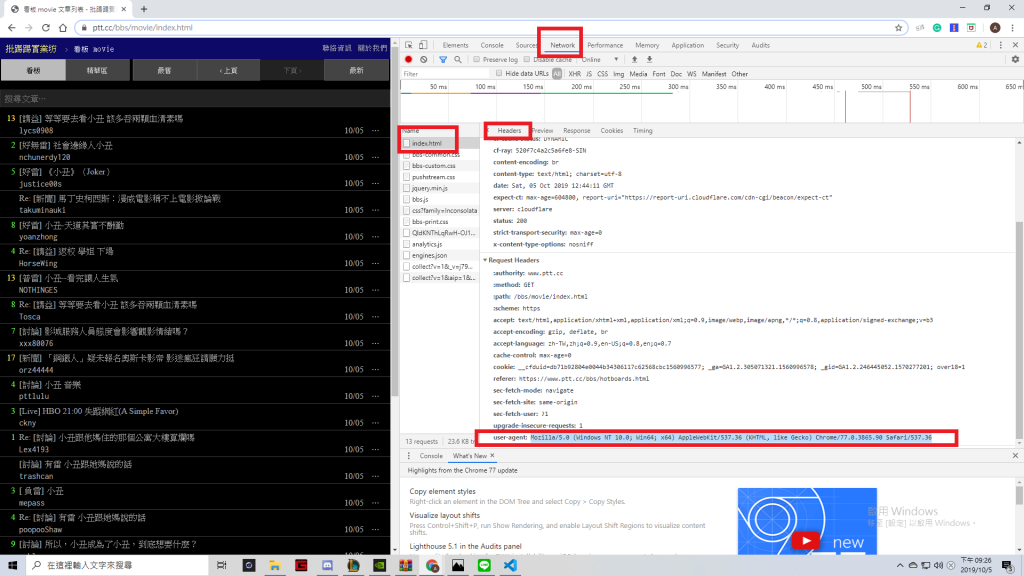
4.下載pip套件
5.在cmd中利用pip套件下載beautifulsoup4 (打入pip install beautifulsoup4)
二.開始實作
import urllib.request as req
url = "https://www.ptt.cc/bbs/movie/index.html"
request = req.Request(url,headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"})
with req.urlopen(request) as response:
data = response.read().decode("utf-8") #讀取原始碼
import bs4 #import beautifulsoup4
root = bs4.BeautifulSoup(data,"html.parser")
titles = root.find_all("div",class_="title") #找到所有被<div></div>包住的title
for title in titles: #利用for迴圈印出所有title
if title.a !=None: #在ptt中的tile會被<a></a>所包住,如果文章被刪除則否
print(title.a.string) #印出還存在的文章標題
#執行結果會印出ptt電影版的各個文章標題

