鐵達尼沈船是一個世紀災難到了現在還是依然討論不止,今天我們使用R對於鐵達尼號的乘船資料進行分析,藉由資料的分析是否能發現人類在面對重大災難時是否保有人性的光輝,話不多說讓我們進入鐵達尼的世界,在上篇文章有提到資料集的**變項(欄位)**很重要,因此將鐵達尼的資料集欄位做一些整理如下圖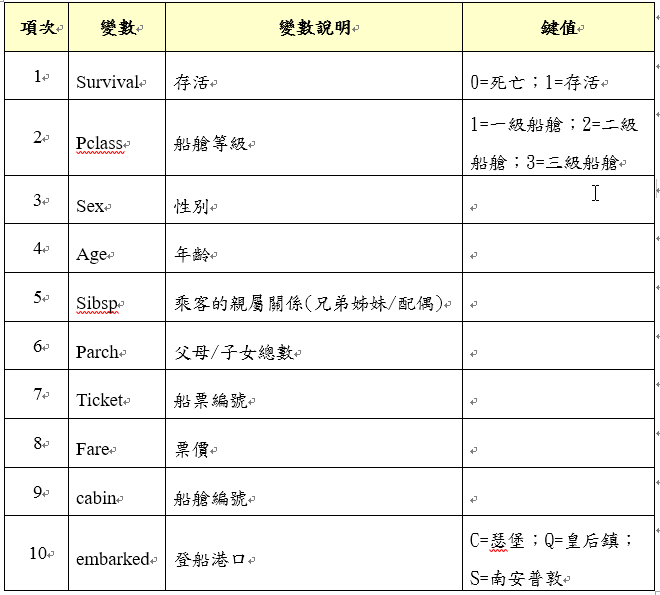
在上圖的變數(欄位)後續的程式碼都會使用到,每個變數都有說明分別記錄所儲存的內容大綱,對於我們的分析至關重要。而本次要分析的是甚麼?兩個字存活,在災難面前每個人的求生欲都會激發,而甚麼因素會影響存活率,所以本次分析影響存活因素歸納如下圖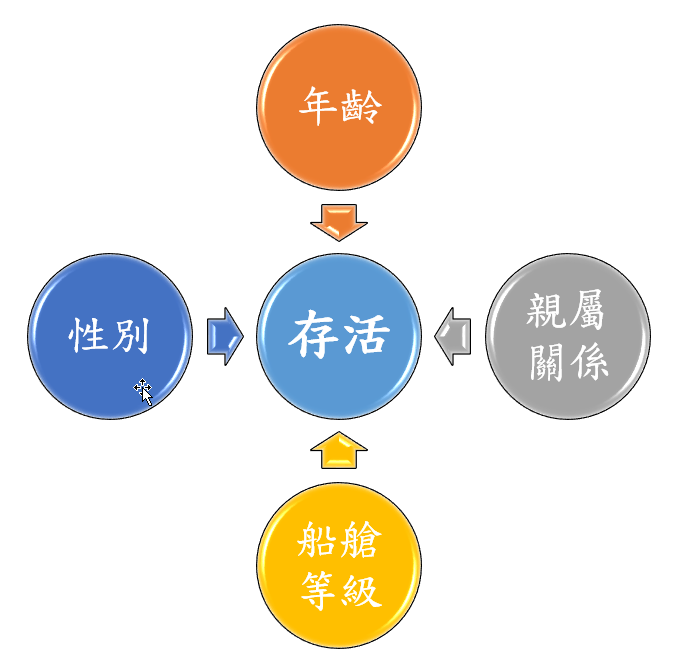
從上圖以順時鐘說明如下
上述對於鐵達尼資料集分析中所提出的假設,當然我們也可用自身的經驗來回答這些問題。但這並不科學也有可能是我們個人一廂請願的想法,這也是資料分析重要觀念之一,一切都需有明確的資料和數據在支撐,所以在鐵達尼資料分析中會以這為基礎進行資料的分析。
以下開始進入程式碼階段
library(ggplot2)
library(dplyr)
titanic <- read.csv("D:/工作區/我的筆記/程式筆記/R/Titanic/titanic.csv",stringsAsFactors=FALSE)
View(titanic)
str(titanic)
程式碼說明如下
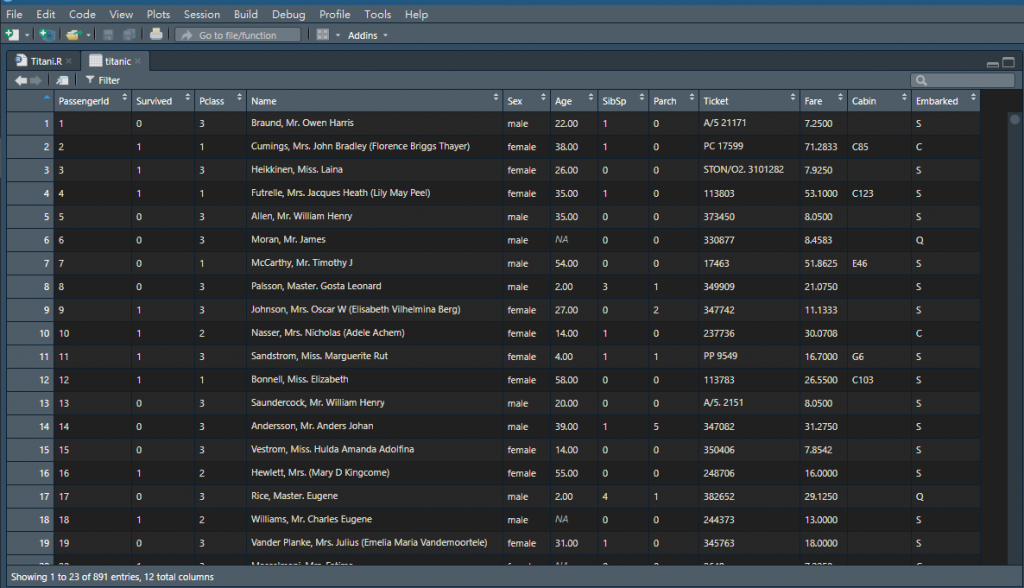
4.str(titanic)為觀看資料集的結構如下圖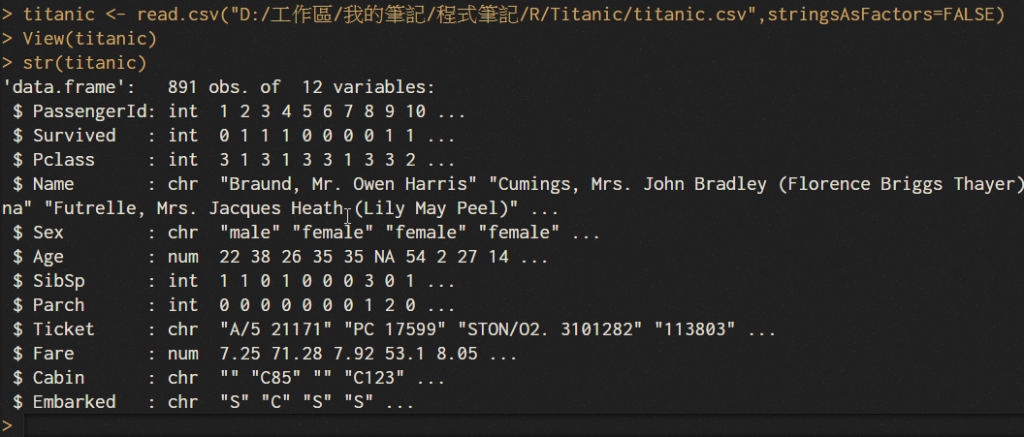
出現該資料集的結構內容包含有891筆資料、12個變數、變數的資料型態,例如SEX(性別)為chr(字元),這時我們對該資料集有初步的了解。
接下來我們必須將依些變數設為factor一般中文稱為因子,統計學稱為類別,簡單說像男生和女生或是船艙等級都可設為類別變數,其實如何判斷哪一些變數設為類別可視你的分析而定,一般來說資料重複性很高在分析時我們可設為類別變項,例如向本次該資料集的pclass(船艙等級共有3級),我們就會設定類別factor。
程式碼如下,以titanic$Survived 為例titanic資料集內的Survived變數,可用$來呼叫資料集內的變數
titanic$Survived <- as.factor(titanic$Survived)
titanic$Pclass <- as.factor(titanic$Pclass)
titanic$Sex <- as.factor(titanic$Sex)
titanic$Embarked <- as.factor(titanic$Embarked)
接下來第一個問題鐵達尼災難事件存活多少
ggplot(data=titanic,mapping = aes(x=titanic$Survived))+
theme_bw()+
geom_bar()+
labs(y="Passenger Count",
title = "Titanic Survival Rates")
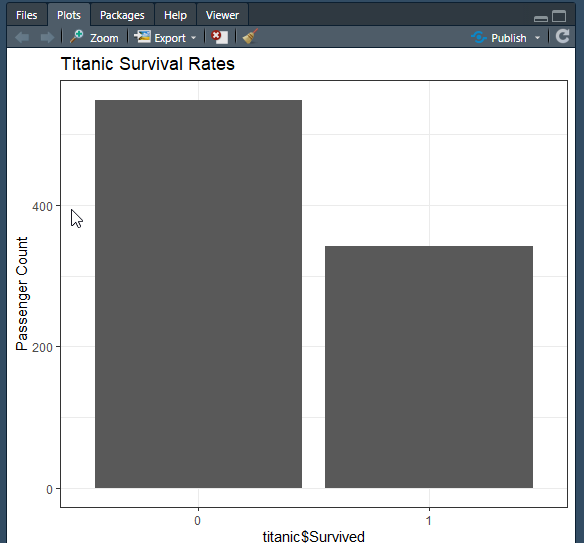
我知道圖形很醜不過循序漸進!
產生存活率百分比
prop.table(table(titanic$Survived))
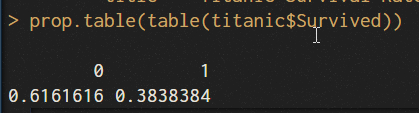
今天先到這邊!下一篇會介紹上述的繪圖程式以及相關分析

