在向量空間模型(Vector Space Model)中queries被表示成向量(Vector)形式,在同樣的向量空間中document也被表示成向量(Vector)形式。換句話說就是,queries和document都表示成向量,而其中權重(weight)為TF-IDF,如下圖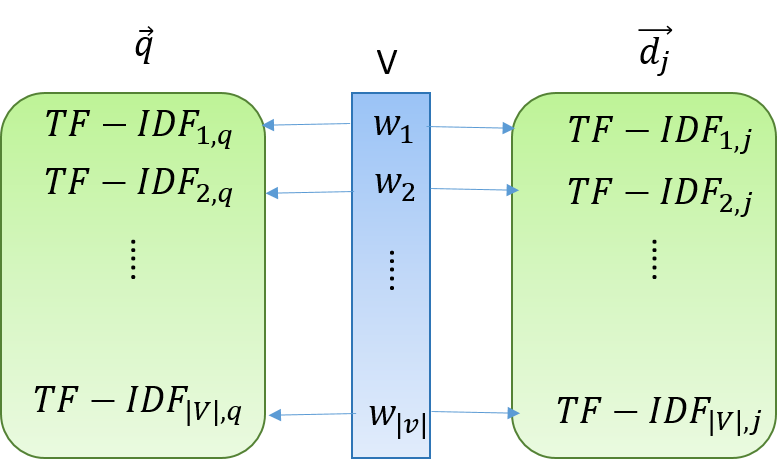
在昨天有提到關於TF-IDF公式表示若應用到表示queries和document權重,如下表:
我會比較喜歡用公式3表示queries和document權重(TF-IDF)
計算好queries和document的向量表示後就可以算兩者之間cosine similarity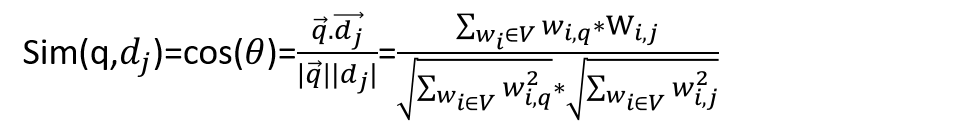
其中小,cos大;
大,cos小。
0<cos<1

