Filebeat是使用Golang實現的輕量型Log採集器,佔用資源小有點取代Logstash的感覺。本質上是一個agent可以安裝各個機器上讀取相對應位置的Log,預先處理一些基本的資訊再輸出到其他的地方
Filebeat的可靠性很強,可以保證日誌至少一次的的輸出,也考慮Log的滾動換名之類的問題
Filebeat並不依賴於ElasticSearch,可以單獨存在。我們可以單獨使用Filebeat進行Log的採集然後往指定的地方輸出
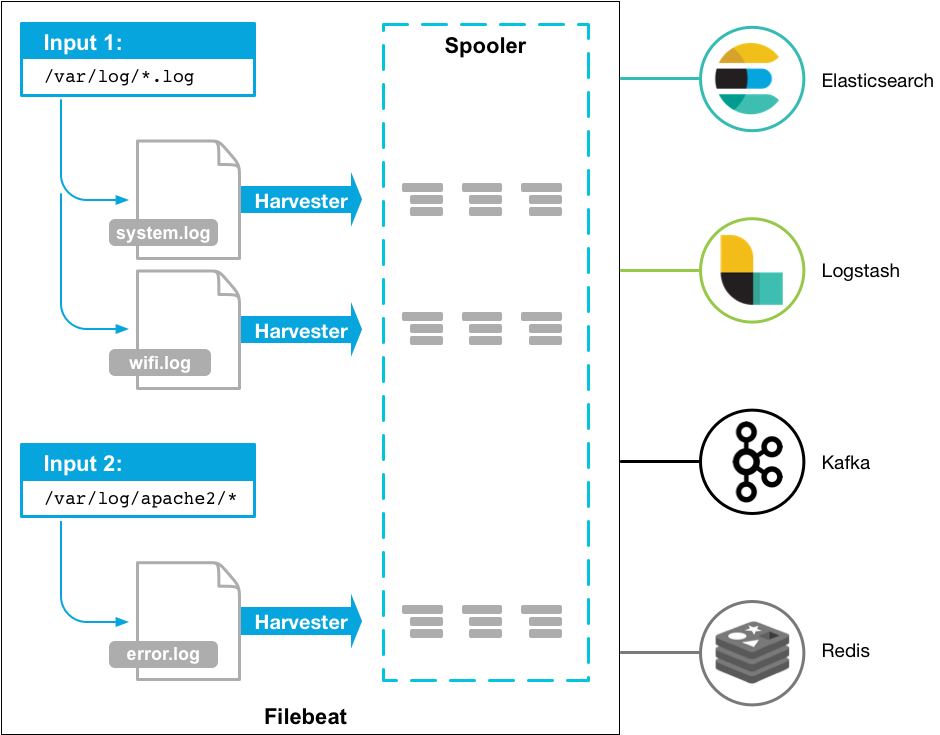
Filebeat主要由2部分構成:輸入嗅探(inputs)和收集器(harvester)。這些組件組合在一起,追蹤數據文件並且將至發送到你指定的目的地。
收集器負責讀取數據文件的內容。收集器會逐行的讀取文件並將讀到的數據發送到輸出。每個文件都會啟動一個收集器。文件的打開和關閉由收集器完成,這意味著在收集器運行期間,對應的文件描述符將會保持在打開狀態。如果正在被採集的文件被移動或者重命名,Filebeat會繼續讀取文件。這會產生一定的副作用,會一直佔用磁盤空間直到收集器關閉。默認情況下,Filebeat保持文件打開狀態直到close_inactive狀態到達。
關閉收集器後會產生如下結果:
對什麼時候關閉收集器,可對close_*配置項進行配置。
輸入嗅探管理所有的收集器並查找所有的數據源。如果輸入類型是log,輸入嗅探會查找磁盤上所有與指定路徑通配符匹配的文件並對探測到的每個文件啟動一個收集器。每個輸入嗅探運行在自己的Goroutine中。
下面的Filebeat配置示例指定了收集所有匹配指定通配符的所有log文件數據:
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
複製代碼Filebeat當前支持多種輸入類型。每種輸入類型都可以被多次設置。對log型輸入,輸入嗅探會決定是否啟動收集器,收集器是否正在運行,或者文件是否應該被忽略(查看ignore_older)。當收集器再次啟動文件大小發生變化時只會收集自上次關閉後新增的數據行。
Filebeat會持續保留每個文件的狀態並且定期將狀態刷新到磁盤上的註冊表文件中。這個文件狀態用於記錄收集器讀取文件數據的最新偏移量並保證所有的日誌行都被讀取發送出去。如果輸出目的端(例如:Elasticsearch或者Logstash)不可達,Filebeat會跟蹤最後發送的數據行,一旦輸出可用會繼續從最後停留的數據行開始讀取文件。Filebeat正在運行時,每個輸入嗅探的文件狀態信息也會被保存在內存中。當Filebeat重啟時,會從註冊表文件中重建狀態信息,收集器會根據重建的狀態信息繼續從最後已知的位置開始讀取數據。
對每個輸入嗅探,Filebeat會記錄它探測到的每個文件的狀態。因為文件有可能被移動或者重命名,僅靠文件名或者路徑就不足以標識一個文件。對此,Filebeat為每個輸入嗅探到的文件保存一個唯一的標識符以檢測文件之前是否被收集過。
補充一下,雖然Filebeat再多行處理可以把多個Log合併成一個,但對於docker container log這種超過16k會切成多個log然後要遇到log rotate時就無法處理了這部分原因在harvesters每個都是獨立的Goroutine無法互相溝通,log rotate時已經是換另外一個harvesters資料無法合併。有興趣的可以參考這篇https://github.com/moby/moby/issues/34620#issuecomment-636588696

