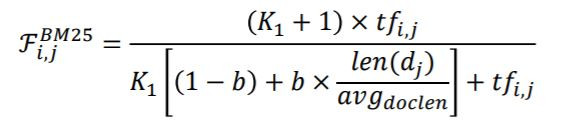先來複習一下IR三要素如下:
今天我們要介紹最佳匹配模型(Best Match Model)於1994年被提出。一開始Okapi system使用如下的公式作分數排序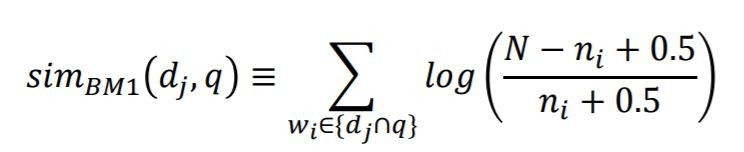
但是BM1的公式並沒有相關性資訊(relevance information)。為了增強排序在BM15引用term-frequency公式如下: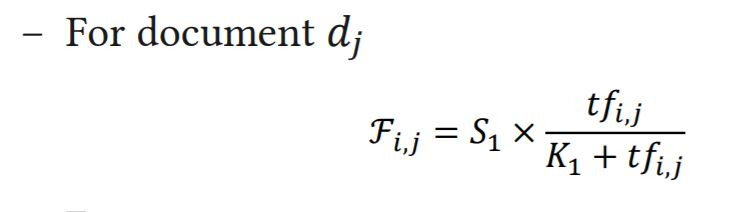
第j篇document中第i個word的term-frequency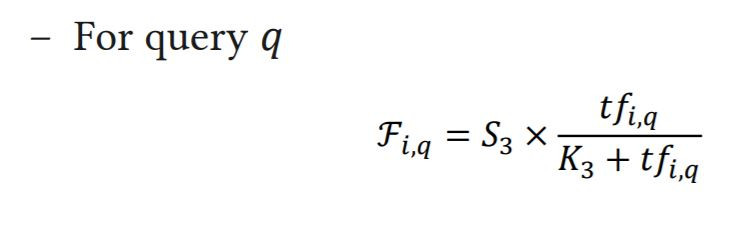
query中第i個word的term-frequency
其中表示第i個word在第j篇文章出現的次數
S1、S3、K1、K3皆為參數(S1=K1+1、S3=K3+1)
以上公式結果會介於0到1,從下圖實驗中可以觀察到K值越大頻率影響越大、K值越小頻率影響越小。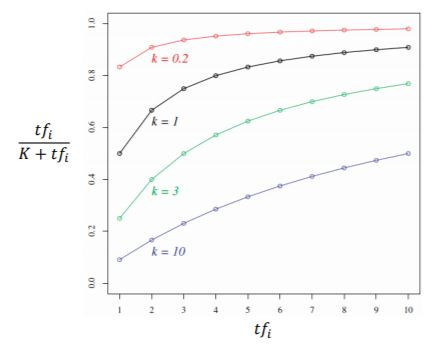
接著計算他會考慮到文章的長度以及query的長度
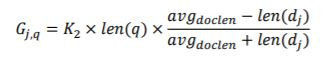
其中是可調參數、len(q)是query的長度、len(
)為文章長度、
所有文章長度平均
將上述綜合起來就可以得到BM15公式如下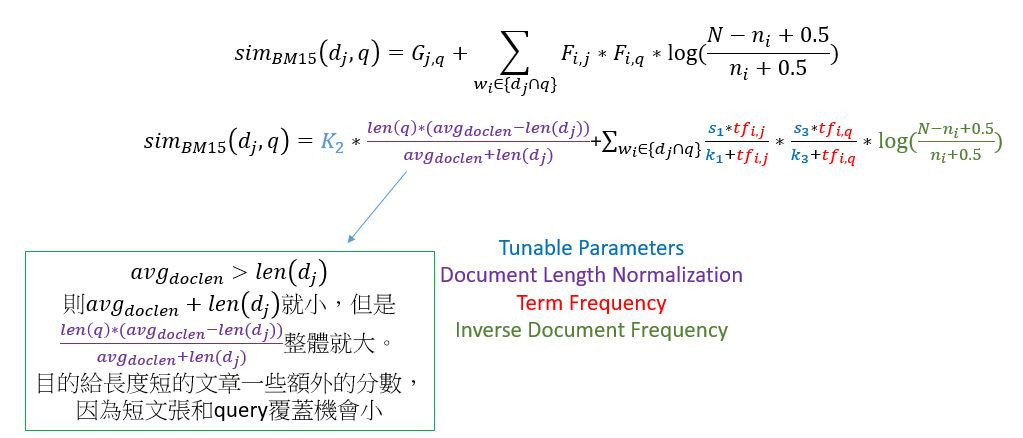
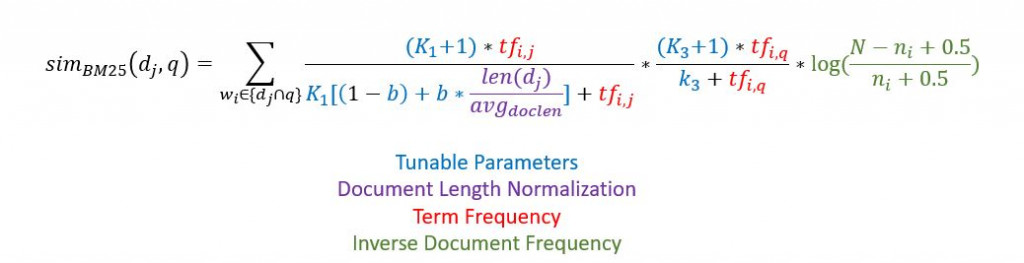
BM11和BM15主要差異在於有考慮到document length,term-frequency公式如下: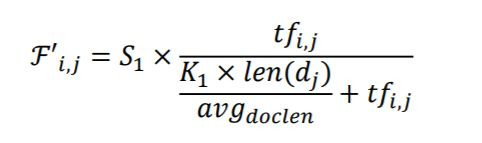
BM11的公式如下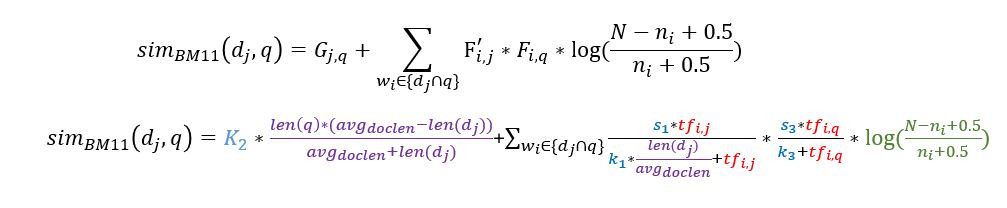
整理一下BM1、BM15、BM11公式如下: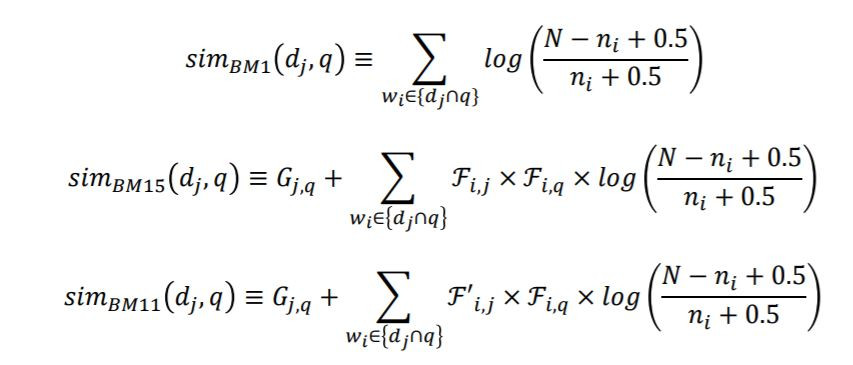
有些研究說K2設定為0效果比較好,所以BM1、BM15、BM11公式可以簡化如下: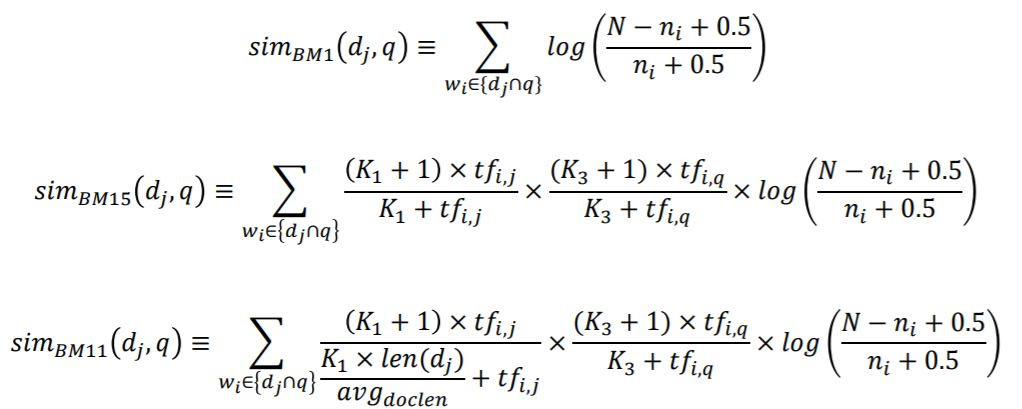
BM25提出來的概念是合併BM11和BM15,它的term-frequency公式如下: