
前兩篇講了Python的基礎,今天開始進入Python資料分析工具的教程。
Python資料分析絕對繞不過的四個包是numpy、scipy、pandas還有matplotlib。
numPy是Python數值計算最重要的基礎包,大多數提供科學計算的包都是用numPy的陣列作為構建基礎。專門用來處理矩陣,它的運算效率比列表更高效。
scipy是基於numpy的科學計算包,包括統計、線性代數等工具。
pandas是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
matplotlib 是最流行的用於繪製資料圖表的 Python 庫。
本文先分享NumPy包。
numpy的資料結構是n維的陣列物件,叫做ndarray。可以用這種陣列對整塊資料執行一些數學運算,其語法跟標量元素之間的運算一樣。
創建並操作多維陣列: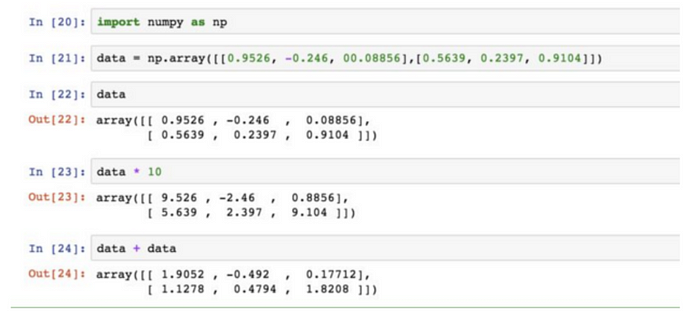
ndarray物件中所有元素必須是相同類型的,每個陣列都有一個shape和dtype。

創建陣列最簡單的辦法就是使用 array 函數,它接受一切序列型物件(包括其它陣列),然後產生一個新的NumPy陣列(含有原來的資料)。
np.array會嘗試為新建的這個陣列推斷出一個較為合適的資料類型,這個資料類型保存在一個特殊的dtype物件中。
zeros 和 ones 也分別可以創建指定大小的全 0 或全 1 陣列,empty 可以創建一個沒有任何具體值的陣列(它返回的都是一些未初始化的垃圾值):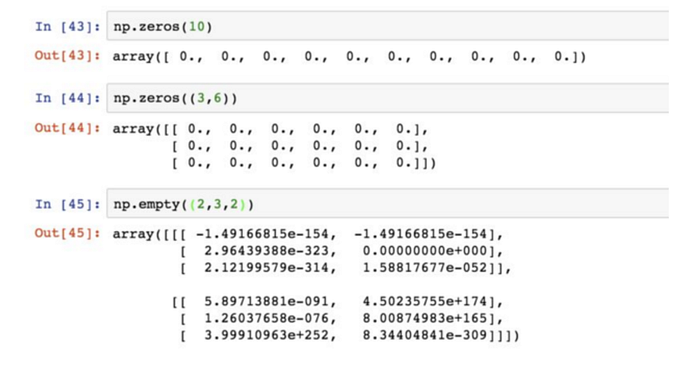
arange是 Python 內置函數range的陣列版,np.arange返回間隔均勻的一些值。
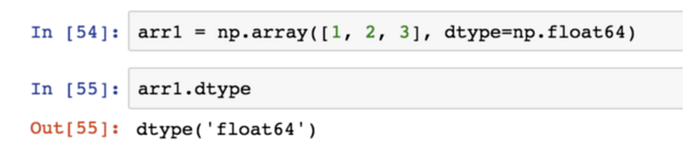
dtype(資料類型)是一個特殊的物件,它含有 ndarray 將一塊記憶體解釋為特定資料類型所需的資訊。
需要知道你所處理的資料的大致類型是浮點數、複數、整數、布林值、字串,還是普通的 python 對象。當需要控制資料在記憶體和磁片中的存儲方式時,就得瞭解如何控制存儲類型。
可通過ndarray的astype方法顯示地轉換其dtype:
若將浮點數轉換成整數,則小數部分將會被截斷。
若某字串陣列表示的全是數位,可用astype將其轉換為數值形式:
這裡沒寫 np.float64 只寫了 float,但是NumPy會將 Python 類型映射到等價的dtype上。
陣列的dtype的另一個用法: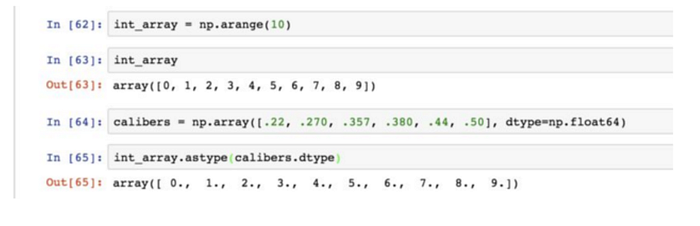
u4(unit32):無符號的 32 位元(4個位元組)整型。
調用astype無論如何都會創建出一個新的陣列(原始資料的一份拷貝)。
浮點數只能表示近似的分數值,在複雜計算中可能會積累一些浮點錯誤,因此比較操作只在一定小數位以內有效。
陣列:可對資料執行批量運算(不用編寫迴圈即可)。這通常叫做向量化(vectorization)。
大小相等的陣列之間,它們之間任何的算數運算都會應用到元素級(每個元素都做這個運算了),陣列與標量的算數運算也是。
不同大小的陣列之間的運算叫做廣播(broadcasting)。

資料不會被複製,任何修改都直接改了原陣列。
如果僅是要一份副本,則用 .copy()。
這兩種方式等價。
若arr2d[2],則輸出的是一維陣列[7,8,9]。
223的陣列(2組2行3列):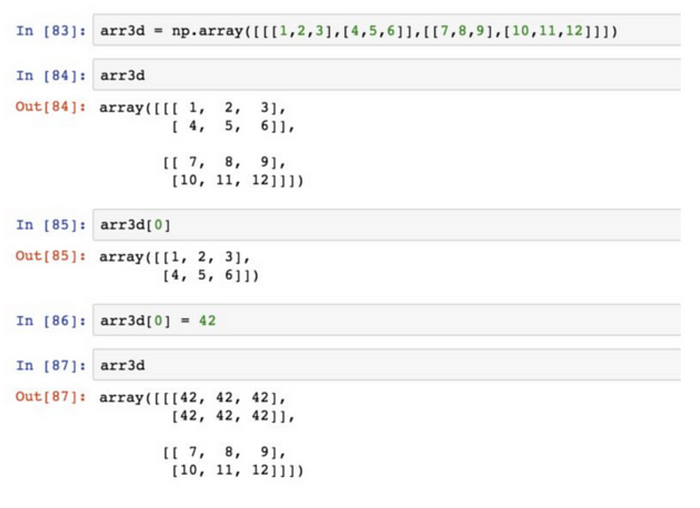

###布林型索引
需要先引入:from numpy.random import randn
或將程式碼改成:data = np.random.randn(7, 4)
布林型陣列的長度必須跟被索引的軸長度一致。每個名字對應 data 陣列一行。
對條件進行否定的兩種方式: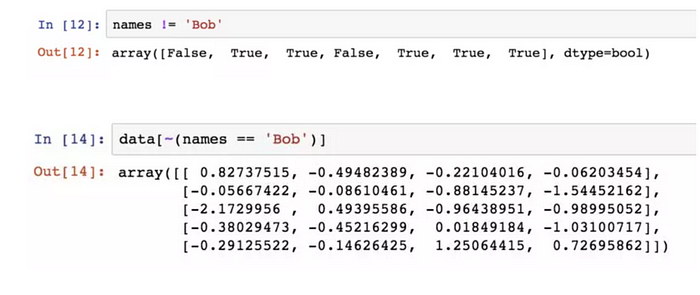
組合應用多個布林條件,可使用&、|等布林算術運算子:
透過布林型索引選取陣列中的陣列,將總是創建資料的副本,即使返回一模一樣的陣列也是一樣。
透過布林型陣列設定值: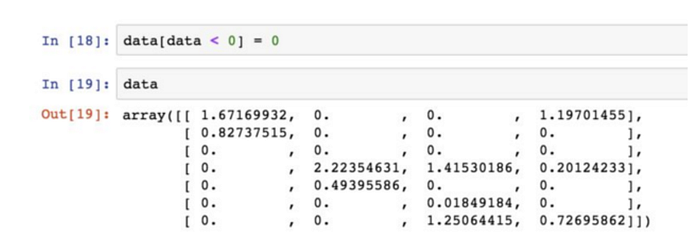
透過一維布林陣列設置整行或列的值: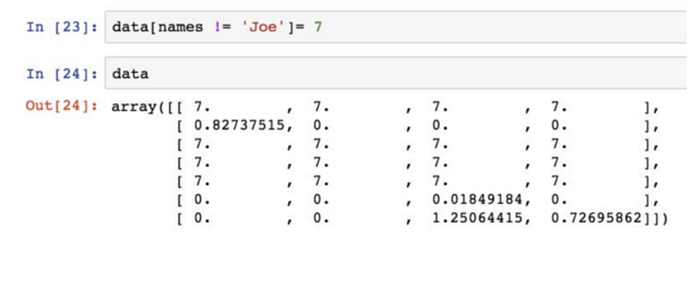
指利用整數陣列進行索引。
np.empty((8,4))
Return a new array of given shape and type, without initializing entries.
for i in range(8):
arr[i] = i
Return an object that produces a sequence of integers from start (inclusive)
to stop (exclusive) by step.
為了以特定順序選取行的子集,只需傳入一個用於指定順序的整數清單或 ndarray,使用負數索引會從末尾開始選取行(最後一行是 -1)。
一次傳入多個索引組,返回一個一維陣列:
取整列的兩種方法,相當於給列排了順序:
花式索引跟切片不一樣,總是將資料複製到新陣列中。
轉置返回的是來源資料的視圖,不進行任何複製操作。陣列有 transpose 方法,還有一個 T 屬性來完成轉置:
Transpose 要一個軸編號:
arr是 2 組 2 行 4 列的陣列,transpose的參數表示shape的形狀,對於這個例子來說,即2[0]、2[1]、4[2],transpose(1,0,2)轉置後變為2[1]、2[0]、4[2],看起來仍是 2 組 2 行 4 列的形狀,但陣列內的元素經過轉換後索引已經改變,也要遵循(1,0,2)的順序。如轉置前的陣列arr[0,1,0]索引值為 4,轉置後的陣列arr’[1,0,0],索引值才為 4。其它同理。
ndarray 的 swapaxes 方法接受一對軸編號且返回來源資料的視圖: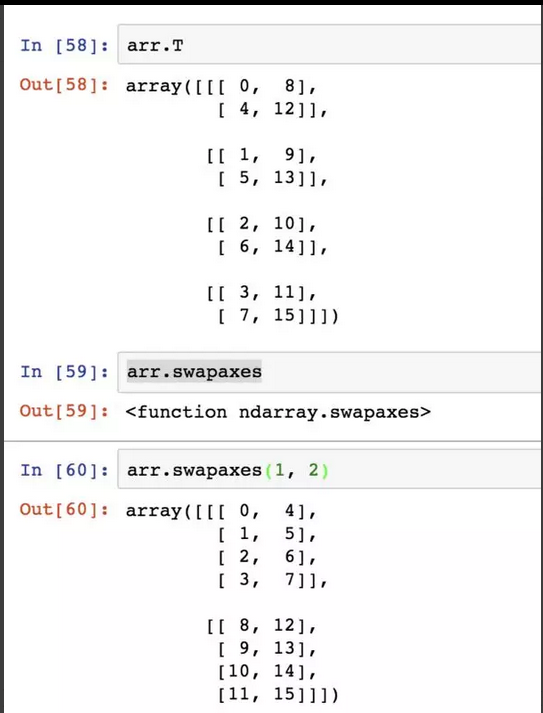
轉置後的陣列arr.T為 4[2] 組 2[1] 行 2[0] 列陣列,swapaxes(1,2)就是將第二個維度(中括弧內數位)和第三個維度交換,即轉換為 2 組 4 行 2 列。
通用函數(即 ufunc)是一種對ndarray中的資料執行元素級運算的函數,就是一些簡單函數。
用陣列運算式代替迴圈的做法,通常被稱為向量化。NumPy 陣列將多種資料處理任務表述為陣列運算式。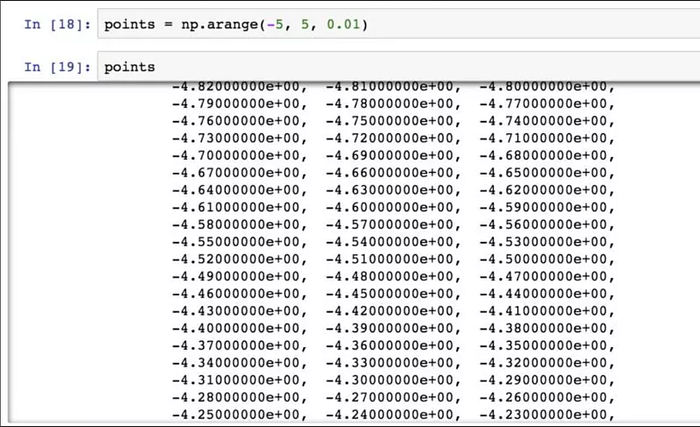
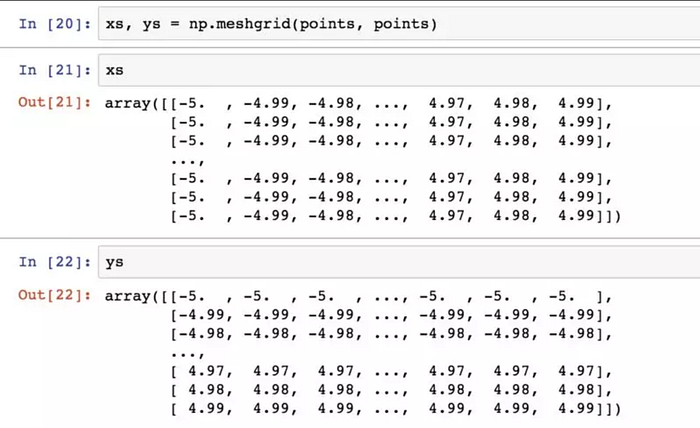
np.meshgrid函數接受兩個一維陣列,並產生兩個二維矩陣(對應於兩個陣列中所有的(x, y)對。

p.wherea函數是三元運算式x if condition else y的向量化版本。
np.where的第二個和第三個參數不必是陣列,傳遞給where的陣列大小可以不相等,甚至可以是標量值。在資料分析工作中,where通常用於根據另一個陣列而產生一個新的陣列。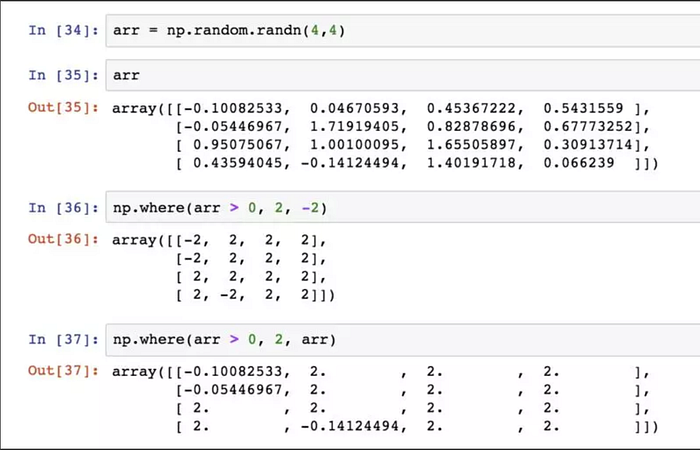
用where表述出更複雜的邏輯:(where的嵌套)
用於布林型陣列的方法
有兩個方法any和all。
排序
多維陣列可以在任何一個軸向上進行排序,只需將軸編號傳給sort: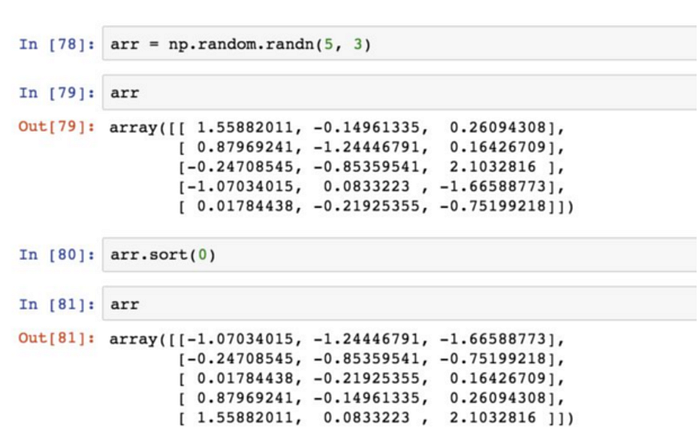
頂級方法np.sort返回的陣列已排序的副本,就地排序則會修改陣列。
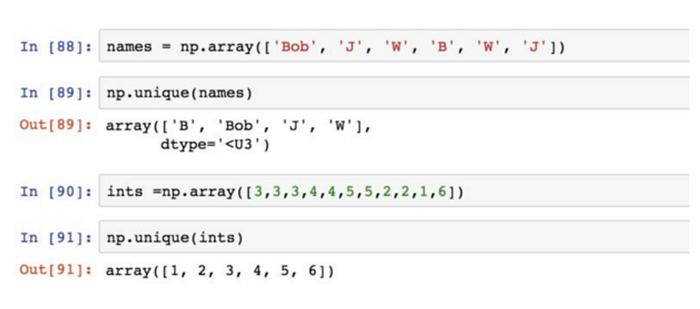
np.unique找出陣列中的唯一值並返回已排序的結果。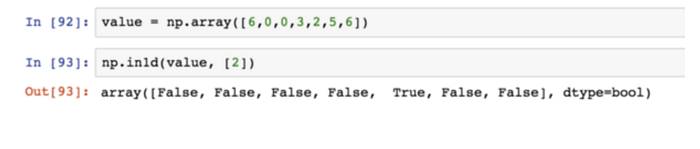
np.in1d用於測試一個陣列的值在另一個陣列的情況。
numpy.random模組多了用於高效生產多種概率分佈的樣本值的函數(用來生成大量樣本值)。
到這裡,numpy的基礎就講解的差不多了,下周將講解pandas和matplotlib。更深入的應用,後面也會分享實際應用這些包得資料分析,歡迎關注!
我是「數據分析那些事」。常年分享資料分析乾貨,不定期分享好用的職場技能工具。
 groots
groots




 iThome鐵人賽
iThome鐵人賽