關聯關則是資料探勘中很有名的買尿布有一定的機率會買啤酒,所以尿布和啤酒有一定的關聯度,所以在消費行為分析上是很有用,而分析的結果店家可以進行商品組合促銷,增加商品銷售率,關聯規則本來是要在店商分析中說明,不過沒關係配合Shiny網頁讓行銷人員透過Web進行分析,不過這些預測性的東西都須要對一些名詞的理解才能解釋,所以在這邊以尿布和啤酒,言簡意賅做解釋。
Support (支持度) : 意思是某特定種類在所有種類的比重,例如我有100名會員,其中有20名購買過尿布,則support(尿布) = 20% 。
Confidence (信賴度) : 意思是某A種類中,含有某B種類的比重,例如我有100名會員,其中40人買過啤酒,而這40買過啤酒者當中,又另有10人買過尿布,則confidence(啤酒->尿布) = 10/40 = 25% 。
Lift (提升度) : 意思為某兩者關係的比值,如果小於1 代表兩者是負相關,等於1 表示兩者獨立,大於1 表示兩者正相關,公式為confidence(A->B) / support(B) ,帶入上述例子可表示成 lift(尿布->啤酒) = 25/20 = 1.25 。
在R執行關聯規則須將原本資料結構dataframe轉換成transactions類別,也就是二元關聯矩陣,聽起來很像很偉大,其實就一個指令而已,而本次資料集採用套件arules中的Groceries內建資料集,該資料集為便利商店30天內的交易共計9835 筆,169各類別商品,該資料集已經為transactions資料類別,程式如下:
server.R程式
library(shiny)
library(arules)
shinyServer(function(input,output){
output$mba <- renderPrint({
rules <- apriori(Groceries,parameter = list(support=.001,
confidence=.8))
inspect(rules)
})
})
ui.R程式
library(shiny)
shinyUI(fluidPage(
sidebarLayout(
sidebarPanel(
),
mainPanel(
verbatimTextOutput("mba")
)
)
))
在server程式中將商品的關聯結果採用renderPrint(),而不採用renderTable因為試過所呈現的效果不好,而在ui.R使用verbatimTextOutput(),該函式是建立文字元素通常是跟renderPrint()配合使用,因此成果如下圖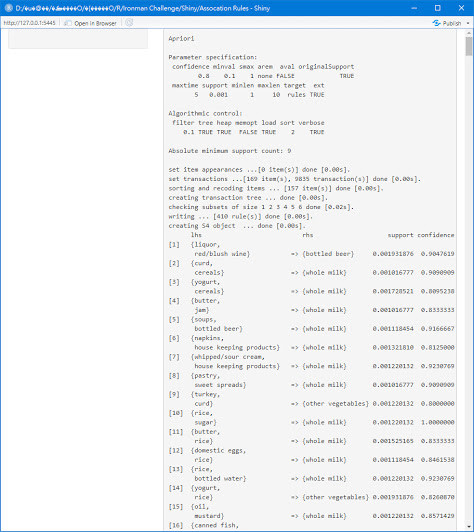
上圖我們可以看到關聯規則將所有的結果呈現,若使用者要調整不同的支持度和信賴度是無法調整,因為我們在server.R將兩個值給了固定值,所以我們將調整可以讓使用者調整兩個值,程式如下
ui.R程式調整如下
library(shiny)
shinyUI(fluidPage(
sidebarLayout(
sidebarPanel(
selectInput("sup","請選擇支持度",choices = c(.1,.01,.05,.001,.005)),
selectInput("conf","請選擇信賴度",choices = c(.5,.6,.7,.8,.9))
),
mainPanel(
verbatimTextOutput("mba")
)
)
))
server.R程式調整如下
library(shiny)
library(arules)
shinyServer(function(input,output){
output$mba <- renderPrint({
rules <- apriori(Groceries,parameter = list(support=as.numeric(input$sup),
confidence=as.numeric(input$conf)))
inspect(rules)
})
})
在上述程式在ui.R中設定兩個變數分別為sup及conf`,存放支持度和信賴度的值,因此在server.R將值帶入,成果如下圖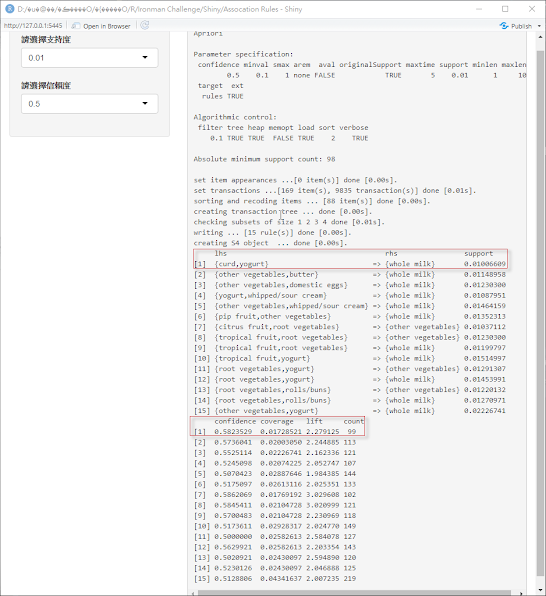
以第一筆紅框來講,買{酸奶,優格}=>{全指牛奶}來看,兩者商品同時出現占所有商品的1%,而買了{酸奶,優格}會買{全指牛奶}佔全部數據58%,兩者商品的提升2.2為正相關。

