昨天的文章中我們可以用Match — Where — Return 寫出基本的查詢了。接下來我們就是要來做資料個分類和簡單的統計,也就是SQL中的 Group By。
用SQL邏輯,試著看看下面這段Cypher在做什麼
match (u1:User) -[r:RATED]-> (m1:Movie)
where m1.year = 2000
with u1.name as user, avg(r.rating) as art
return user, art
limit 50
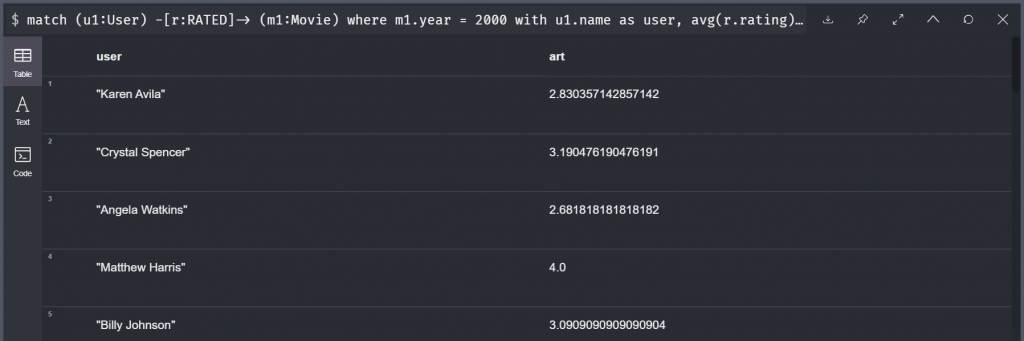
這就是 Cypher Group By 的寫法。這邊我們用 With 先選出 Group By 所看的行數,以及應該如何把欄位整合。這邊的例子就是把每個關聯中的評分分數給平均起來。所以完整的來看這個查詢就是在看,針對 2000 年發布的電影,觀影人對於當年所有電影的平均給分。
我們也可以針對上述的查詢指令做出些微的變動:
match (u1:User) -[r:RATED]-> (m1:Movie)
where m1.year = 2000
with u1.name as user, count(m1.title) as num_movie, avg(r.rating) as art, collect(m1.title) as mov_lst
where num_movie >= 70
return user, num_movie, art, mov_lst
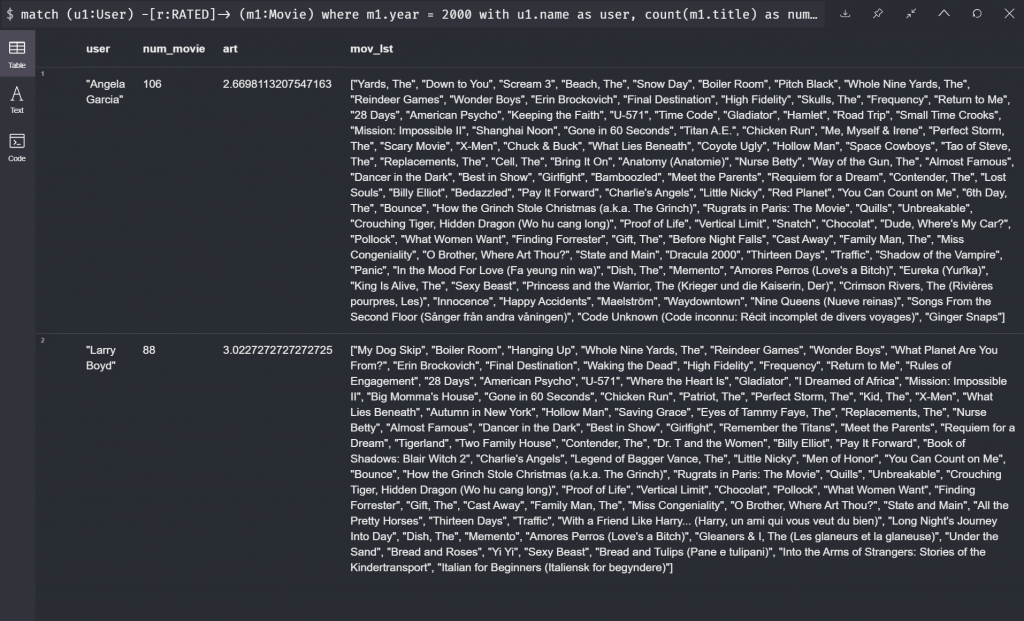
這邊我們要新增了兩個新的東西: 第一個是 Count — 在這邊我們可以數出同一個使用者底下,評分了幾部電影。第二個是透過 Collect 把這些電影的名稱全部放到一個陣列當中。既然我們可以先計算出了這些數值,當然就可以再新增一個 Where 篩選,我們這裡留下評論過超過70部電影的使用者的資料。
在上一個小節,我們在 mongodb 有介紹 unwind 這個功能。這個指令最重要的工作就是將一個陣列的資料,拆成多個資料列讓我們更可以作分析。
match (u1:User) -[r:RATED]-> (m1:Movie)
where m1.year = 2000
with u1.name as user, count(m1.title) as num_movie, collect(m1.title) as mov_lst
where num_movie <= 10
unwind mov_lst as mov
with mov as movies, collect(user) as user_lst
return movies, size(user_lst) as Users order by Users DESC
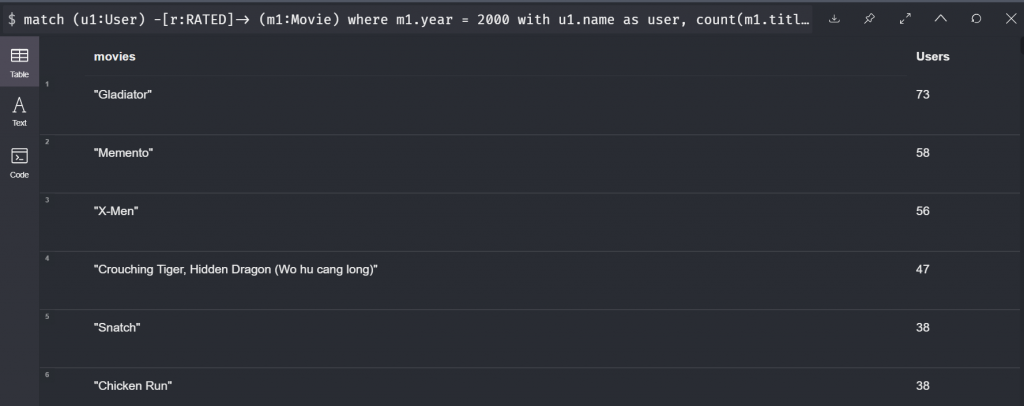
類似於上面的查詢,我們再第二行先選出2000年生產的電影,接下來我們先把電影歸類,在第三行我們算出了每個影評人平分過的電影數量和電影名稱陣列。在第四行我們過濾掉評分超過10部電影的影評人。這時候重點來了: 我們透過 unwind 把電影陣列拆解開,像這樣:
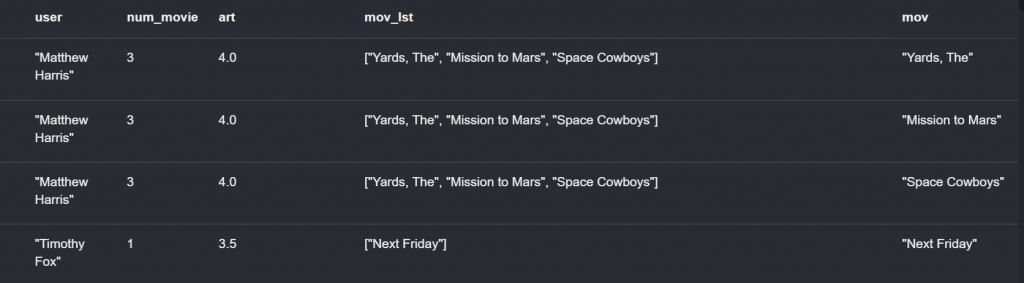
他會保存原本著陣列但是新增一個欄位,欄位中每個資料都存在這個陣列。
回到剛剛的指令,第六行我們就可以透過拆出來的電影再做一次Group By,這次我們蒐集的是所有的影評人的名稱。第七行我們把電影和影評人的個數依照影評人多寡排列。
所以退一萬步看,我們再找的就是到底那些很少評論電影的影評人最常去看哪一部電影?
這個之所以留到這邊解釋是因為我們現在在用的範例資料庫比較難實際操作和示範他的用法。所以這部分就只好看我的說明囉。假設我們現在有一個資料及記錄人和人是否認識彼此
(:Person)-[:Knows]-(:Person)
這時候我在做 Match 的時候就可以這樣寫
MATCH length=shortestPath((p1:Person)-[:Knows*..4]-(p2:Person))
Return p1, p2, length
這樣子的查詢會在圖裡面面找中間經過小於四個節點的所有對
所以如果圖長這樣:
(John)-[Knows]-(Mary)-[Knows]-(Alex)-[Knows]-(Alice)
他就會還傳 John, Mary, 1 ; John, Alex, 2; John, Alice, 3; Mary, John, 1; Mary, Alex, 1; Mary, Alice, 2...以此類推。*表示可以重複出現,後面 .. 給的是一個範圍,所以如果寫的是 2..4 就是找關係在2-4可以到達的兩個節點。這種查詢方法有助於我們找到一定範圍中所有的節點,例如說一個人可能認識的朋友之類的。 上面我們還多寫了 length=shortestPath() 可以幫助我們把兩個節點之間的最短距離給讀出來。
今天我們介紹了三大進階 Cypher 寫法,明天最後一天介紹 Neo4j。


 iThome鐵人賽
iThome鐵人賽