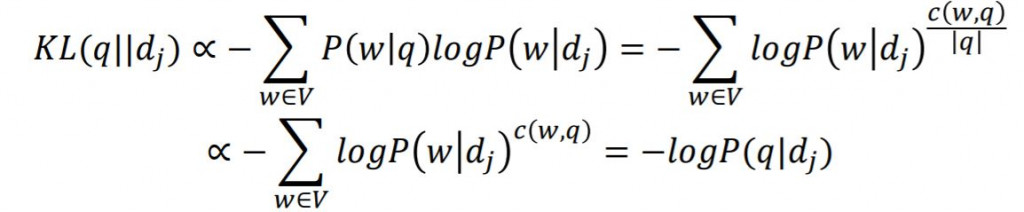語言模型(Language Models)在1998年才被應用到IR上。Language Models主要目的在於判斷長度T的文字序列在自然語言中出現的可能性。其中,Language Models可以表示成給定一段文字序列預測下一個文字出現的機率。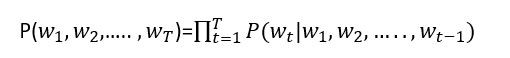
其中,Language Models最有名的是N-gram語言模型,可以分成:
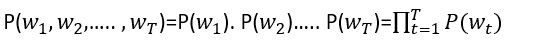
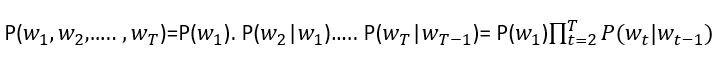
語言模型(Language Models)應用於IR上主要有兩種方法:
今天我先介紹KL-Divergence Measure
KL-Divergence Measure主要拿來計算query LM 和 document LM之間的距離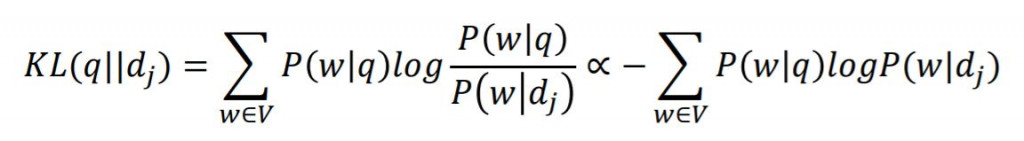
KL-Divergence Measure可以簡化為QLM