這段稍微說明了如果圖很大張的話,U-net的處理策略。
One important modification in our architecture is that in the upsampling part we have also a large number of feature channels, which allow the network to propagate context information to higher resolution layers.
跟FCN-Alexnet 相比,在 upsample 的時候也有大量的 feature channels (feature maps)。
As a consequence, the expansive path is more or less symmetric to the contracting path, and yields a u-shaped architecture.
所以變成了類似對稱的結構。
The network does not have any fully connected layers and only uses the valid part of each convolution, i.e., the segmentation map only contains the pixels, for which the full context is available in the input image.
而且沒有 fully connected layers
This strategy allows the seamless segmentation of arbitrarily large images by an overlap-tile strategy (see Figure 2).
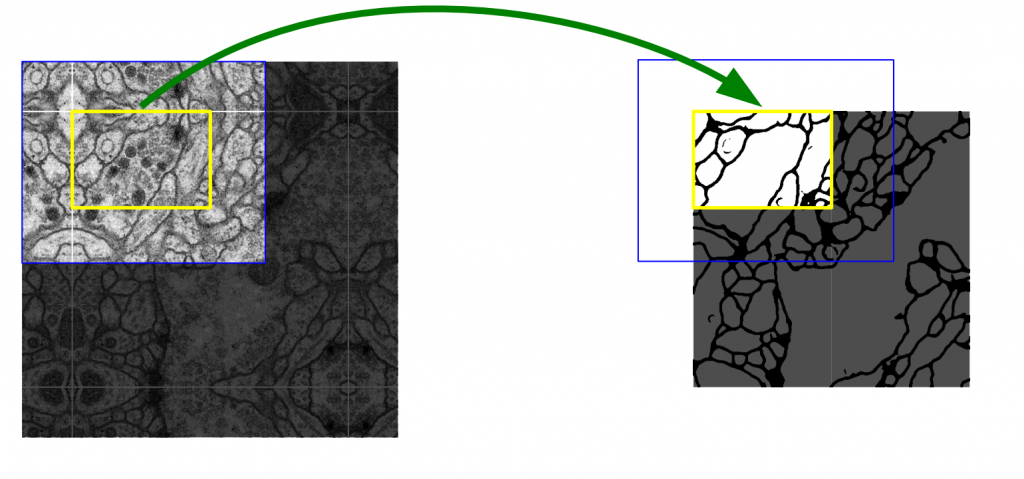
邊界可以利用鏡射來解決。(所以padding的差異更小了)
To predict the pixels in the border region of the image, the missing context is extrapolated by mirroring the input image. This tiling strategy is important to apply the network to large images, since otherwise the resolution would be limited by the GPU memory.
主要是受限於GPU,不然圖太大容易難以預測邊界。
[9] Fully Convolutional Networks for Semantic Segmentation
這篇是Fully convolution network的始祖吧?直接改自Alexnet,將隱藏層改為upsample層。
大圖的推論,Unet有提出一個解決方案,算是可以依定程度解決邊界不准的問題。
[0] U-net

