修改好資料庫,可以讓中文放進去囉,現在就把我們所需要的資料放進Azure的資料庫
本篇使用:Day13_save2330ToAzureDB.py
開始前需要一些作業,因為欄位不足,加上可以更自動化一點,所以修改一下資料表結構。
我們需要把DailyPrice,新增一個交易日期:TradeDate,自動產生CreateTime。
如果要重新建立,就是在Azure Data Studio內使用:
CREATE TABLE DailyPrice(
ID UNIQUEIDENTIFIER PRIMARY KEY default NEWID(),
TradeDate DATE Not NULL,
StockID VARCHAR(32) NOT NULL,
Symbol VARCHAR(10) NOT NULL,
OpenPrice DECIMAL(9,3) NOT NULL,
HighPrice DECIMAL(9,3) NOT NULL,
LowPrice DECIMAL(9,3) NOT NULL,
ClosePrice DECIMAL(9,3) NOT NULL,
Volumn INT NOT NULL,
CreateTime DATETIME NOT NULL default GETDATE(),
)
但我們已經建立過了,所以要輸入:
ALTER TABLE dbo.DailyPrice ADD TradeDate DATE;
並且讓CreateTime可以自動產生輸入時間:
ALTER TABLE dbo.DailyPrice ADD DEFAULT GETDATE() FOR CreateTime;
這樣我們新Table就準備好,可以進行輸入了
直接服用:
import pyodbc
import requests
import json
import numpy
import pandas
server = "ey-finance.database.windows.net"
database = "finance"
username = "我的帳號"
password = "我的密碼"
driver = "{ODBC Driver 17 for SQL Server}"
# API位置
start_time = 1577808000 # 2020/1/1
end_time = 1600531200 # 2020/9/20
stock_code = 2330
stock_market = "TW"
address = f"https://query1.finance.yahoo.com/v8/finance/chart/{stock_code}.{stock_market}?period1={start_time}&period2={end_time}&interval=1d&events=history&=hP2rOschxO0"
# 使用requests 來跟遠端 API server 索取資料
response = requests.get(address)
# 序列化資料回報
data = json.loads(response.text)
# 把json格式資料放入pandas中
df = pandas.DataFrame(
data["chart"]["result"][0]["indicators"]["quote"][0],
index=pandas.to_datetime(
numpy.array(data["chart"]["result"][0]["timestamp"]) * 1000 * 1000 * 1000
),
columns=["open", "high", "low", "close", "volume"],
)
"""匯入資料"""
# 連線到Azure
with pyodbc.connect(
f"DRIVER={driver};SERVER={server};PORT=1433;DATABASE={database};UID={username};PWD={password}"
) as conn:
with conn.cursor() as cursor:
# 把Dataframe 匯入到SQL Server:
for index, row in df.iterrows():
cursor.execute(
"""INSERT INTO finance.dbo.DailyPrice
(StockID, Symbol, TradeDate, OpenPrice, HighPrice, LowPrice,
ClosePrice,Volumn)
values(?,?,?,?,?,?,?,?)""",
"dd95bd5328b14d489d6f6e649233c774",
"2330",
index,
row.open,
row.high,
row.low,
row.close,
row.volume,
)
conn.commit()
print("finished")
首先,使用for迴圈加上df.iterrows(),把每一行資料抓出來,接著在cursor.execute()內把資料逐一放進去。這時候可以用參數去代替我們的資料,這是因為在製作dataframe的時候,已經把index和每個欄位都處理好,就可以直接使用結構化的資料與名稱,是不是很方便
最後再把我們的指令送出去:conn.commit(),這樣就大功告成。
輸入完畢後,檢查一下,看到就都進去囉~~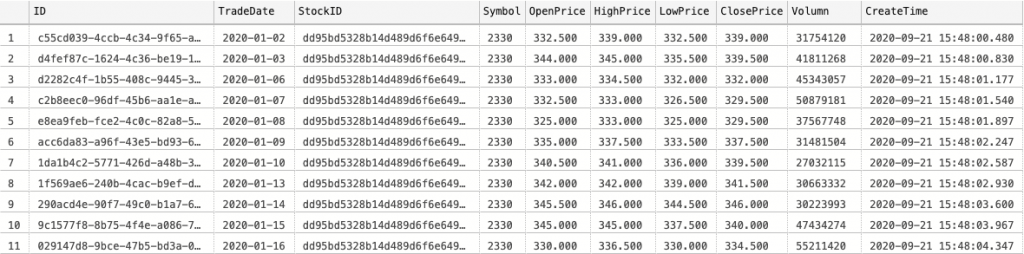
參考資料:

