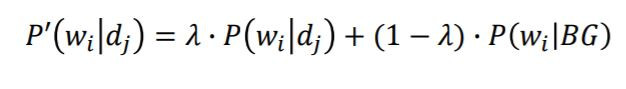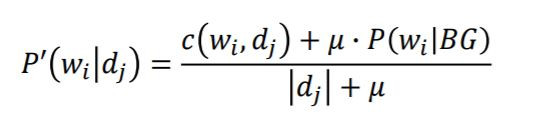昨天講到語言模型應用於IR上主要有兩種方法,KL-Divergence Measure以及 Query Likelihood Measure。
今天來談談 Query Likelihood Measure,它主要是利用P(|q)機率分數來排序文章。
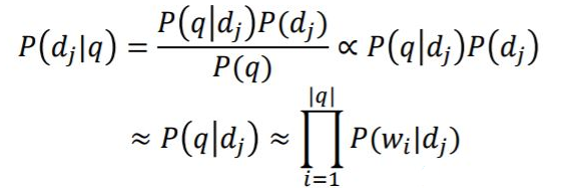
其中p(|
)為Document Model。
p(|
)公式如下:
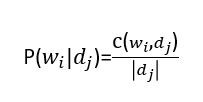
舉個例子也許會更清楚
EX1: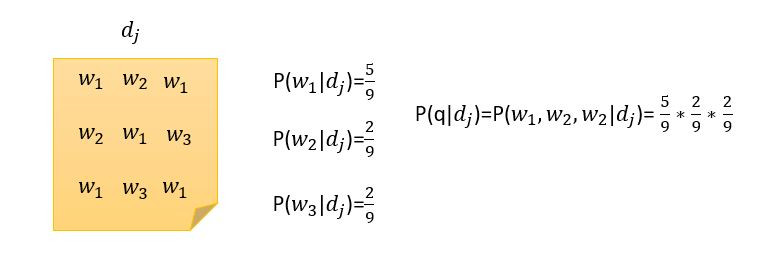
EX2: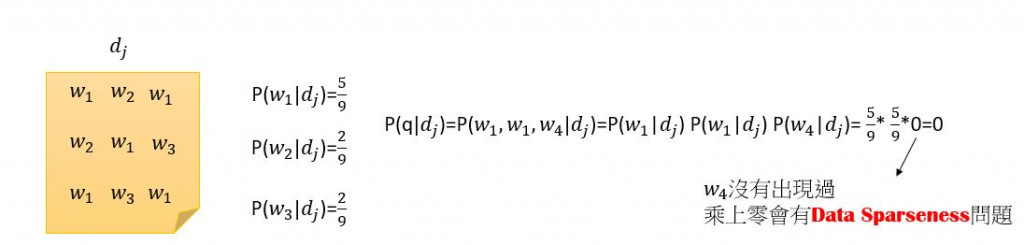
為了解決可能出現零次的問題,我們可以使用所謂的Smoothing來解決。首先,先來了解一下background model,background model就是收集好多資料把它集合成一大篇文章,計算每個word在這麼多文章中初先次數除以總次數,公式如下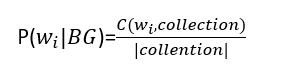
比較常用代表性的language model smoothing methods如下