今天我們將利用 requests 和 lxml 進行簡單的爬蟲,爬蟲的目標為 IT 邦幫忙首頁中所有的新聞標題。
首先我們先打開 Chrome DevTool 並進入 "Network" 分頁,在 Chrome 搜尋欄中輸入 https://ithelp.ithome.com.tw/ ,此時你會在 DevTool 中看到 https://ithelp.ithome.com.tw/ 這個請求的細節
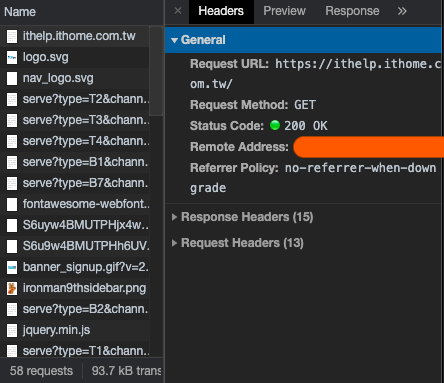
我們會發現這個請求是屬於 GET 的請求,並且沒有任何 Parameters 的存在,因此我們只需要使用 requests 中的 get 函數呼叫網站。
當我們確定了請求方式後,代表著我們可以順利拿到請求後的回應,並針對回應進行 HTML 的頗析,由於我們的目標是新聞主題,新聞主題為靜態資料,因此我們可以直接透過 DevTool 左上角的選擇功能,選擇網頁中我們想要頗析的段落
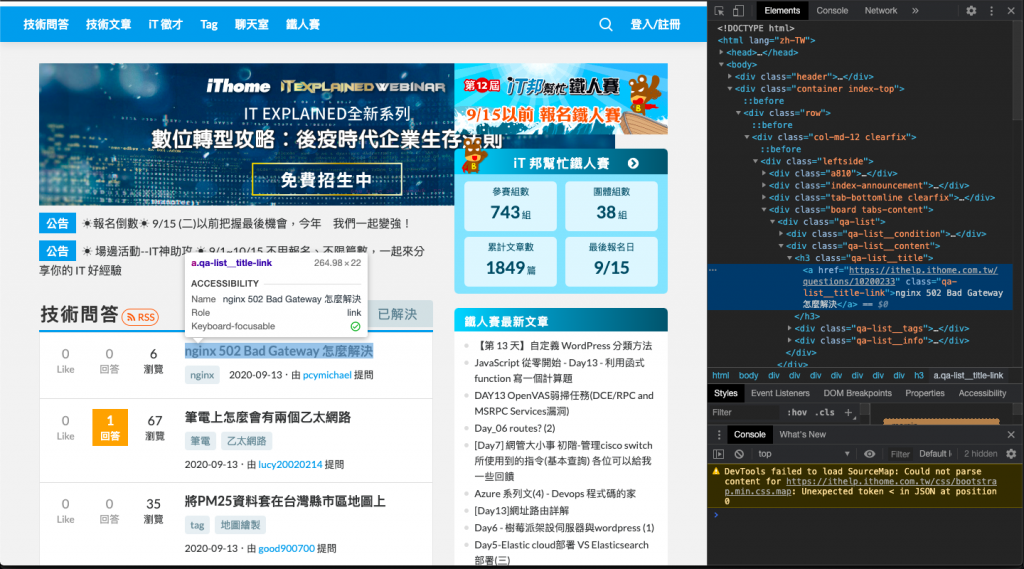
點選至想要頗析的段落,我們會發現 DevTool 在相對應的 HTML 段落出現反白。我們可以根據這個 HTML 標籤進行頗析,"nginx 502 Bad Gateway 怎麼解決" 這段文字中最直接相關的是 HTML 中的 <a>,我們嘗試使用標籤中 class 名稱 "qa-list__title-link" 搜尋,會發現首頁中共有 30 筆結果,稍微檢查一下這 30 個結果正是首頁中所有的標題,因此這個 class 名稱就成了很好的頗析關鍵字。
現在根據觀察的解果來寫一段簡單的程式來爬取 IT 邦幫忙首頁的所有標題並顯示出來。透過 requests.get()送出 GET 請求,並透過 lxml 中的 etree 進行 HTML 解析,利用 Xpath 定位出所有包含 class ='qa-list__title-link' 的 <a>,最後將所有標籤內容列出。
import requests
from lxml import etree
response = requests.get("https://ithelp.ithome.com.tw/") # GET 請求
html = etree.HTML(response.text)
element_list = html.xpath("//a[@class = 'qa-list__title-link']") # 利用 Xpath 定位出目標標籤
for element in element_list:
print (element.text.strip())
今天就先到這邊,明天開始更多態網站爬蟲。


 iThome鐵人賽
iThome鐵人賽