我們今天要辨識是0~9的手寫數字集,堪稱是AI界的Hello World,Keras模組有提供此資料集,我們先載入它們。
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train裡包含了我們要訓練的圖片,y_train是標籤,標記了對應的x_train是哪個數字,x_test、y_test則是最後用來驗證我們的模型使用,觀察一下資料集的大小。
print(r'x_train.shape = ', x_train.shape)
print(r'y_train.shape = ', y_train.shape)
print(r'x_test.shape = ', x_test.shape)
print(r'y_test.shape = ', y_test.shape)
我們先隨機抓個40張圖片來觀察一下,沒有matplotlib的就裝一下。
import matplotlib.pyplot as plt # pip install matplotlib
from random import randrange
plt.figure(figsize=(16,10),facecolor='w')
for i in range(5):
for j in range(8):
index = randrange(0, 60000)
plt.subplot(5, 8, i*8+j+1)
plt.title("label: {}".format(y_train[index]))
plt.imshow(x_train[index], plt.cm.gray)
plt.axis('off')
plt.show()

為了方便訓練我們把圖片從28乘28的二維圖形轉換成1維長784的向量,然後將0~255的圖片,縮到0~1的範圍。
x_train = x_train.reshape(60000, 784)
x_train = x_train / 255
x_test = x_test.reshape(10000, 784)
x_test = x_test / 255
對於特徵的值進行修改在一些特徵數值差異大的情況下,可以保證我們不管從哪個隨機點開始下降,到達局部或全局最佳解的時間都是差不多的,各位可以看看圖中的紅線與藍線,假設X軸的特徵為每坪的價格,Y軸的特徵為房子的坪數,這兩個的數字的差異可能到1000倍或以上,但在本例中像素最大值就是255,效果可能沒有很顯著。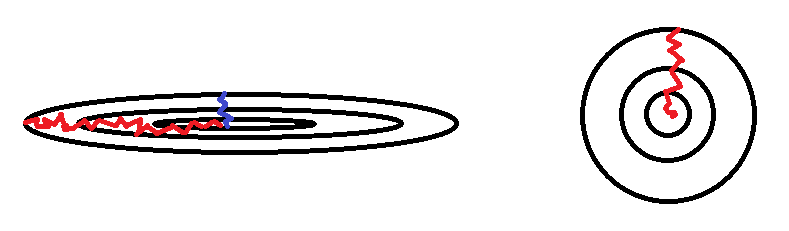
我們將訓練十個分類器,我們並不是訓練一個分類器直接輸出0~9,而是訓練10個二元分類器,我們把標籤轉換為One-Hot編碼,例如0將轉換為1000000000;5則是0000010000。
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)

