上一篇談到準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1 Score,它們適用在不同的場景,接著我們再來討論『ROC/AUC 曲線』,它是一個更全面評估效能的指標。
遠在1941年『ROC/AUC 曲線』就被用來偵測敵軍飛機及船艦,美軍利用雷達信號判斷飛機、船艦的所在位置,之後也被廣泛應用在無線電、生物學、犯罪心理學、醫學領域,接下來我們就來領略它的強大威力。
ROC(Receiver operator characteristic):有人翻譯為『接收操作特徵圖』,其實沒甚麼幫助,它的定義是在各種『決策門檻』(decision threshold)下,比較『真陽率』(True Positive Rate;TPR)與『假陽率』(False Positive Rate;FPR)間的變化。
圖. 『真陽率』與『假陽率』公式
ROC曲線可以繪製成一條曲線,如下圖,有多條ROC曲線,相互比較效能,AUC(Area Under the Curve)就比較容易理解,即ROC曲線之下所覆蓋的面積,除以總面積的比率。
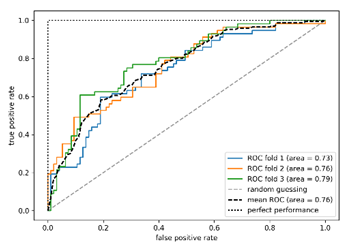
圖. ROC曲線比較,X軸為假陽率,Y軸為真陽率。
以雷達偵測為例,信號要大於某個決策門檻(decision threshold),飛機才會出現在雷達螢幕上,假設雷達螢幕旁有一旋鈕,可以調整門檻值,如果調高一點,則雷達螢幕偵測敵機的能力變差,有些信號弱的飛機就不會顯示,反之,門檻調低一點,則雷達螢幕偵測敵機的能力變強,但是我們可能把天空中的大鳥誤認為飛機(假陽率)。因此,可以在各種門檻下計算真陽率及假陽率,作為樣本點,將所有樣本點連成一線,即ROC曲線,因此,這條線越接近上方,表示真陽率越高,即判斷正確的比率越高,換句話說,ROC曲線下方覆蓋的面積(AUC)越大,表示效能越好。以上就是ROC/AUC 曲線的精髓。
我們從二分類的分配(分佈)角度來看,如果調整決策門檻,則TP(真陽)、FP(假陽)會随之變化。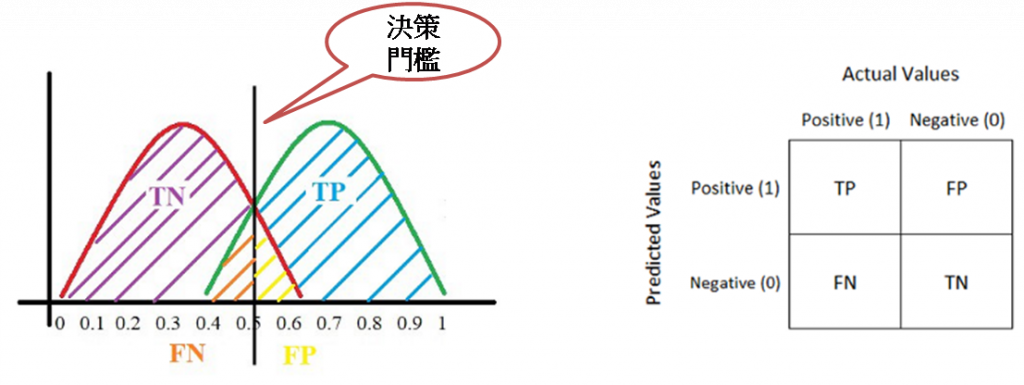
圖. TP、TN、FT、FN 的示意圖,資料來源:Finding Donors: Classification Project With PySpark
二分類的分配差異越顯著,AUC的分數就越高,見下圖。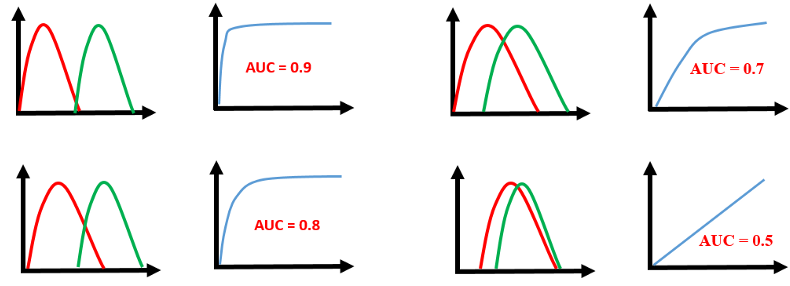
圖. AUC,資料來源:Finding Donors: Classification Project With PySpark
接下來我們就要了解如何繪製ROC曲線,範例如下:
資料內容如下,第一欄為預測為真的機率,第二欄為實際值。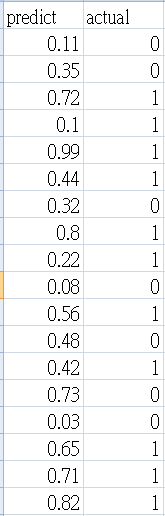
繪製ROC曲線步驟:
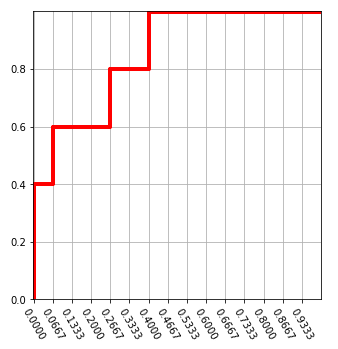
繪製原理很直覺,實際值為1(真),表示真陽(預測超過門檻),故Y軸加1格,反之,為假陽(預測超過門檻,但實際為假),故X軸加1格。
依照上述步驟,撰寫程式如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score, auc
# 讀取資料
import pandas as pd
df=pd.read_csv('./data.csv')
# 計算第二欄的真(1)與假(0)的個數,假設分別為P及N
P= df[df['actual']==1].shape[0]
N= df[df['actual']==0].shape[0]
print(P,N)
y_unit=1/P
X_unit=1/N
# 以第一欄降冪排序,從大排到小。
df2=df.sort_values(by='predict', ascending=False)
# 依序掃描第二欄,計算每一座標點
# 若是1,Y加一單位,反之,若是0,X加一單位
X=[]
y=[]
current_X=0
current_y=0
for row in df2.itertuples():
# row[0] is index
#print(row[2])
if row[2] == 1:
current_y+=y_unit
else:
current_X+=X_unit
X.append(current_X)
y.append(current_y)
X=np.array(X)
y=np.array(y)
print(X, y)
# 繪圖。
plt.title('Receiver Operating Characteristic')
plt.plot(X, y, color = 'orange')
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
直接使用 Scikit-Learn套件更簡單,程式如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score, auc
# 讀取資料
import pandas as pd
df=pd.read_csv('./data.csv')
# 在各種『決策門檻』(decision threshold)下,計算 『真陽率』(True Positive Rate;TPR)與『假陽率』(False Positive Rate;FPR)
fpr, tpr, threshold = roc_curve(df['actual'], df['predict'])
print(fpr, tpr, threshold)
auc1 = auc(fpr, tpr)
## Plot the result
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, color = 'orange', label = 'AUC = %0.2f' % auc1)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
執行結果如下: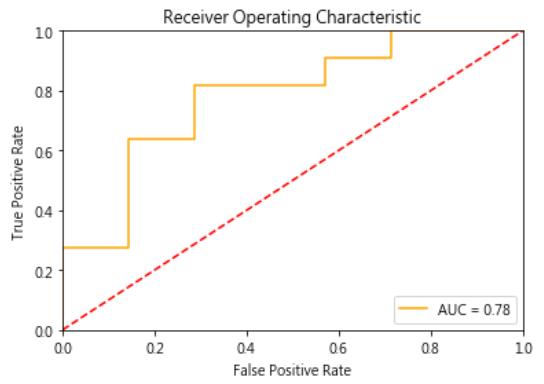
相關程式碼放在這裡的 ROC_AUC_sample 目錄。
以上說明希望能有助於觀念的釐清,如有失當,還請各位先進不吝指正。
上面公式翻譯錯了...
Specificity應該是"特異度"或者是"真陰率"
如果是假陽率...應該是FPR=FP/(FP+TN)
謝謝指教,已更正。
 I code so I am
I code so I am

 iThome鐵人賽
iThome鐵人賽