昨天提到了驗證集的存在以及Seaborn的小小介紹,今天會利用到一些Seaborn的技巧去畫圖觀察數據!
那就直接開始吧!
相關係數可以看出各個資料之間的相關度(用一個數字來表示兩數的相關度),就像是之前提到的,房價高低一定和坪數大小有一定程度上的關係,這時相關係度就會接近1;但如果是賣出的月份或者是日期也有出現在數據中的話,對於房價似乎不是那麼的重要,相關係數就可能會小於0.5,甚至接近0,這樣子的數據就不是我們要的。
那我們在程式碼會用到的相關係數分析是Pearson相關,Pearson相關是統計學常見的分析數據的方法,那Pearson相關係數的範圍是-1~1,"-"代表負相關(x值越大;y值越小),反之,"+"代表正相關(x值越大;y值越大)。但我們在看相關度的時候通常會以絕對值作為依據,當加上絕對值後數值越接近1表示x和y的關係越像在一條線上(正負只是方向不同,正是左下往右上;負是左上往右下),所以當絕對值加上去後,越接近1表示越跟y相關!也就是說會利用這個相關係數來判別房價資料內是不是有不太相關的數據卡在那,這樣會影響我們在訓練模型的狀況,所以通常會把相關係數小於0.5拿掉不去考慮。
下面先用簡單的數據讓大家知道要怎麼去撰寫,再開始帶入原本的房價!
1.創建簡單的數據
import numpy as np
import pandas as pd
x = np.random.randint(0, 100, 10)
y = 5 * x
z = np.random.randint(0,100,10)
dataframe = pd.DataFrame({'x':x,'y':y,'z':z})
dataframe
輸出: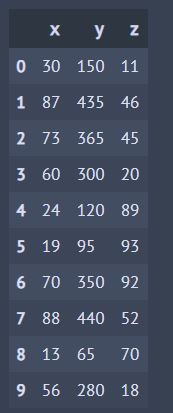
2.利用corr()找出Pearson相關
import matplotlib.pyplot as plt
import seaborn as sns
df =dataframe.corr() #計算相關係數
plt.subplots(figsize=(10, 10)) # 設置長寬尺寸大小
sns.heatmap(df, annot=True, vmax=1, square=True, cmap="Blues")
#1.丟入的資料 2.是否輸出熱力圖數值大小 3.最大值顯示4.變成正方形5.要什麼顏色
plt.show()
輸出: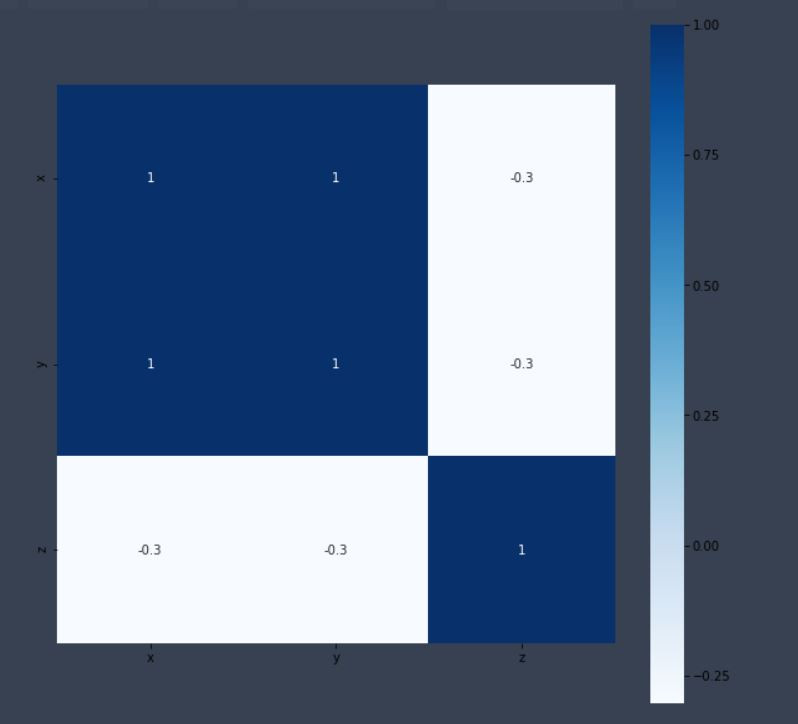
從上圖中可以看出x和y的相關度很高,這是因為我一開始就讓他們成一條線的關係,那z就是一組隨便的亂數,所以很明顯的可以看出,z和x、y之間的關係不大,絕對值是小於1的!
import seaborn as sns
trian_corr =df_train.corr() #計算相關係數
plt.subplots(figsize=(30, 10)) # 設置長寬尺寸大小
sns.heatmap(trian_corr, annot=True, vmax=1, cmap="Blues")
輸出:
對我們來說有很多的相關係數我們並不在乎,我們只在乎其他人對SalePrice的相關係數。
high_corr = trian_corr.index[abs(trian_corr["SalePrice"])>0.6]
#abs是取絕對值的意思
#abs(trian_corr["SalePrice"])>0.6 這句的意思是與SalePrice有關的係數>0.6的判別式,它會輸出True(大於0.6)或是False
#abs(trian_corr["SalePrice"])>0.6 會丟回一堆True和False,放在原本的trian_corr.index[]就會把是大於0.6的傳回去
print(high_corr)
輸出:
Index(['OverallQual', 'TotalBsmtSF', '1stFlrSF', 'GrLivArea', 'GarageCars',
'GarageArea', 'SalePrice'],
dtype='object')
今天的比較困難囉,但是對於數據的分析卻是相當的重要,因為我們要適時的篩選出不好的資料並刪除!明天要繼續關注唷!


 iThome鐵人賽
iThome鐵人賽