今天這一篇文章會介紹三個觀念分別為summarise()、dplyr pipline、遺失值的處理
首先分組彙總summarise()必須搭配group_by來使用,才能發揮summarise()函式的優勢,若只是單一使用summarise()是無法發揮作用。
之前對航班的資料集都是大範圍的了解,隨著對dplyr的了解對於資料的分析會聚焦化,舉例來說我們要知道每天航班平均出發時的延遲時間,面臨的第一個問題是一天內有幾百或幾千飛行航班,該如何處理
by_day <- group_by(flights,year,month,day)
summarise(by_day,delay=mean(dep_delay,na.rm = TRUE))
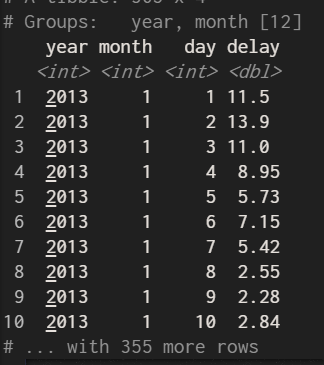
將年月日group_by存在變數by_day在使用summarise()算出每天的平均delay時間,這就是group_by與summarise()搭配的邏輯;記得一年前做台電104年-108年用電量分析,資料集內記錄每天的用電,當初並不是很了解dplyr,竟然用了很愚蠢的方法做了很久,若是使用dplyr相信我的報告會很精彩。
接著pipeline翻成中文稱管道,當初真的不是很理解這個名詞的意思,下面這張圖概略介紹pipeline的觀念
管道每一個結點都有一個閥,經過閥的調整或加壓將水送到下一個結點(閥),而在dplyr觀念跟管道觀念是一樣,也就是將資料送到下一個結點,這個結點經過處理後的結果,在送到下一個結點,在dplyr結點與結點之間的連結使用%>%,還是很抽象!我知道!直接舉例。
現在部長有一個需求每個目的地(機場),有多航班?所有航班到達該目的地的機場平均距離?以及所有航班平均到達dely時間,最後將上述的分析結果繪製出統計圖,我們會怎麼做
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
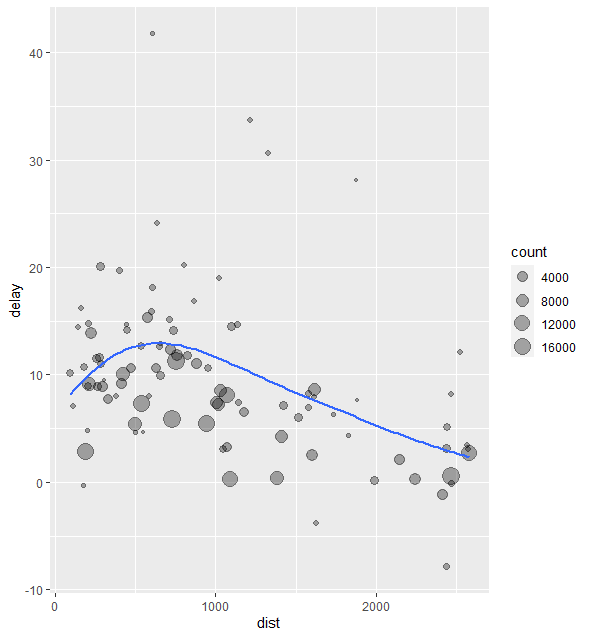
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)
是的!我們會分成四個部分先group_by機場-->summarise平均距離及delay時間-->篩選大於20道這個機場的航班-->在繪製統計圖;所以我們建立個變數做結果的存放,在將變數的結果拋過來拋過去,若導入pipeline後的程式碼,就變簡潔有力
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")
ggplot(data = delays,mapping = aes(x=dist,y=delay))+
geom_point(aes(size=count),alpha=1/3)+
geom_smooth(se=FALSE)
其實在上面的程式中有看到na.rm的參數,是的遺失值在大數據中是一個課題,有很多的文章都有講到遺失值的處理,但我個人感覺最好用的就na.rm,首先看不用na.rm會發生甚麼事
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
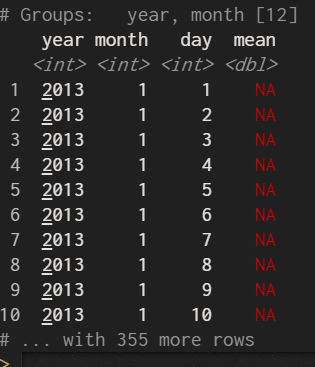
是的!遺失值全部但加入na.rm的結果
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay,na.rm = TRUE))
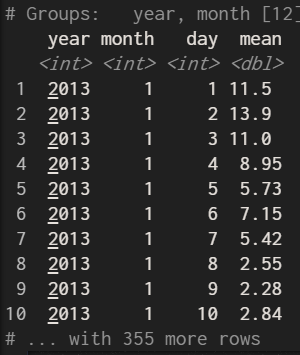
所以使用na.rm會將遺失值排除,只計算有值的資料平均,但na.rm在計算是可用的參數,所以針對多個變數是is.na,因此將dep_delay及arr_delay這兩個變數的遺失值排除並存在not_cancelled 變數中,為甚麼要這麼做,因為資料集說明遺失值為取消的航班,這對於分析沒有幫助,並且在計算平均時要重複下na.rm參數也很麻煩
未來我們會用not_cancelled 做更進一步的航班分析

