arrange()函數一句話講完就是對資料做排序,老實說,以前在寫一些程式不是很注重因為都很簡單,所以都不太在意,而當我接觸大數據時發現一個排序竟然在龐大的資料中是多麼重要。
舉例來說長官要知道飛機遲到時間最多的航班,由大排到小
arrange(flights,desc(dep_delay))
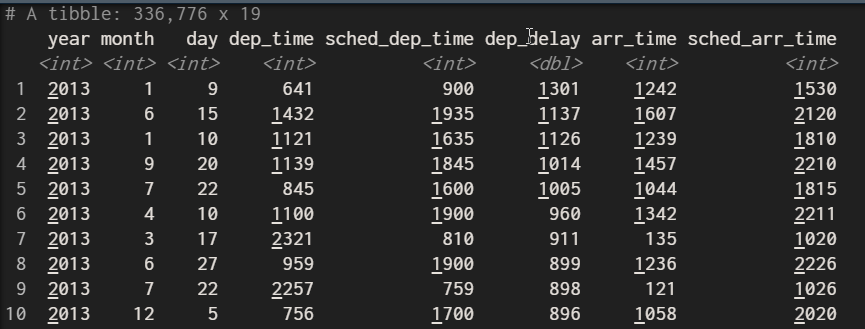
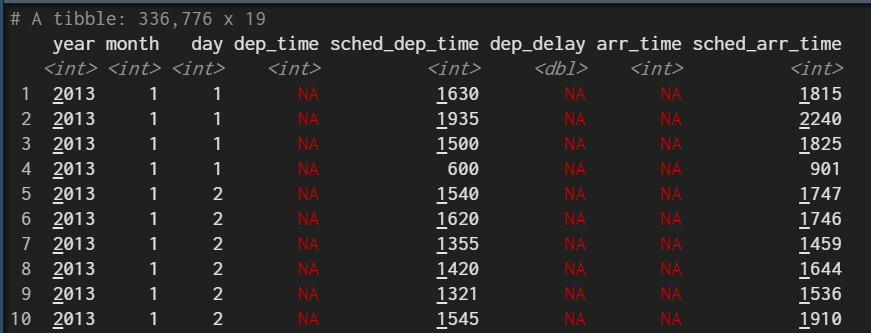
簡單吧!換一個方式將資料表的缺失值,在表格中前面顯示
arrange(flights,desc(is.na(dep_delay)))
換一個場景,交通部長說ㄟ...那個誰啊....幫我查一下以下資料,若不看程式碼答案的前題下,你能完成嗎?
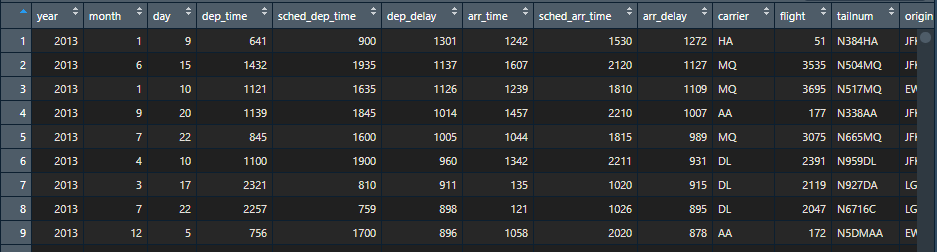
一、幫我查最延誤的航班以及最早離開的航班
View(arrange(flights,desc(arr_delay)))
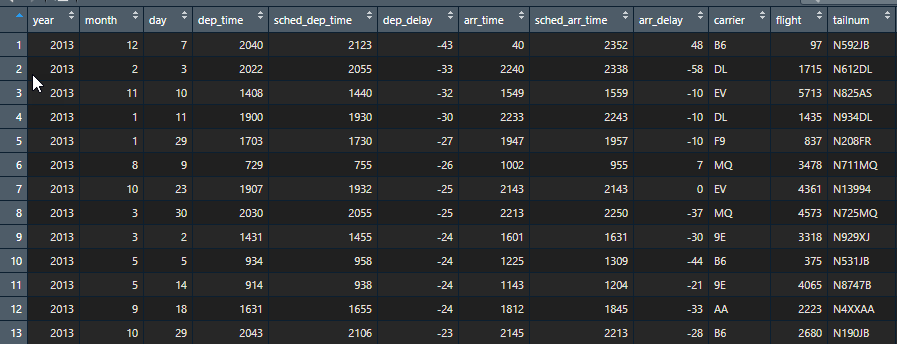
View(arrange(flights,dep_delay))
二、哪些航班旅行最遠?哪個旅行最短?
View(arrange(flights,desc(distance)))
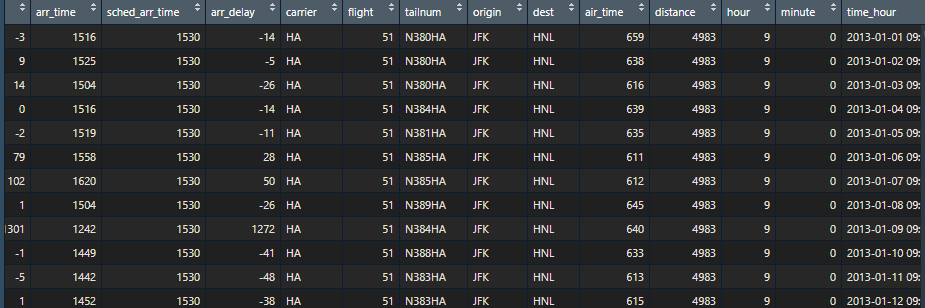
View(arrange(flights,distance))
select()函式剛開始也認為跟排序一樣就是這樣,有甚麼好討論!但是當你的資料集變數很多,select可以縮減你的變數讓你可以跟專注於資料分析上,以flights有19個變數,其實在看時就有點吃力,曾經遇過有30個變數時...那真的是...,select()允許您使用基於變量名稱的操作來快速放大有用的子集。
所以先來一點開胃菜,執行以下程式碼,而成果我就不貼了!
select(flights,year,month,day)
select(flights,year:day)
select(flights,-(year:day))
開胃菜吃完場景拉到美國交通運輸局會議現場,長官要知道航班資料以下資訊航班欄位太多了,我要看實際的起飛和到達時間、出發和到達的延遲
select(flights,dep_time,dep_delay,arr_time,arr_delay,everything())
今天這篇arrange()和select()函式很簡單,而不要輕忽這兩個函式,因為拆開單一了解真的很難有甚麼發揮,但配合其他函式就能凸顯這個函式的重要性。
mutate()這個函數中文稱為變異,有時覺得翻譯過來的名詞都有點水土不服,感覺都很偉大但又不知是甚麼東西,其實簡單講在既有資料集內的變數經過計算後產生新的值並用一個新的欄位儲存,這也是這變數主要功能,看起來繞口,直接看範例
首先我將航班的資料降維成為另一個資料子集
flights_sml <- select(flights,year:day,ends_with("delay"),
distance,air_time)
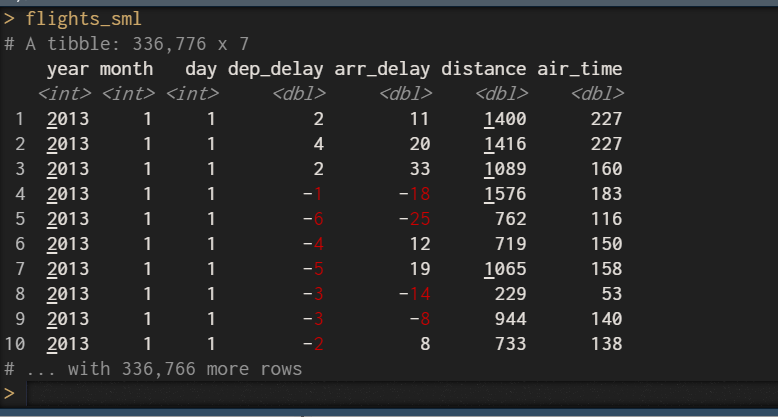
在程式中看到ends_with("delay"),這是將變數名稱中字尾有delay的變數篩選出來,這對於變數很多的資料集是一個很好用的參數。
接下來用出發延遲時間-到達延遲時間,以及計算飛行速度
mutate(flights_sml,
gain=dep_delay - arr_delay,
speed=distance/air_time*60)
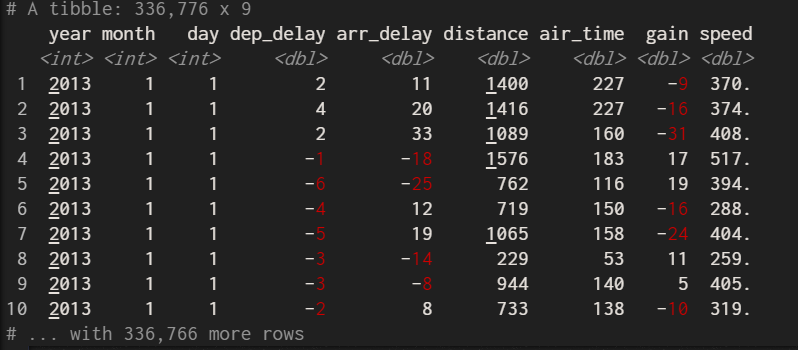
上圖中將gain以及speed在資料集最後出現,這也是mutate()函數的功能,當然mutate可以使用算術運算符:+,-,*,/,^; sum(x)計算總計的比例、mean(y)計算與平均值的差等等,依據分需求而定。
今天將這三個函數彙整在一篇中,因為要將這三個函數各自獨立一篇,內容會單薄其次這三個變數都需搭配其他函數才能發揮他們的功能,所以說是綠葉但沒有他們在資料分析中就無法前進。
下一篇就會進入dplyr套件分組彙總,也是dplyr套件的核心當然就會配合今日三個函數,對於資料分析就可變幻無窮

