一般來說論文分為兩個不同的方向簡單區分技術組和管理組,技術組就已演算法或技術框架等主題為主,管理組顧名思義以管理為題進行探討,而探討的方式大多以問卷的發放來了解目前管理的現況進而提出洞見,所以就需進資料的分析和統計。
因此,本篇先問卷的基本分析為主,換言之,就是填寫問卷的基本資料,以本篇為例以知識管理資訊系統為例,在一大型組織內的使用情況,而組織人數約3000人實際回收問卷為249份問卷,所以對這249份問卷使用知識管理資訊系統進行基本分析。
資料下載:https://drive.google.com/file/d/1-F2ja8KkyjRj9YT8JbuPpX6hBlgJQDUs/view?usp=sharing
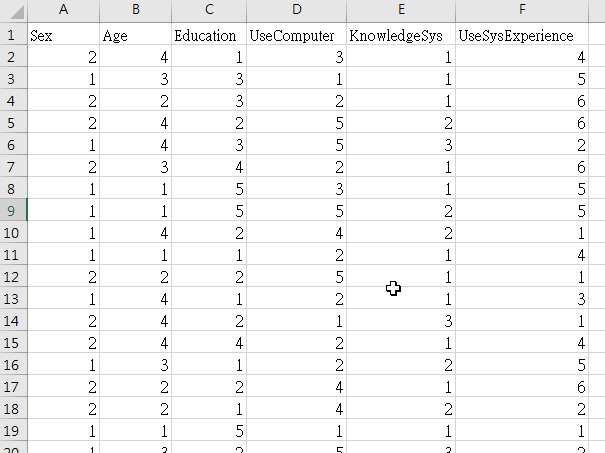
首先我們用看一下基本資料題目的設計,如下圖

回收的問卷資料用Execl作為紀錄,看到都以數字做紀錄,如男生為1女生為2,一句上面的題組設計變數,施測者勾選的項目依順序分別記錄為1 2 3 4 。
首先將資料在入至R中並觀看資料結構及資料集現狀
library(dplyr)
library(ggplot2)
library(stringr)
library(formattable)
Base <- read.csv("D:/工作區/我的筆記/程式筆記/R/Ironman Challenge/Paper/Base.csv",
stringsAsFactors=FALSE,
sep=",",encoding="UTF-8",na.strings=NA,fill=TRUE)
str(Base)
View(Base)
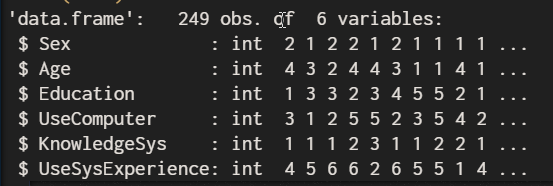
該資料集共有249筆資料6個變數,資料型態為int
如上所述依問卷的設計將施測者以順序作為紀錄,當然有些將問項的結果填人Execl檔案中,當然這也可以,但問卷數量多時難保不會貼錯!
所以將資料集的數字轉換為問項內容
#1=男生;2=女生
Base$Sex <- Base$Sex %>% str_replace_all(c("1" = "男生","2" = "女生"))
#1=21-30歲;2=31-40歲;3=41-50歲;50歲以上
Base$Age <- Base$Age %>%
str_replace_all(c("1" = "二十一至三十",
"2" = "三十一至四十",
"3" = "四十一至五十",
"4" = "五十以上"))
#1=高中/職以下;2=專科;3=大學;4=碩士;5=博士
Base$Education <- Base$Education %>%
str_replace_all(c("1" = "高中/職以下",
"2" = "專科",
"3" = "大學",
"4" = "碩士",
"5" = "博士"))
#1=一天數次;2=一天一次;3=兩三天一次;4=一個禮拜一次;5=從未使用
Base$UseComputer <- Base$UseComputer %>%
str_replace_all(c("1" = "一天數次",
"2" = "一天一次",
"3" = "兩三天一次",
"4" = "一個禮拜一次",
"5" = "從未使用"))
#1=有;2=有類似系統;3=目前單位無知識管理系統
Base$KnowledgeSys <- Base$KnowledgeSys %>%
str_replace_all(c("1" = "有",
"2" = "有類似系統",
"3" = "目前單位無知識管理系統"))
#1=從未使用過;2=3個月以下;3=4-6個月;4=7-9個月;5=10-12個月;6=1年以上
Base$UseSysExperience <- Base$UseSysExperience %>%
str_replace_all(c("1" = "從未使用過",
"2" = "三至個月以下",
"3" = "四至六個月",
"4" = "七至九個月",
"5" = "十至十二個月",
"6" = "一年以上"))
成果圖如下圖
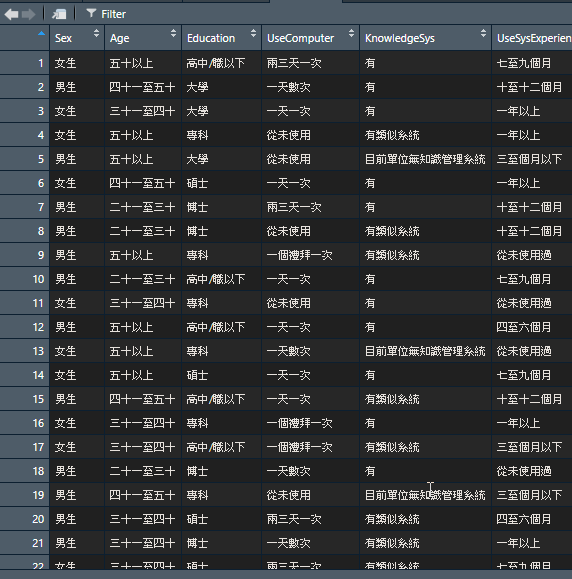
看起來要寫程式,為什麼不在Execl檔案做處理,當然可以!還是一句老話資料多時其時所花的時間和資料正確性都會有疑問,但是用程式處理的正確性及重複的使用性,比手動處理的時間成本效益高出許多。
下一篇會進行問卷的基本分析。

