快到了,讀完這篇之後的 coding 實作就可以穩紮穩打!
當 model 剛建好要開始跑的時候,都要有初始參數(先選好從山坡的哪裡開始往下走)。要隨便選嗎?還是全部設成 0?還是有邏輯的設?怎麼選擇看起來是小事,事實上會大大的影響 training 的收斂跟效率。
首先把 weights 全設 0 或常數的話,每個 node 得到 activation 的值都會相同,那麼在 backpropagation 的時候,各層的每個 node 計算出的 gradient 也相同,也就是他們都在學同一件事!多麼沒效率啊。這叫做 symmetry。
為了要 break symmetry,隨機 initialize 是個可行的選擇。但要注意的是,因為是隨機的,初期可能會輸出接近 1 或 0 這種極端的結果,而在 binary classification 裡如果答案剛好相反的話,loss 就會飆高。避免這種初期不穩定的方法是隨機值不能太大。
事實上學者投入很多心力研究到底怎麼 initialize parameters 最好,也有了一些不同於隨機的 initialization 方法能表現得很好。例如 Xavier / He initialization 將 weights 照下面的分佈 initialize:
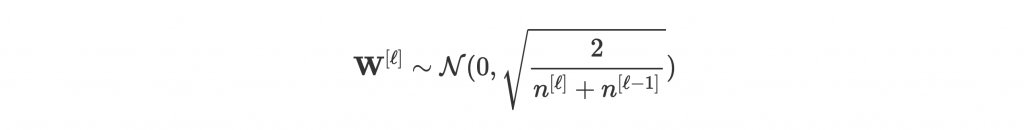
背後的原理比較複雜,也不是深入探討的重點,只需要記得自己的 network 用 Xavier initialization 做初始化就行了。
又來個大主題了!幾篇前提到用 gradient descent 做 parameter optimization,但實際操作起來細節非常多。一次要拿多少量的 data?步伐要多大?步伐怎麼隨著訓練調整?我們就來一次介紹吧。
做 deep learning 需要的 dataset 是非常大量的。一次把所有 data 送進 network 做訓練叫做 batch gradient descent。Batch gradient descent 的好處是,因為 data 多,你能找到的 gradient 是比較準確的,也就是每次都能找到最佳路徑往下走。但是當 data 量非常巨大的時候,每一輪 training 都會花非常久的時間。花這麼久只走一步,那就算這一步很精準,還是會花很多時間才能到達 optimum。
那能不能一次一筆 data 做 training 呢?可以的,這叫做 stochastic gradient descent (SGD)。SGD 的每一步都非常快速,但壞處是找到的 gradient 不一定指向正確方向,因此雜亂無章的腳步要到達谷底也不一定那麼快速。
因此最多人採用的方法是 mini-batch gradient descent,也就是每次輸入 m 筆 data。如此一來能大致找到方向,且每一步都很快能計算出來。另一個好處是因為 data 大小為 m,電腦在處理這種 vectorized data 能更有效運算,訓練速度也能因為善用硬體而提升不少!

—— SGD、mini-batch、batch gradient descent 優化路徑比較。[3]
講完一次訓練多少 data,再來就是步伐也很重要。你可以選擇呆呆地每次都往 gradient 的方向走固定的步伐大小:
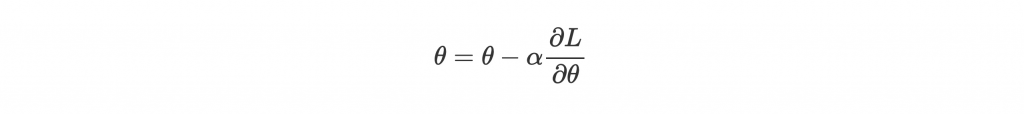
也可以視情況調整步伐。我們就來介紹一些比較常用的 optimizor 來增加學習效率跟穩定性!

—— Optimizor 優化路徑比較。[6]
Momentum 啟發自物理學上的動量。Wiki 對動量是這麼定義的:「一個物體的動量指的是這個物體在它運動方向上保持運動的趨勢」,也就是一顆球往谷底滾,會沿著動量的方向越滾越快。
那麼原本跟著 gradient 走的方法似乎就違背物理學了,因為他只考慮當前點的坡度而不是運動的趨勢。考量趨勢做 optimization 就是加入 momentum 的意義,可以讓訓練更快速穩定。
具體來說,我們會維護一速度 v,初始值是 0,並累積過去所有的 gradient(這邊變成加速度的意義)而成現在的趨勢。為了沿著趨勢走,每次的更新會讓跟當前趨勢同方向的 parameter 有更多的 update,反之違背趨勢的我們就不更新太多:
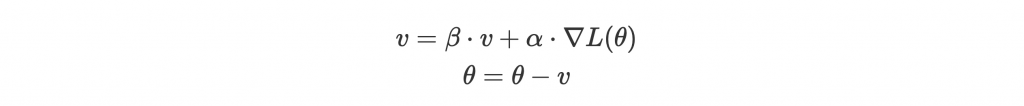
跟
都是可調整的 hyper-parameter,
是 learning rate,
類似摩擦係數的概念,常設為 0.9。
Adagrad 也是為了穩定性發展出來的 optimizor,但原理有些不同:在更新的時候每個 parameter 都會根據情況,有不一樣的 learning rate。前面獲得關注多的 parameter,learning rate 會小一些,反之亦然。想像一個上上下下不穩定的曲線,會因此而被拉長,變得更平順。
那關注度怎麼定義?作者是這麼定義的:
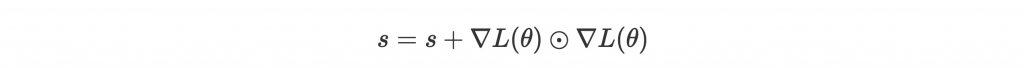
代表 element-wise multiplication。也就是關注度是累積過去 gradient 的大小,坡度越大 parameter 越受關注。
為了讓關注高的學慢一點,我們把它放進分母 scale 一下 learning rate:
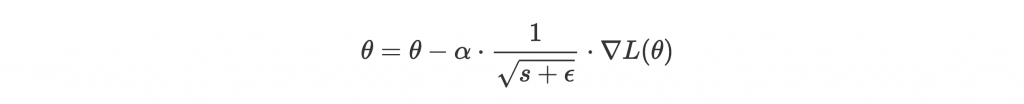
是很小的值,避免除以 0。開根號則是實驗證明有他才能訓練好。
但 Adagrad 有個致命的缺點,就是 s 無限累積,那 learning rate 就無限減小,最後根本學不到東西。我們來看看 RMSprop 怎麼解決這個問題。
好的,修正方法很簡單,就是讓關注度 decay:
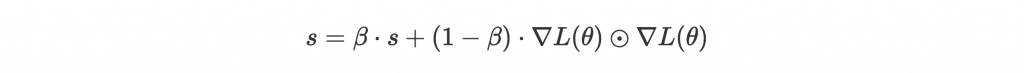
Update 就跟 Adagrad 一樣:
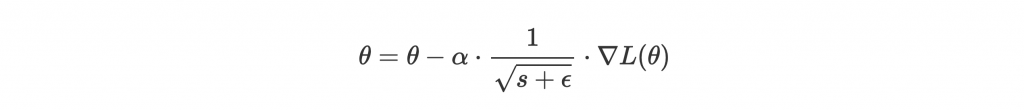
常見的值為 0.9, 0.99, 0.999。
Adam 結合了 RMSprop 和 momentum 的優點,實際的效果也常常是最好,因此被廣泛使用。不知道選哪個 optimizor 的話那就選 Adam 吧。
結合的方法就是跟 momentum 一樣,維護一個 v 來做 update,接著後面就是 RMSprop,但用 v 取代原本的 gradient:
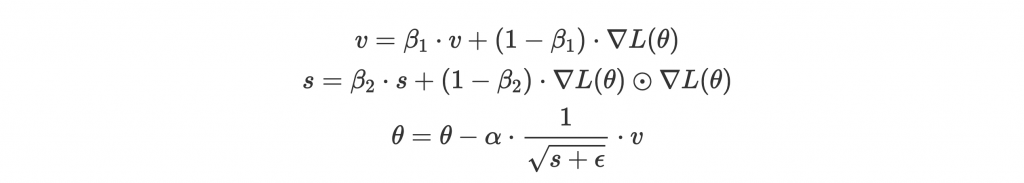
在原始 paper 裡作者也貼心的提供了建議的 hyper-parameter setting:。

