歡迎來到第四天,今天要著重在靜態網站的爬蟲,今天要進行第二層爬蟲。在昨天的小試身手中,我們嘗試了爬取 IT 邦幫忙首頁的標題,今天我們要進一步的進行第二層爬取,也就是內容爬蟲。
首先我們一樣要透過 Chrome 的 DevTool 進行觀察,承接昨天所做的內容,仔細觀察 <a> 會發現有兩個 attribute 分別為 class 和 href, class 在昨天被我們用來定位目標標籤,而 href 的角色就是今天的重頭戲第二層爬蟲。
若我們隨意舉其中一個 <a href="https://ithelp.ithome.com.tw/questions/10200233" class="qa-list__title-link"> 為例,當 href 的 https://ithelp.ithome.com.tw/questions/10200233 是這篇文章完整的 URL。(由於這也是單純的 GET 請求,我們就不贅述 network 的細節)
接著我們隨意點選進入一篇文章,並觀察其 HTML 架構,由於這次的目標是擷取文章內容與程式碼,圖片不在這次的目標之中(會於之後的文章分享)。
觀察了這個頁面的 HTML 會發現所有的文章標題、內容、圖片、相關主題等全部都在 <div class="markdown__style"> 這個標籤中,而這次的重點為標題與文字,我們透過這樣的觀察,已經鎖定了目標 HTML Tag 的特性。
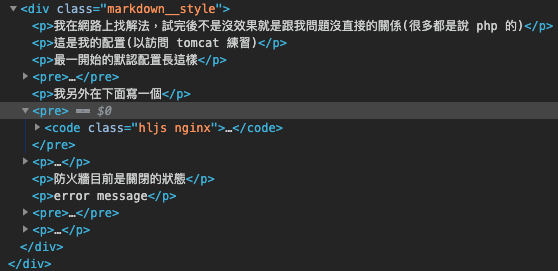
首先我們先進行文章的 HTML 處理,由於我們只需要擷取標籤中的文字,因此我們可以調用 etree 的 tostring 函式,擷取目標標籤底下的所有文字內容。
def article_parse(link):
response = requests.get(link)
html = etree.HTML(response.text)
mk = html.xpath("//div[@class='markdown__style']")[0]
return etree.tostring(mk, method='text', encoding='unicode', pretty_print=True).strip()
再來我們將昨天的文章標題的爬蟲程式做簡單的修改並結合上方寫好的函式
import requests
from lxml import etree
def article_parse(link):
response = requests.get(link)
html = etree.HTML(response.text)
mk = html.xpath("//div[@class='markdown__style']")[0]
return etree.tostring(mk, method='text', encoding='unicode', pretty_print=True).strip()
response = requests.get("https://ithelp.ithome.com.tw/") # GET 請求
html = etree.HTML(response.text)
element_list = html.xpath("//a[@class = 'qa-list__title-link']") # 利用 Xpath 定位出目標標籤
articles = {} # 宣告一個字典去儲存文章標題與對應的內容
for element in element_list:
articles[element.text.strip()] = article_parse(element.get('href'))
我們完成了一個簡單的爬蟲,順利的完成第二層爬蟲。今天就先這樣,我們明天繼續。


 iThome鐵人賽
iThome鐵人賽