技術文章
技術問答
My Project
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
第 12 屆 iThome 鐵人賽
DAY
10
0
AI & Data
今晚,我想來點經典NLP論文。
系列 第
10
篇
[D10] GSDMM (Yin and Wang, 2014) 2/2
12th鐵人賽
victor.huang
2020-09-24 20:32:58
1670 瀏覽
分享至
Key Points
實驗資料集:
Google News
Google news 有自己做分群。
爬了 2013/ 11/ 27 這天的新聞
11,109 篇,總共 152 群
但 Google News 的分群真的是符合人類直覺的分群嗎?
作者說人工檢查後發現品質很不錯。
分成三個子資料集,用來測試不同的文章長度下的表下如何。
只有標題 TitleSet (TSet)
只有摘要 SnippetSet (SSet)
標題摘要均有 TitleSnippetSet (TSSet)
Tweets
用 Text REtrieval Conference (TREC) 的資料
TREC 是由 query 與 High relevance result 構成的
由此把每個 query 當作一個群的概念,對應的 high relevance result 則作為群。
總共 2472 篇文章,分成 89 個群。
前處理
轉小寫
去掉非英文字和虛詞
用 NLTK 做 stemming
排除掉長度小於 2 或者大於 15 的字
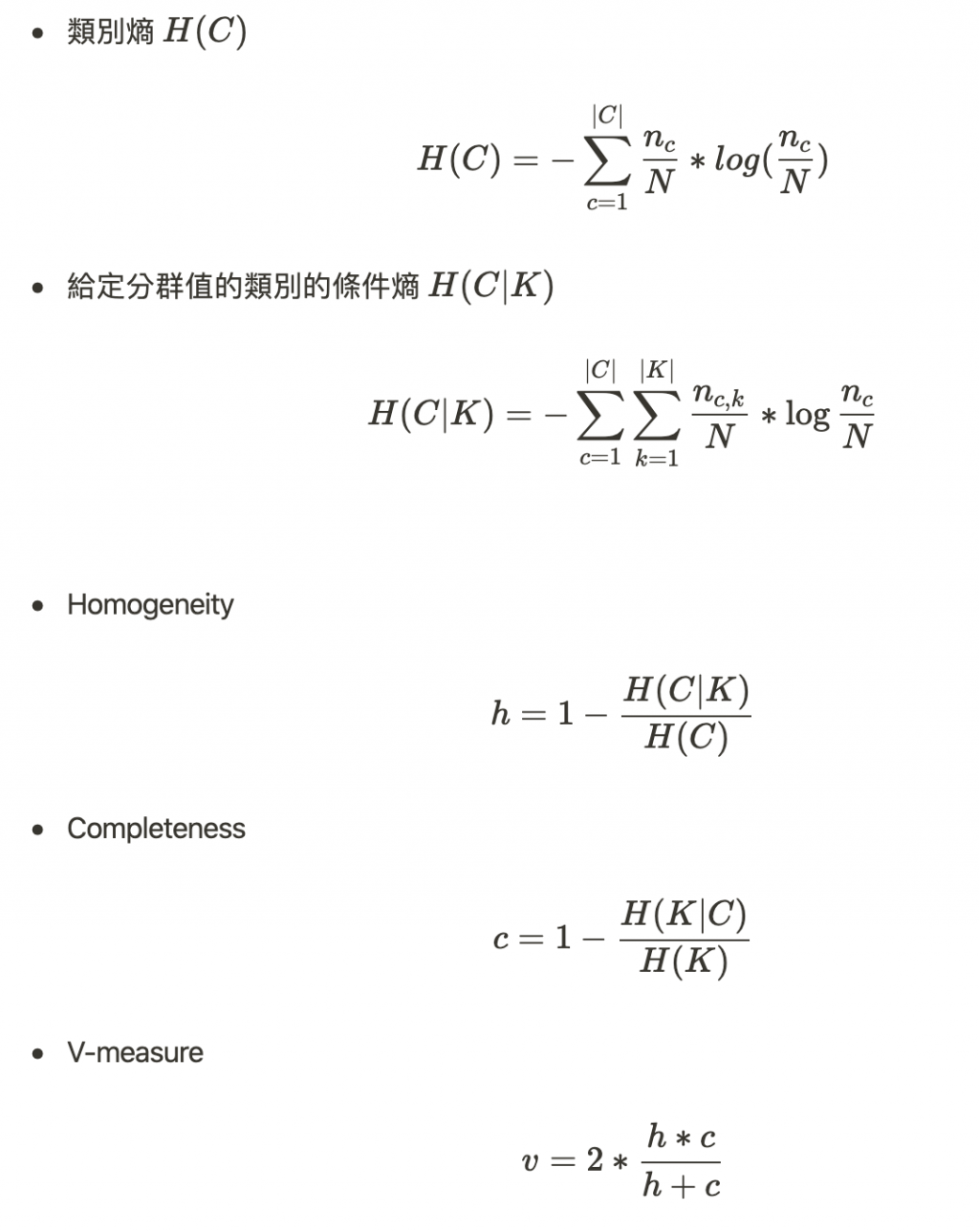
評估指標
還有 Adjusted Rand Index (ARI) 和 Normalized Mutual Informa- tion (NMI)
實驗結果
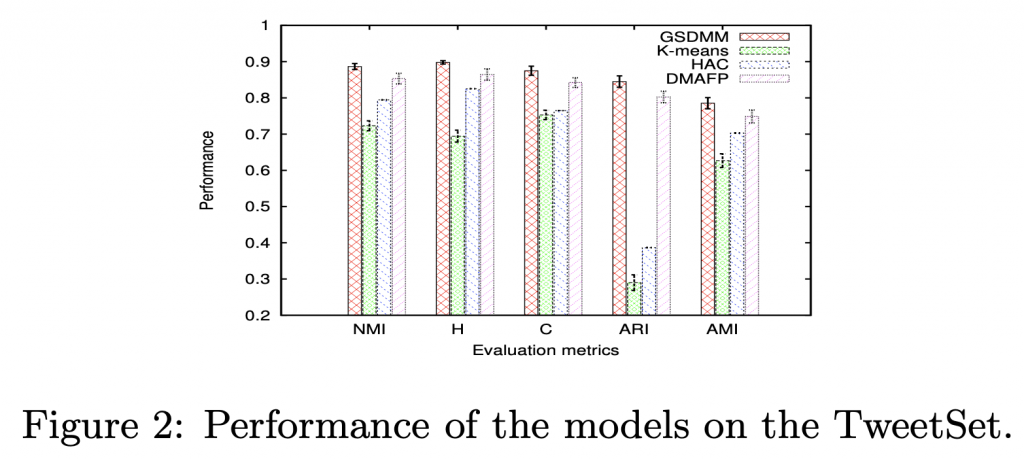
TweetSet
Kmeans: K 設定為真實的群數
GSDMM: 回合數 30、 α = 0.1、 β = 0.1
GSDMM 全方位的優於舊有方法。
GSDMM 優於 kMeans 因為可以自由的選擇群數
GSDMM 優於 DMAFP 因為他不是用 EM 算法,不會落入區域最佳解。
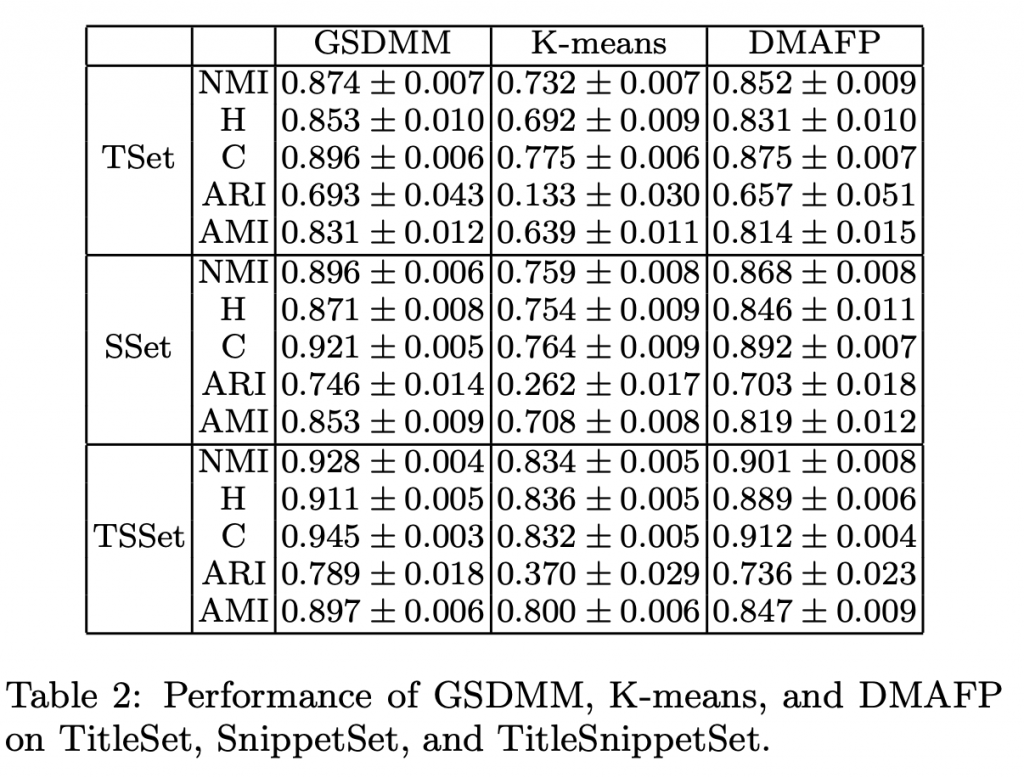
Google News
全方位的優於現有方法。
GSDMM 在長文本表現更佳
但在短文本也勝過 KMeans 用長文本。
足見其短文分群的實力。
模型分析
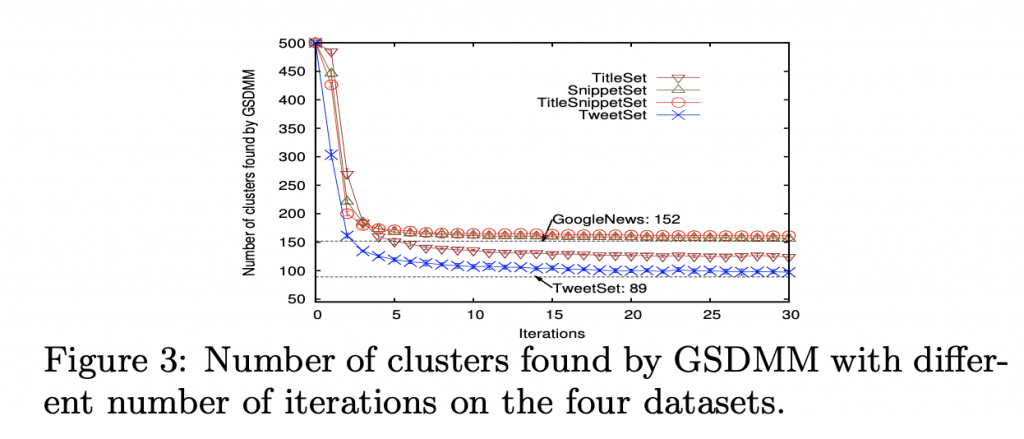
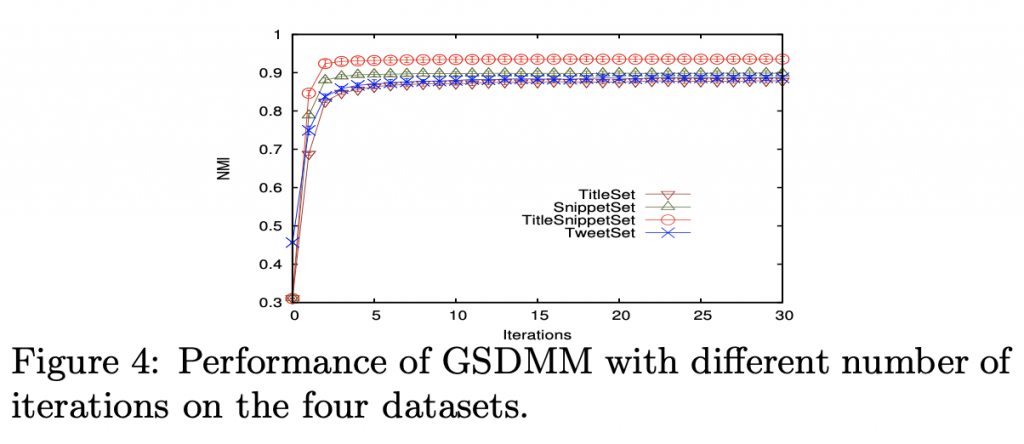
回合數的影響
對於群數:收斂極快,十個回合左右就穩定。
對於效能:以 NMI為例,兩個回合就穩定。
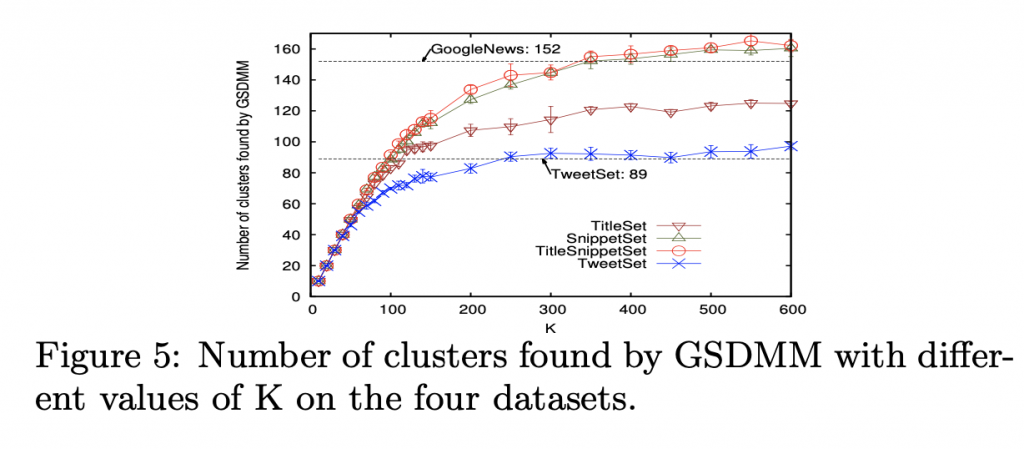
初始群數 K 的影響
每個實驗就跑十回合。
GSDMM 有能力找到接近真實分群的群數。
TitleSet 找不到可能是內含的文字太少了。
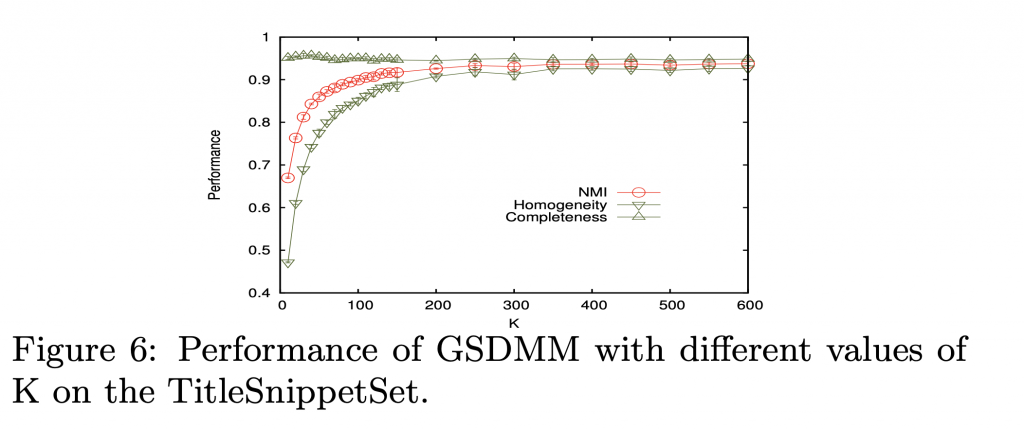
GSDMM 在群數過大的時候,仍能正確的分群,維持了良好的 completeness 和 homogeneity。
故可以放心的設定較大的 K 。
這要歸功於兩個原則的平衡。
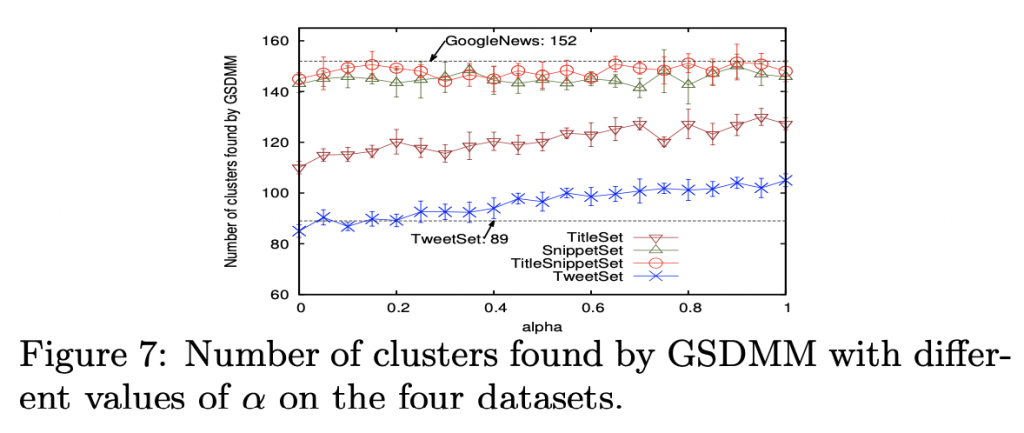
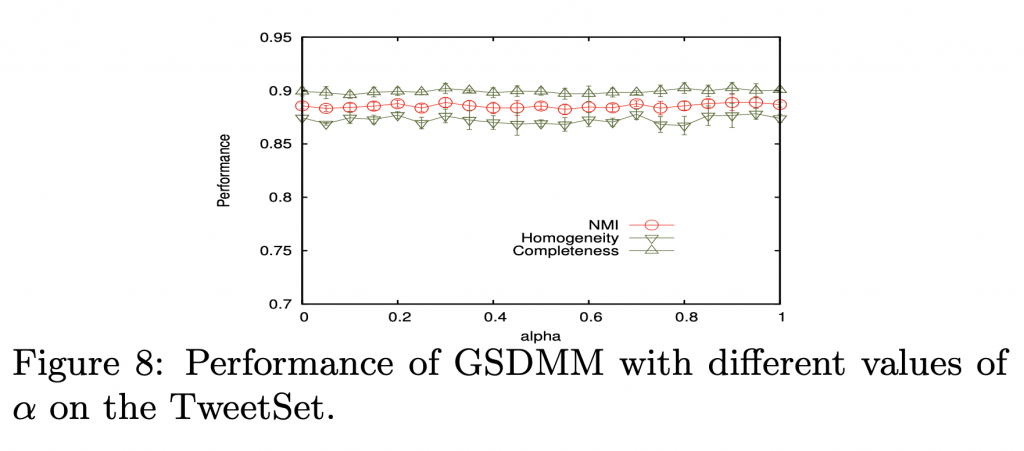
alpha 的影響
固定 beta = 0.1 ,初始 K = 300 , 跑十個回合。
概念:當 alpha 為零的時候,每篇文章絕對不會去選擇空的群。
可以看到在 tweetset 和 titleset 上面的表現,在 alpha 變大的時候,越來越多群出現,這是因為隨著 alpha 上升,選擇空群的機率上升。
但 snippestset 和 titlesnippetset 就沒有這個情形,基本上很穩定,因為他們的文章長度較長,在這種情況下,根據公式,另外一條規則會主導。
Alpha 對效能的影響甚微。
照理說移除 alpha 有助於提升速度。
但是在公式中,alpha 為零不能成立,畢竟 alpha 是 Dirichlet distribution 的參數。
應該有另一個公式,留作未來探索。
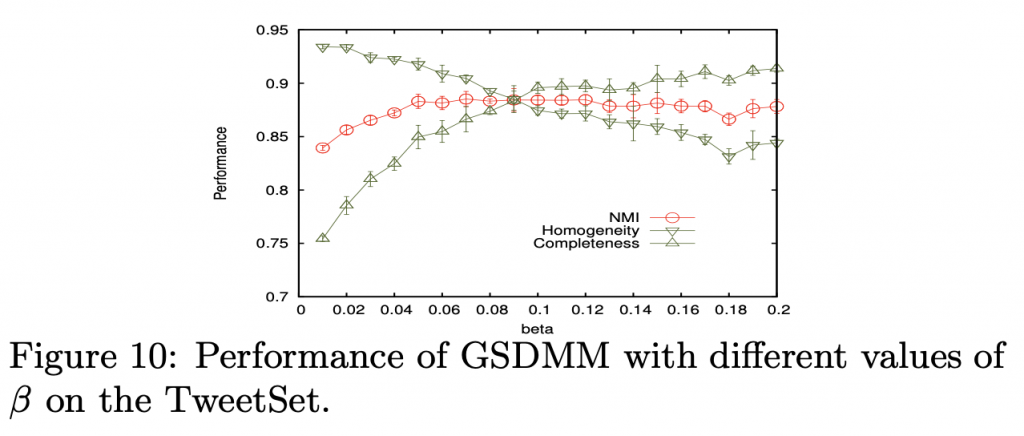
beta 的影響
概念:當 beta 比較小的時候,文章較有可能被分到較相似的群。
所以我們可以看到當 beta 越小,分出來的群就越多。
我們可以看到上面,兩個指標隨著 beta 的變化。
當文章越去找與自己相近的群的的時候,homogeneity就會比較高,但因為群太多導致 completeness 下降。
可擴展性
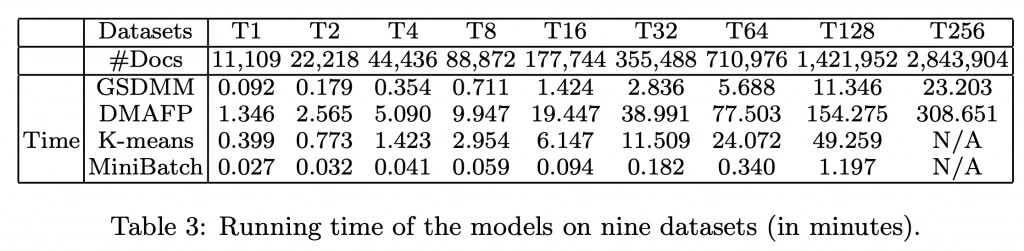
作者把資料集複製好幾次,看看不同的資料集各演算法所需的時間差異為何。
可以看到在資料集複製成 256 倍的大小時,約284萬篇文章的時候,GSDMM 的算法大概只要花半個小時,其他的算法都已經遠遠超過了。
由此可證明此方法是可擴展的。
Thoughts
好一篇分析完整的文章。
能夠自動找到群數還蠻吸引人的。
參數不複雜,容易理解,調參數應該不會太痛苦。
留言
追蹤
檢舉
上一篇
[D9] GSDMM (Yin and Wang, 2014) 1/2
下一篇
[D11] Dynamic topic models (Blei and Lafferty, 2006) 1/2
系列文
今晚,我想來點經典NLP論文。
共
17
篇
目錄
RSS系列文
訂閱系列文
1
人訂閱
13
[D13] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014) 1/2
14
[D14] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014)
15
[D15] Weakly Supervised User Profile Extraction from Twitter (2014) 2/2
16
[D16] Emotion Intensities in Tweets (2017) 1/2
17
[D17] Emotion Intensities in Tweets (2017) 2/2
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
102
組
團體組數
3
組
累計文章數
155
篇
最後報名日
9/15
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
ChatGPT Business & Codex 如何從零開始?
關於LSTM 做IDS分類資料集處裡
CODEX 桌面版本app重啟後分頁老是消失 (為什麼)
熱門回答
ChatGPT Business & Codex 如何從零開始?
熱門文章
Day 01 - Claude Code 其實就只是一個 while 迴圈
Day1: 為什麼現在是不寫程式的測試人員學自動化的最好時機
2026 年網站設計新工具,CrocoBuilder 原生 AI 的 WordPress 網頁編輯器
【AI Agent 架構】Agent 不是越複雜越好:哪些機制該留,哪些可以拿掉?
Agent 產生的 UI 能顯示,不代表它已經可以上線
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}


 iThome鐵人賽
iThome鐵人賽