今天是第21天,幾乎是每天都被文章追著跑 ,今天我們先借觀察一下昨天看到的那些資料,並分析哪些是我們不要的,再斟酌丟棄,後來會將訓練集多切一個驗證集出來,原因下面會再說明,那就開始吧!
,今天我們先借觀察一下昨天看到的那些資料,並分析哪些是我們不要的,再斟酌丟棄,後來會將訓練集多切一個驗證集出來,原因下面會再說明,那就開始吧!
接續昨天的程式碼,昨天指示觀看程式碼,以及給訓練集和測試集一個名稱而已!接下來我們先看看資料裡面的型態
#先看看基本資料們
print(df_train.shape) #查看trian的形狀,以方便後來訂定神經網路的輸入層
print(df_test.shape) #查看test形狀
print('*'*50)
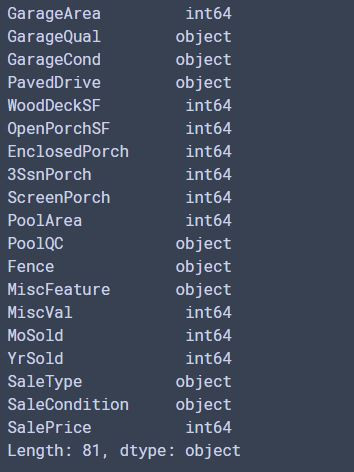
print(df_train.dtypes) #看一下訓練資料的各個欄位的型態
輸出片段: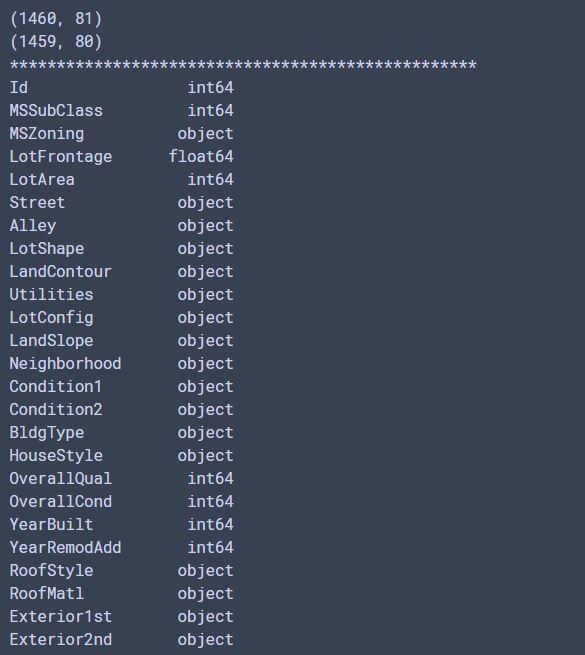
df_train.drop("Id",inplace = True,axis=1) #inplace = True會直接把原本的data改掉,axis=1才會刪除 行
df_test.drop("Id",inplace = True,axis=1) #inplace = True會直接把原本的data改掉,axis=1才會刪除 行
df_train.head(5) #.head()可以查看前幾筆資料,括號填入數字
輸出: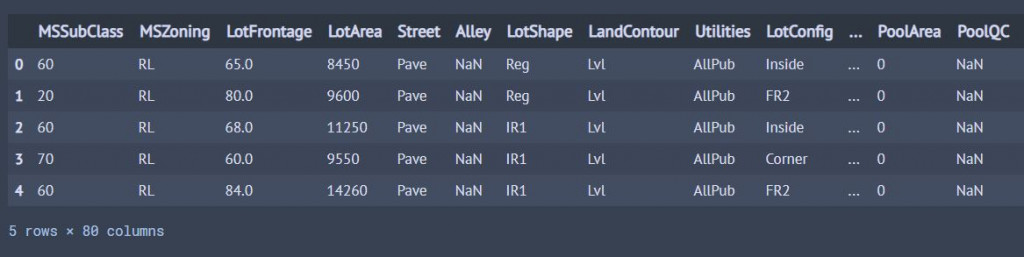
到這裡先介紹兩個東西,一個是seaborn還有誰是驗證集!
Seaborn是在Matplotlib上面的高階視覺化API,相較於Matplotlib,Seaborn繪圖更快速,要以比喻的方式說明Seaborn和Matplotlib的關係,就像是Keras和tensorflow關係一樣,所以以Seaborn的方式繪畫會更快、更方面,就像Keras在建神經網路一樣非常方便。但這邊特別出來是因為,在分析資料時常常會使用Seaborn畫圖更為快速~在明天的code就會使用到囉!
之前提到的機器學習都只分訓練集和測試集兩種。利用訓練資料學習,最後再用測試資料判斷準確度來看這個model,來觀察是否有過於符合這個訓練資料(overfitting)。
先介紹一個名詞-超參數(hyper-parameter):超參數可以代表的意思有很多,如神經元數量、學習率、權重等等。但我們通常不易去決定以上這些,會讓我們在建立神經網路時有很大的困擾,通常都要嘗試錯誤法去找到比較好的模型,然而這會耗掉我們相當多的時間,所以這時候驗證集的重要性就來了。
我們可以從訓練集切出一份資料當成驗證集,通常會切成8(訓練集):2(驗證集),比例也可以是9:1,大概是訓練集會多出很多這樣,當然還有其他種驗證資料的分法,我們這邊先不提到。所以,驗證資料的目的就是為了評估超參數的效能並調整,有了驗證資料會讓我們的模型收斂得更好!
明天開始會大幅度進入到coding的部分,一樣還是有理論的話會進行補充,21天了,加油!


 iThome鐵人賽
iThome鐵人賽