前幾天我們介紹了mongodb,他是一個以文檔為主的非關聯式資料庫,資料庫中的每一個單位,我們都把它想像成是一個文檔,然後我們就在眾多的文檔之中,尋找我們要的答案。今天我們要再換一個視角,來看在非關聯式資料庫中,一樣重要的圖資料庫。
這邊我們使用地圖資料庫是Neo4j。今天我們會簡單的幫大家複習一下「圖」的概念,還有為什麼圖資料庫與其他兩種資料庫有所不同。最後,一如往常的,我們會很快速的設定一個大家可以跟著動手做的操作平台。
這裡的圖不是畫一張畫 ,他指的是表示物件之間關連的視覺表現。我下面放了一張 Neo4j 官網 的示意圖,一個「圖」由兩個物件構成: 的一個是節點 (Nodes) 一個是邊 (Edges)。傳統的關聯式資料庫會把這三個東西分別存在三個關係表中。Neo4j 認為,這樣的設計對於處理大量關係的查詢會非常花時間,因為你需要去鏈結非常多的關聯表。相對的,如果用的是文檔式的非關聯式資料庫,除非我們把所有可能的關聯都放到一個文檔中,不然也是需要查詢很多個資料集合,才能獲得我們要的答案。
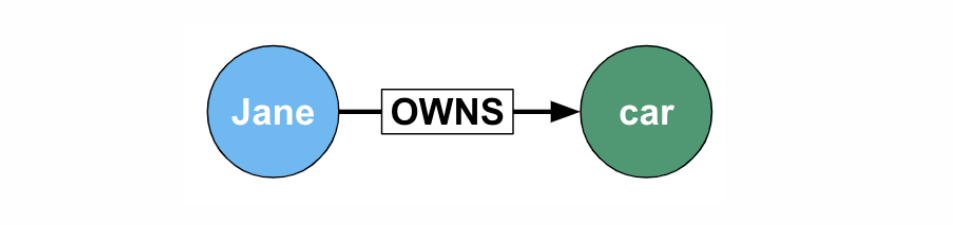
但是,生活中真的有這麼多關聯式查詢嗎?
我今天在大安區的女巫店聽到鄭宜農*唱去你的旅程。
光這個敘述句鐘就可以看到 (女巫店)—[位於]→(大安區),(鄭宜農)—[演唱]→(去你的旅程),(鄭宜農)—[表演於]→(女巫店),三個物件的三種關聯。在傳統的資料庫中我必須要放置在 商店、地點、歌手、歌曲四個關聯表,還要有中間關係的關聯表。現在我只需要很簡單的做一個 「圖的遍歷」(Graph Traversal),就可以從節點「走」到下一個節點。這時候如果我想知道哪個歌手在大安區唱過歌,我只需要抓出大安區這個節點,把所有指向大安區的歌曲都挑出來(沒錯~中間可能會要先「造訪」歌手或是地點的節點!) 就可以找到我想要的答案。現在有點抽象,但是晚點我們開始寫查詢的時候就會比較有感覺了。
接下來幾天我們會在沙盒裡面介紹和嘗試 Neo4j 的查詢語言 — Cypher。今天我們循慣例註冊、匯入範例資料、然後開始第一個查詢。
選擇中間 banner 綠色的按鈕

沙盒原則上三天會過期~但是他可以延長。另外他也可以很快的創建新的沙盒。如果要開始正式使用他,可以參考官方的桌面板或是伺服器版本的安裝程式/指令。
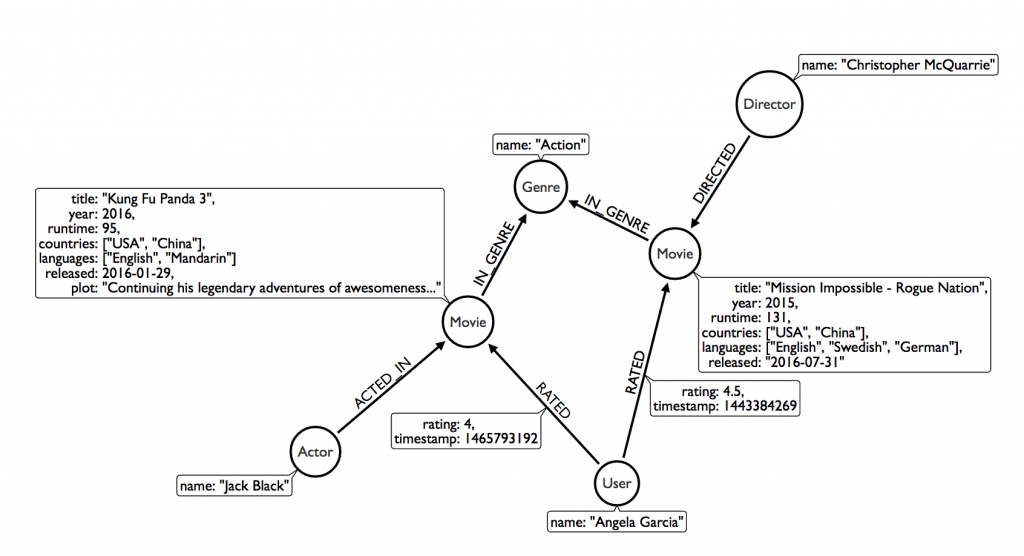
查詢前我們先看一下這個資料庫有哪些資料吧! 這裡的資料有電影、電影類別、導演、演員、觀影人。
(取自資料集的介紹文件)
讓我們在上面的指令列輸入
Match (n)-[r]->(m)-[l]->(k)
Return n,r,m,l,k
Limit 20
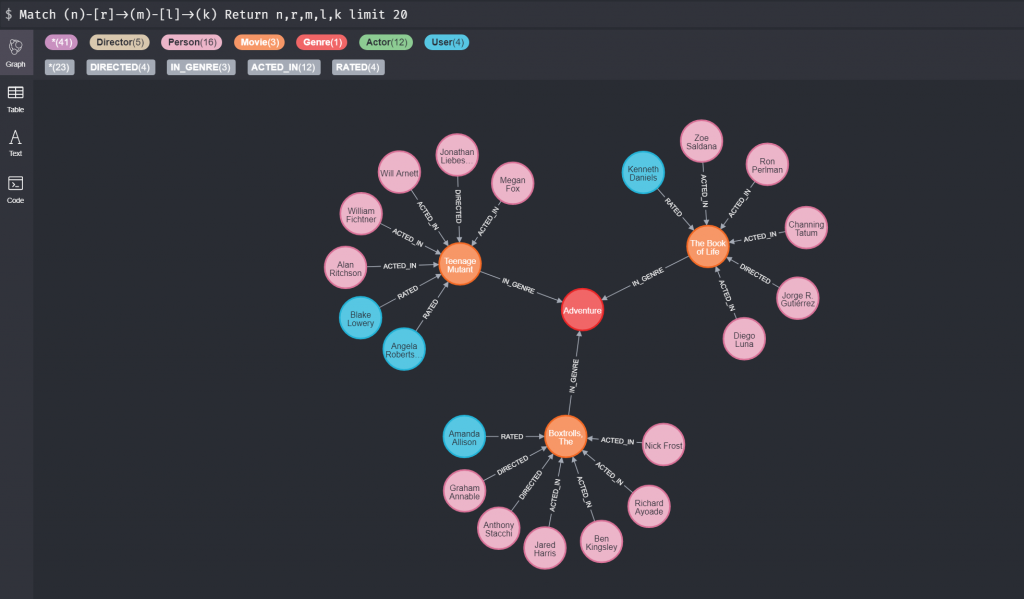
當然這是視覺化後的結果,如果是系統讀取的會是數個回傳的 JSON
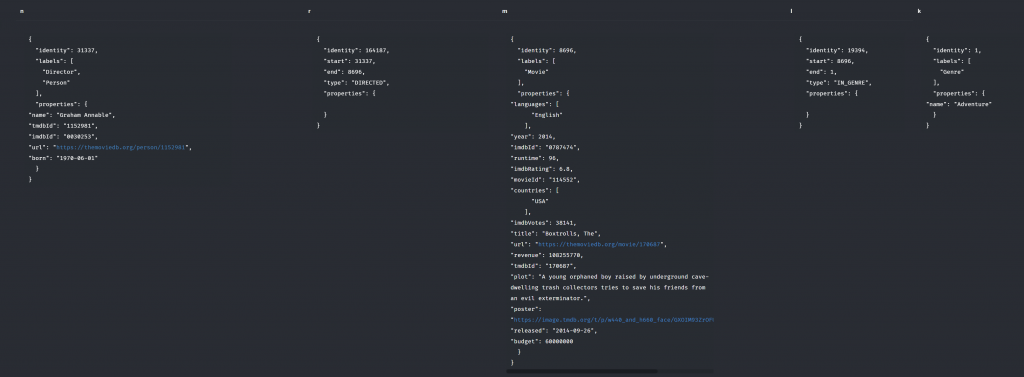
這到指令到底在做什麼呢?又分別式麼意思呢? 看起來好像跟SQL有點像哀~明天我們來解釋!
*超好聽的趕快去聽啦


 iThome鐵人賽
iThome鐵人賽