
此文是《10周入門資料分析》系列的第14篇
想瞭解學習路線,可以先閱讀 學習計畫 | 10周入門資料分析
Python的內容比較多,可能要花個幾周的時間來講完。
上一篇文章講了Python的一些運行環境和資料基礎,本篇文章將來講解高級的,函數參數這些。
** 在 Python 中有三種控制流語句,if、for和while。**
if age >= 18:
注意不要少寫了冒號 : 。
elif是else if的縮寫,完全可以有多個elif,所以if語句的完整形式就是:
if <條件判斷1>:
<執行1>
elif <條件判斷2>:
<執行2>
elif <條件判斷3>:
<執行3>
else:
<執行4>
if語句執行有個特點,它是從上往下判斷,如果在某個判斷上是True,把該判斷對應的語句執行後,就忽略掉剩下的elif和else。
if判斷條件還可以簡寫,比如寫:
if x:
print(‘True’)
只要x是非零數值、非空字串、非空list等,就判斷為True,否則為False。
Python 的迴圈有兩種。
第一種是for…in迴圈,依次把list或tuple中的每個元素反覆運算出來
所以for x in …迴圈就是把每個元素代入變數x,然後執行縮進塊的語句。
Python 提供一個range()函數,可以生成一個整數序列,再通過list()函數可以轉換為list。比如range(5)生成的序列是從 0 開始小於 5 的整數:
計算:
第二種迴圈是while迴圈:
在迴圈中,break語句可以提前退出迴圈。
在迴圈過程中,也可以透過continue語句,跳過當前的這次迴圈,直接開始下一次迴圈。continue的作用是提前結束本輪迴圈,並直接開始下一輪迴圈。
要特別注意,不要濫用break和continue語句。break和continue會造成程式碼執行邏輯分叉過多,容易出錯。大多數迴圈並不需要用到break和continue語句,上面的兩個例子,都可以透過改寫迴圈條件或者修改迴圈邏輯,去掉break和continue語句。
有些時候,如果程式碼寫得有問題,會讓程式陷入“閉環”,也就是永遠迴圈下去。這時可以用Ctrl+C退出程式,或者強制結束 Python進程。
函數(Functions)是指可重複使用的程式片段。它們允許你為某個程式碼塊賦予名字,允許你透過這一特殊的名字在你的程式任何地方來運行代碼塊,並可重複任何次數。這就是所謂的調用(Calling)函數。
在 Python 中,函數可以透過關鍵字 def 來定義。這一關鍵字後跟一個函數的識別字名稱,再跟一對圓括號,其中可以包括一些變數的名稱,再以冒號結尾,結束這一行。隨後而來的語句塊是函數的一部分。
在定義函數時給定的名稱稱作“形參”(Parameters),在調用函數時你所提供給函數的值稱作“實參”(Arguments)。
要調用一個函數,需要知道函數的名稱和參數。函數的參數只是輸入到函數之中,以便我們可以傳遞不同的值給它,並獲得相應的結果。
Python 內置的常用函數包括資料類型轉換函數,比如int()函數可以把其他資料類型轉換為整數。用input()讀取用戶的輸入: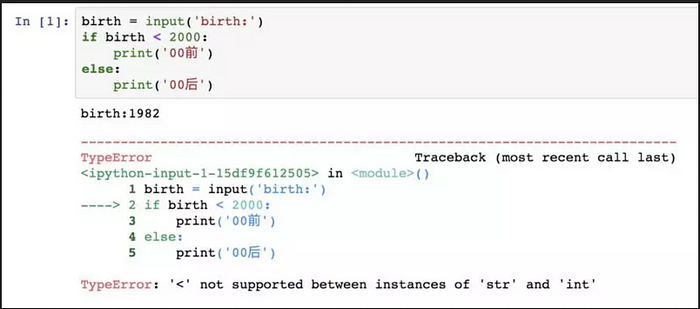
因為input()返回的資料類型是str,str不能直接和整數比較,必須先把str轉換成整數。Python 提供了int()函數來完成這件事情: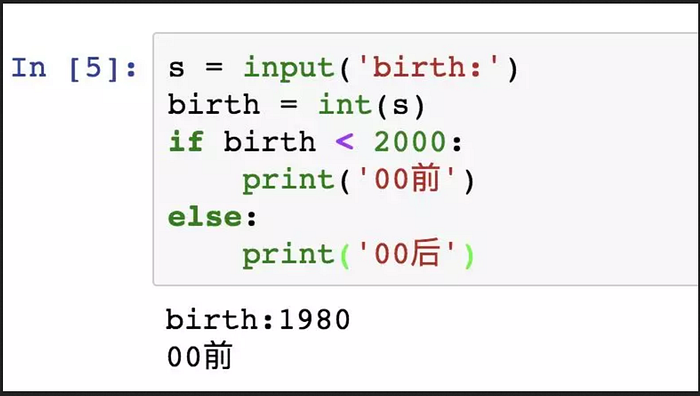
函數名其實就是指向一個函數物件的引用,完全可以把函數名賦給一個變數,相當於給這個函數起了一個“別名”:
如果函式呼叫出錯,一定要學會看錯誤資訊。
在 Python 中,定義一個函數要使用def語句,依次寫出函數名、括弧、括弧中的參數和冒號:,然後,在縮進塊中編寫函數體,函數的返回值用return語句返回。
在 Python 交互環境中定義函數時,注意 Python 會出現…的提示。函式定義結束後需要按兩次回車重新回到>>>提示符下: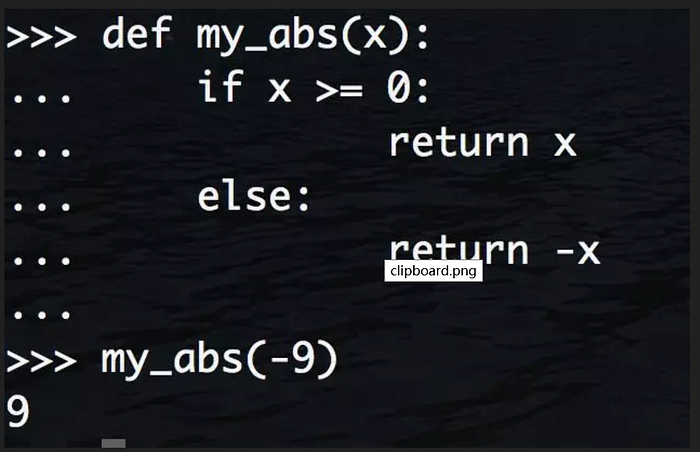
如果你已經把my_abs()的函式定義保存為abstest.py檔了,那麼,可以在該檔的目前的目錄下啟動Python 解譯器,用from abstest import my_abs來匯入my_abs()函數,注意abstest是檔案名(不含.py副檔名)。
定義一個什麼事也不做的空函數,可以用pass語句:
def nop():
pass
pass語句什麼都不做,實際上它可以用作為預留位置,比如現在還沒想好怎麼寫函數的程式碼,就可以先放一個pass,讓程式碼能運行起來。
pass還可以用在其他語句裡,比如:
if age >= 18:
pass
缺少了pass,代碼運行就會有語法錯誤。
資料類型檢查可以用內置函數isinstance()實現。
Python 的函數返回多值其實就是返回一個tuple;Python 函數返回的是單一值時,返回值仍然是一個tuple。但是,在語法上,返回一個tuple可以省略括弧,而多個變數可以同時接收一個tuple,按位置賦給對應的值。函數可以同時返回多個值,但其實就是一個tuple。
函數執行完畢也沒有return語句時,自動return None。
Python 的函式定義非常簡單,但靈活度卻非常大。除了正常定義的必選參數外,還可以使用默認參數、可變參數和關鍵字參數,使得函式定義出來的介面,不但能處理複雜的參數,還可以簡化調用者的程式碼。
power(x, n)函數有兩個參數:x和n,這兩個參數都是位置參數,調用函數時,傳入的兩個值按照位置順序依次賦給參數x和n。
對於一些函數來說,你可能為希望使一些參數可選並使用默認的值,以避免用戶不想為他們提供值的情況。預設參數值可以有效説明解決這一情況。你可以透過在函式定義時附加一個設定運算子=來為參數指定默認參數值。要注意到,默認參數值應該是常數。更確切地說,默認參數值應該是不可變的。
n = 2 是默認參數
定義默認參數要牢記一點:預設參數必須指向不變物件。且只有那些位於參數列表末尾的參數才能被賦予默認參數值,意即在函數的參數清單中擁有默認參數值的參數不能位於沒有默認參數值的參數之前。
有時你可能想定義的函數裡面能夠有任意數量的變數,也就是參數數量是可變的,這可以透過使用星號來實現。即傳入的參數個數是可變的。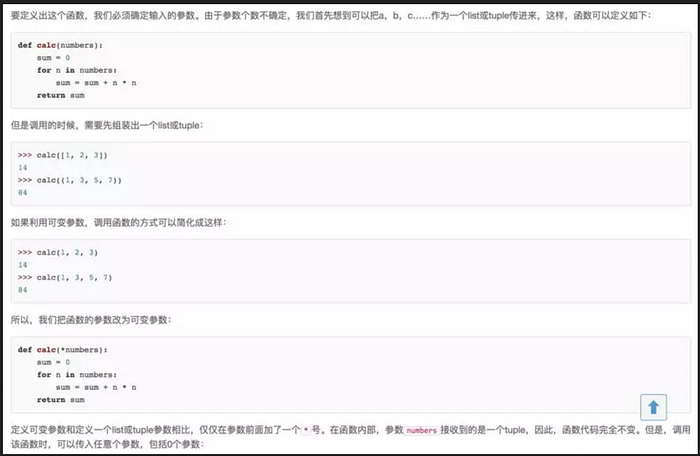
我們聲明一個諸如 *param 的星號參數時,從此處開始直到結束的所有位置參數(Positional Arguments)都將被收集並彙集成一個稱為param的元組(Tuple)。
類似地,當我們聲明一個諸如 **param 的雙星號參數時,從此處開始直至結束的所有關鍵字參數都將被收集並彙集成一個名為 param 的字典(Dictionary)。
如果你有一些具有許多參數的函數,而你又希望只對其中的一些進行指定,那麼你可以通過命名它們來給這些參數賦值 — — 這就是關鍵字參數(Keyword Arguments) — — 我們使用命名(關鍵字)而非位置來指定函數中的參數。
關鍵字參數允許你傳入 0 個或任意個含參數名的參數,這些關鍵字參數在函數內部自動組裝為一個dict。
舉個例子,擴展函數的功能。試想你正在做一個用戶註冊的功能,除了用戶名和年齡是必填項外,其他都是可選項,利用關鍵字參數來定義這個函數就能滿足註冊的需求。
和可變參數類似,也可以先組裝出一個dict,然後,把該dict轉換為關鍵字參數傳進去:
如果要限制關鍵字參數的名字,就可以用命名關鍵字參數,例如,只接收city和job作為關鍵字參數。這種方式定義函數並調用:
和關鍵字參數**kw不同,命名關鍵字參數需要一個特殊分隔符號*,*後面的參數被視為命名關鍵字參數。
命名關鍵字參數必須傳入參數名,這和位置參數不同。如果沒有傳入參數名,調用將報錯。
使用命名關鍵字參數時,要特別注意,如果沒有可變參數,就必須加一個作為特殊分隔符號。如果缺少,Python 解譯器將無法識別位置參數和命名關鍵字參數,即缺少 *,city和job被視為位置參數。
在 Python 中定義函數,可以用必選參數、默認參數、可變參數、關鍵字參數和命名關鍵字參數,這 5 種參數都可以組合使用。
但是參數定義的順序必須是:必選參數、默認參數、可變參數、命名關鍵字參數和關鍵字參數。雖然可以組合多達 5 種參數,但不要同時使用太多的組合,否則函數介面的可理解性很差。
透過一個tuple和dict,你也可以調用函數: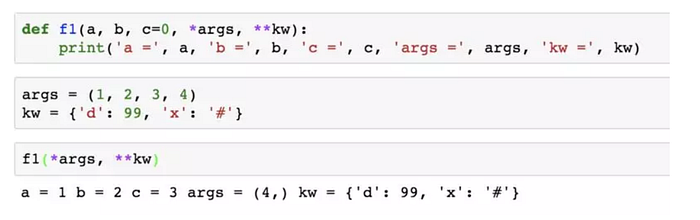
對於任意函數,都可以透過類似func(*args, **kw)的形式調用它,無論它的參數是如何定義的。
如果一個函數在內部調用自身本身,這個函數就是遞迴函數。理論上,所有的遞迴函數都可以寫成迴圈的方式,但迴圈的邏輯不如遞迴清晰。
使用遞迴函數需要注意防止棧溢出。在電腦中,函式呼叫是透過棧(stack)這種資料結構實現的,每當進入一個函式呼叫,棧就會加一層棧幀,每當函數返回,棧就會減一層棧幀。由於棧的大小不是無限的,所以,遞迴呼叫的次數過多,會導致棧溢出。
透過下面的程式碼可以查看你的電腦最大算到多少:
解決遞迴呼叫棧溢出的方法是透過尾遞迴優化,事實上尾遞迴和迴圈的效果是一樣的,所以,把迴圈看成是一種特殊的尾遞迴函數也是可以的。
尾遞迴是指,在函數返回的時候,調用自身本身,並且,return語句不能包含運算式。這樣,編譯器或者解譯器就可以把尾遞迴做優化,使遞迴本身無論調用多少次,都只佔用一個棧幀,不會出現棧溢出的情況。
要改成尾遞迴方式,需要多程式碼一點,主要是要把每一步的乘積傳入到遞迴函數中。Python 標準的解譯器沒有針對尾遞迴做優化,任何遞迴函數都存在棧溢出的問題。
學會函數,工作中讓你省一半力氣,但是Python的優勢就是還能再省力。比如中位數、標準差等,依舊需要寫代碼,有沒有現成的直接調用呢?
第一種思路是搜尋,「python 中位數」和「python 標準差」的關鍵字在網上可以搜出一堆,直接參考即可。
第二種思路是調包,世界上好心人很多,他們已經寫好了現成的諸多功能,把它們共用在了網上,這些功能統一做成了「包」。
包的概念類似於資料夾,資料夾中放著很多檔,一個.py檔就稱之為一個模組(Module)。包括 Python 内建的模組和來自協力廠商的模組。.py 檔中包含著具體的程式碼,程式碼太多會顯得比較淩亂,為了規範和整理程式碼,引入了「類」。類是一種抽象的概念,是物件導向程式設計的核心,資料分析不用深入理解這塊,只要知道類是各種函數的集合,方便複用,用起來很簡單就行。
内建的dir()函數能夠返回由物件所定義的名稱清單。
如果這一對像是一個模組,則該清單會包括函數內所定義的函數、類與變數。該函數接受參數。
如果參數是模組名稱,函數將返回這一指定模組的名稱清單。
如果沒有提供參數,函數將返回當前模組的名稱清單。
變數通常位於函數內部,函數與全域變數通常位於模組內部。如果你希望組織起這些模組的話,就需要包(Packages)。
Python 引入了按目錄來組織模組的方法,稱為包(Package)。它是一種能夠方便地分層組織模組的方式。包是指一個包含模組與一個特殊的 init.py 檔的資料夾,這個檔是必須存在的,否則,Python就把這個目錄當成普通目錄,而不是一個包。init.py可以是空檔,也可以有Python代碼,因為__init__.py本身就是一個模組。
在一個模組中,我們可能會定義很多函數和變數,但有的函數和變數我們希望給別人使用,有的函數和變數我們希望僅僅在模組內部使用。在 Python 中,是透過_首碼來實現的。
類似__xxx__這樣的變數是特殊變數,可以被直接引用,但是有特殊用途,比如__author__,__name__就是特殊變數。我們自己的變數一般不要用這種變數名。
類似_xxx和__xxx這樣的函數或變數就是非公開的(private),不應該被直接引用,比如_abc,__abc等。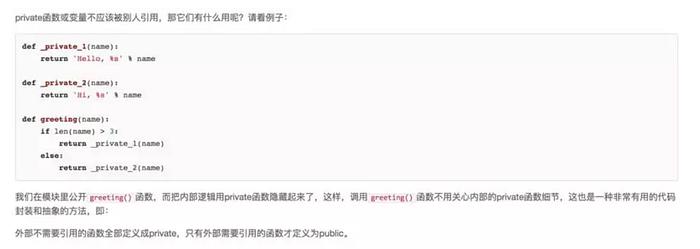
對應的 pip 命令是pip3。
預設情況下,Python 解譯器會搜尋目前的目錄、所有已安裝的內置模組和協力廠商模組,搜索路綫存放在sys模組的path變數中: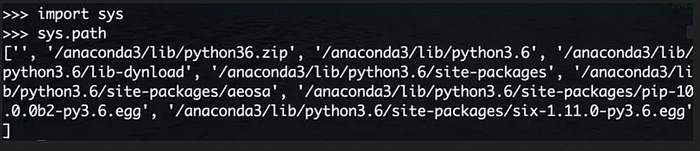
Python提供了非常豐富的包和模組,合理應用這些模組將極大程度的提供資料分析能力。numpy、scipy、pandas是資料分析最常用的三個包,matplotlib、seaborn是常用的繪圖包,scikit-learn、Gensim、NLTK是機器學習相關的包,urllib、BeautifulSoup是常用的爬蟲包等。
接下來,我會花幾篇文章介紹用numpy、Pandas進行資料分析。
我是「數據分析那些事」。常年分享資料分析乾貨,不定期分享好用的職場技能工具
更多的資料分享乾貨,關注我的臉書吧!
 groots
groots

 iThome鐵人賽
iThome鐵人賽