首先要先說明,在寫今天的文章的時候才發現,原來MongoSH 還不支援寫比較繁瑣的 Javascript,所以今天範例中的程式碼應該是無法直接運行的,必須要用傳統的 MongoDB Server + Mongo Client 來使用,有點可惜。但是Map Reduce 這個觀念實在重要,那就還是解釋一下囉!
Map Reduce 可以用很簡單的例子來解釋,假設今天我們要製作一百萬份的潛艇堡,這時候我們可以把所有的步驟拆成: 切食材和組裝食材兩個部分。我們讓很多員工只需要作切食材的工作,並把相同的食材放到同一堆中,同時,我們讓另外一堆員工負責取用組裝這些食材。前著我們把進來的原料先作處理,這個部分我們叫他作 Map,後者我們把處理過後的資料作處和,我們稱之為Reduce。
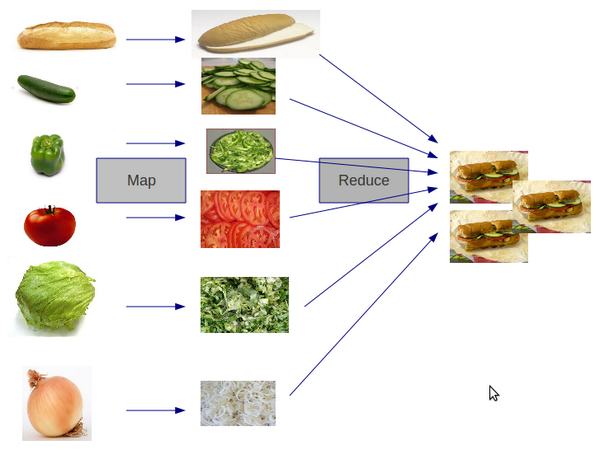
(圖片取自網路: https://clojurebridgelondon.github.io/workshop/functions/map-reduce-sandwich.html)
之所以要有這樣的設計是因為我們要應付大量的數據。很多時後數據在整理就像要作百萬份的潛艇堡一樣,不可能在一張桌子,一個人快速地完成。這時候我們可能就需要租用大量的人力和場地,實際上來說就是要增加機器幫我們運算,又稱作分散式系統。分散式系統的優點是你可以隨時加入機台也可以隨時移除機台,但是缺點是,你必須要盡可能的確保每個機台可以儲存的資料是平均的而且每個員工的工作量也不會差異太大。Map Reduce 的好處就是,因為 Map 中每個人作的事情是一樣的, Reduce 也是,所以我可以隨時增加或減少機台(員工),並且我不需要去管員工到底在處理什麼步驟。延續剛剛潛艇堡的例子,有了 Map ,員工不管切的是番茄還是小黃瓜都沒差,因為你知道切完之後番茄切片都會放到放番茄的籃子,而小黃光也會放到小黃瓜的籃子。同樣的Reduce的時候我也不用去分配不同員工到底要作什麼,反正就去每個籃子拿材料放在一起就可以了。
讓我們放入今天會使用到的資料
db.grades.insertMany([
{ _id: 1, student: "Alice", score: 10 },
{ _id: 2, student: "Alice", score: 40 },
{ _id: 3, student: "Bob", score: 60 },
{ _id: 4, student: "Bob", score: 90 },
{ _id: 5, student: "Bob", score: 100 },
{ _id: 6, student: "Calvin", score: 75 },
{ _id: 7, student: "Calvin", score: 65 },
{ _id: 8, student: "Dora", score: 40 },
{ _id: 9, student: "Dora", score: 20 },
{ _id: 10, student: "Dora", score: 60 }
])
我把學生資料化簡了,今天我們來算每個學生的平均資料。在 Map-Reduce的世界中,我們要把資料分堆,那這裡每一堆就會是一個學生的成績。接下來Reduce的時候我們就會把所有數值算出平均
Map: 每一個工人拿到數據只會傳出學生姓名和分數
var mapStudent = function() { emit(this.student, this.score); };
Reduce: 負責每個學生「堆」的工人就把數據作平均計算
var reduceAverage = function(keyStudentName, valueScores) {
return Array.avg(valueScores);
};
最後放入 Map-Reduce 的 Pipeline 中
db.grades.mapReduce(mapStudent , reduceAverage , { out: "map_reduce_grade" })
/*output
{
"result" : "map_reduce_grade",
"timeMillis" : 148,
"counts" : {
"input" : 10,
"emit" : 10,
"reduce" : 4,
"output" : 4
},
"ok" : 1
}*/
這邊系統就跟你說,我總共處理了接收了10比輸入,map 送出了10比數據,總共分成4堆,最後輸出了4組資料。之所以input 和 emit 可能不同就在於有時候如果輸入的資料是學生每一個科目的考試成績,我們可能會每一個成績單獨輸出。最後我們用下面這個來觀看結果
db.map_reduce_grade.find()
/*output
{ "_id" : "Alice", "value" : 25 }
{ "_id" : "Bob", "value" : 83.33333333333333 }
{ "_id" : "Calvin", "value" : 70 }
{ "_id" : "Dora", "value" : 40 }
*/
這樣就大功告成啦!
MongoDB 的介紹就在這邊先告一個段落,明天我們開始玩Neo4j 圖資料庫!

