Neo4j 的 查詢語言叫做 Cypher*,他們強調這個語言的源自於讓人容易理解的ASCII繪圖。所以,在對應資料庫的關係時,他會寫出這樣的語法:
(m:Movie)-[:IN_GENRE]->(g:Genre)
Cypher 是一種宣告式語言,希望可以直接用程式語言表明你要找的東西,而不是你要如何找到你要找的資料。所以看上面的這個查詢,他就像是:

所以輸入上面這段指令,Neo4j 就會把圖資料庫中所有長這樣的資料都回傳出來。完整的語法我們用 Match 來尋找,Return 把找到的東西回傳,並加上一個Limit 限定只先回傳50個符合條件的資料。
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre)
Return m, g
limit 50
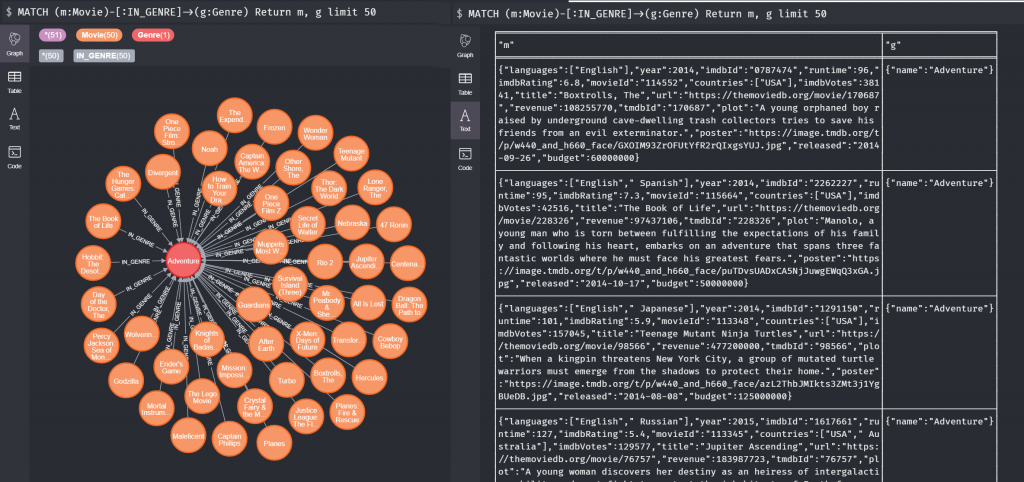
左邊我們用圖像呈現這50個電影和類別的關聯,右邊可以更清楚的看到這些資料。
既然每個節點(Nodes) 都有不同的屬性,我們可以在近一步的放上更精細的查詢條件,把上面的 Match 替換成下面這個就可以查找試喜劇類別的電影了。
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre{name:"Comedy"})
當然這個關係可以寫得更複雜:
Match (p:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(p)
Return p, m
Limit 15
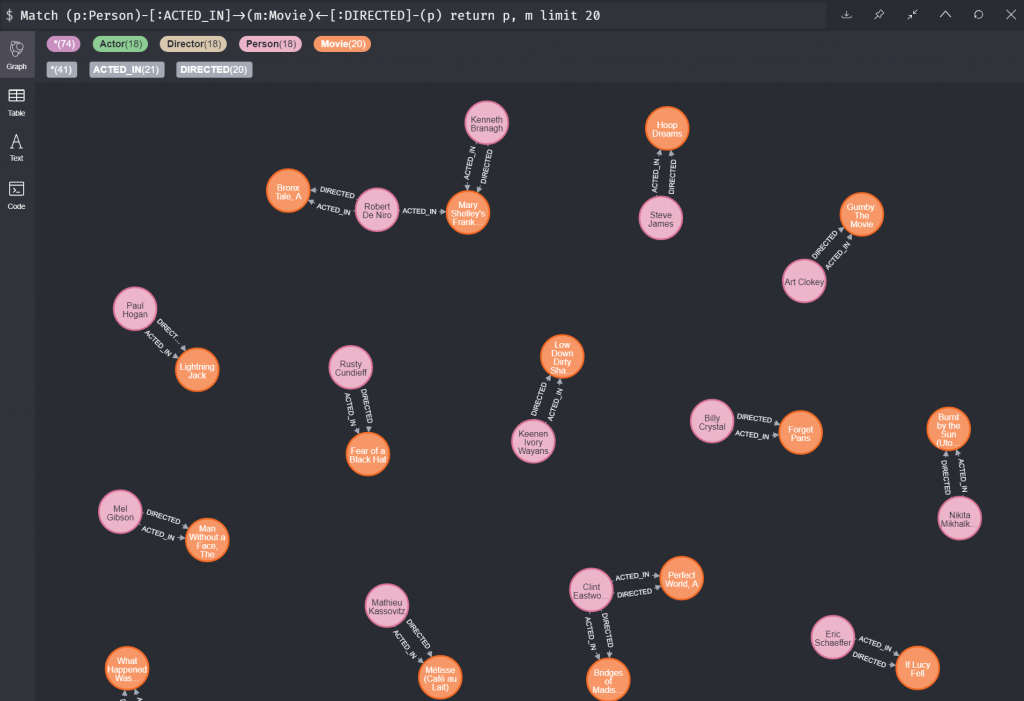
這個指令就是希望可以找到同樣是導演也是演員的人和電影。左邊開始我們說我們要找一個叫做 p 的節點有在 m 電影中演出,同時,p也要執導這部m電影。有注意到我在冒號前面寫的就是一個代名詞。
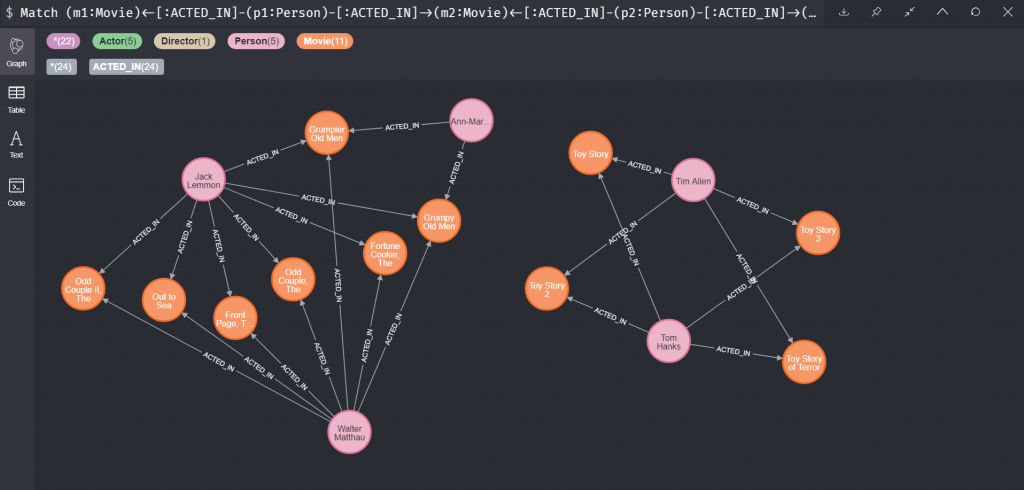
所以如果我今天想查找的是兩個人同時都有演兩部電影,這裡我們就要用 m1, m2 表示那兩部電影;同時我們要用 p1, p2 來表示兩個演員。
Match (m1:Movie)<-[:ACTED_IN]-(p1:Person)-[:ACTED_IN]->(m2:Movie)<-[:ACTED_IN]-(p2:Person)-[:ACTED_IN]->(m1)
Return p1, p2, m1, m2
Limit 20
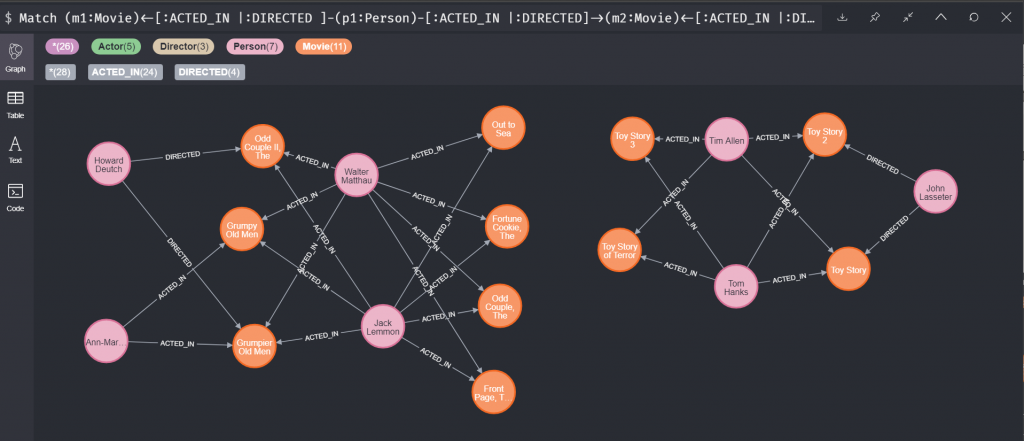
最後我們也可以對中間的關聯做一些更動,例如說我現在不管是演出或是執導都可以,就可以用中間的直槓來表示:
Match (m1:Movie)<-[:ACTED_IN |:DIRECTED ]-(p1:Person)-[:ACTED_IN |:DIRECTED]->(m2:Movie)<-[:ACTED_IN |:DIRECTED]-(p2:Person)-[:ACTED_IN |:DIRECTED]->(m1)
Return p1, p2, m1, m2
Limit 20
查詢的過程不外乎要加上過濾掉我們不要的資訊的片段。下面這段Cypher 用 Where 做塞選,把使用者對電影評分低於三分或是高於八分的留下來。有沒有回想起SQL中的 Select-From-Where? 這邊我們的Select 寫在 Return 那段Cypher,我們不需要處理 From 因為 Cypher 可以透過我們畫出的關係找到資料,最後用Where 來做塞選
Match (u:User)-[r:RATED]->(m:Movie)
Where r.rating < 3 or r.rating > 8
return u.name, r.rating, m.title
limit 10
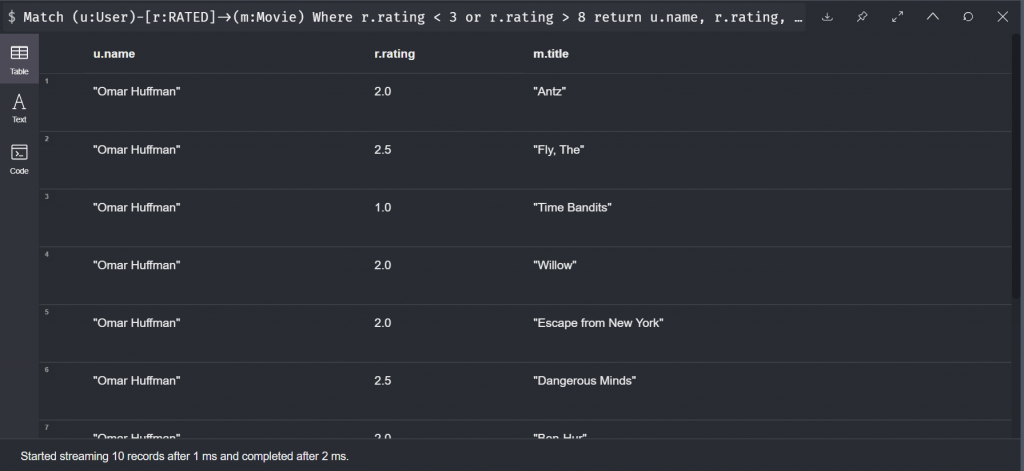
跟SQL很像,我們可以在 Where 區段中做字串、數字等各種比對
Match (u:User)-[r:RATED]->(m:Movie)
Where u.name =~ 'John.*'
return u.name, r.rating, m.title
limit 10
這裡我們就只回傳使用者姓名是 John 開頭的資料組合,我們也可以寫成
Match (u:User)-[r:RATED]->(m:Movie)
Where u.name Starts with "John"
return u.name, r.rating, m.title
limit 10
寫到這邊,基本的語法: Match — Where — Return 應該蠻好上手的。認真推薦讀者可以動手玩玩看!
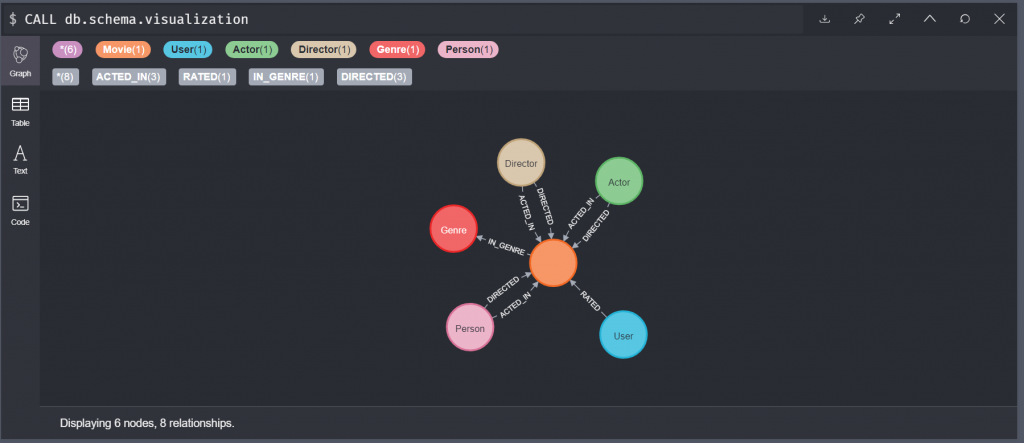
另外補充一個我覺得很好用的指令
CALL db.schema.visualization
這個指令可以把資料庫的資料視覺化,就知道這個資料庫中可以做哪些查詢囉!
*Cypher 翻譯應該是暗號,我也是沒有很懂為什麼要叫這個名字XD


 iThome鐵人賽
iThome鐵人賽